Table of Contents
- 5.1 The MySQL Server
- 5.1.1 Configuring the Server
- 5.1.2 Server Configuration Defaults
- 5.1.3 Server Configuration Validation
- 5.1.4 Server Option, System Variable, and Status Variable Reference
- 5.1.5 Server System Variable Reference
- 5.1.6 Server Status Variable Reference
- 5.1.7 Server Command Options
- 5.1.8 Server System Variables
- 5.1.9 Using System Variables
- 5.1.10 Server Status Variables
- 5.1.11 Server SQL Modes
- 5.1.12 Connection Management
- 5.1.13 IPv6 Support
- 5.1.14 Network Namespace Support
- 5.1.15 MySQL Server Time Zone Support
- 5.1.16 Resource Groups
- 5.1.17 Server-Side Help Support
- 5.1.18 Server Tracking of Client Session State Changes
- 5.1.19 The Server Shutdown Process
- 5.2 The MySQL Data Directory
- 5.3 The mysql System Schema
- 5.4 MySQL Server Logs
- 5.5 MySQL Components
- 5.6 MySQL Server Plugins
- 5.7 MySQL Server User-Defined Functions
- 5.8 Running Multiple MySQL Instances on One Machine
- 5.9 Debugging MySQL
MySQL Server (mysqld) is the main program that does most of the work in a MySQL installation. This chapter provides an overview of MySQL Server and covers general server administration:
Server configuration
The data directory, particularly the
mysqlsystem schemaThe server log files
Management of multiple servers on a single machine
For additional information on administrative topics, see also:
- 5.1.1 Configuring the Server
- 5.1.2 Server Configuration Defaults
- 5.1.3 Server Configuration Validation
- 5.1.4 Server Option, System Variable, and Status Variable Reference
- 5.1.5 Server System Variable Reference
- 5.1.6 Server Status Variable Reference
- 5.1.7 Server Command Options
- 5.1.8 Server System Variables
- 5.1.9 Using System Variables
- 5.1.10 Server Status Variables
- 5.1.11 Server SQL Modes
- 5.1.12 Connection Management
- 5.1.13 IPv6 Support
- 5.1.14 Network Namespace Support
- 5.1.15 MySQL Server Time Zone Support
- 5.1.16 Resource Groups
- 5.1.17 Server-Side Help Support
- 5.1.18 Server Tracking of Client Session State Changes
- 5.1.19 The Server Shutdown Process
mysqld is the MySQL server. The following discussion covers these MySQL server configuration topics:
Startup options that the server supports. You can specify these options on the command line, through configuration files, or both.
Server system variables. These variables reflect the current state and values of the startup options, some of which can be modified while the server is running.
Server status variables. These variables contain counters and statistics about runtime operation.
How to set the server SQL mode. This setting modifies certain aspects of SQL syntax and semantics, for example for compatibility with code from other database systems, or to control the error handling for particular situations.
How the server manages client connections.
Configuring and using IPv6 and network namespace support.
Configuring and using time zone support.
Using resource groups.
Server-side help capabilities.
Capabilities provided to enable client session state changes.
The server shutdown process. There are performance and reliability considerations depending on the type of table (transactional or nontransactional) and whether you use replication.
For listings of MySQL server variables and options that have been added, deprecated, or removed in MySQL 8.0, see Section 1.4, “Server and Status Variables and Options Added, Deprecated, or Removed in MySQL 8.0”.
Not all storage engines are supported by all MySQL server binaries and configurations. To find out how to determine which storage engines your MySQL server installation supports, see Section 13.7.7.16, “SHOW ENGINES Statement”.
The MySQL server, mysqld, has many command options and system variables that can be set at startup to configure its operation. To determine the default command option and system variable values used by the server, execute this command:
shell> mysqld --verbose --help
The command produces a list of all mysqld options and configurable system variables. Its output includes the default option and variable values and looks something like this:
abort-slave-event-count 0 allow-suspicious-udfs FALSE archive ON auto-increment-increment 1 auto-increment-offset 1 autocommit TRUE automatic-sp-privileges TRUE avoid-temporal-upgrade FALSE back-log 80 basedir /home/jon/bin/mysql-8.0/ ... tmpdir /tmp transaction-alloc-block-size 8192 transaction-isolation REPEATABLE-READ transaction-prealloc-size 4096 transaction-read-only FALSE transaction-write-set-extraction OFF updatable-views-with-limit YES validate-user-plugins TRUE verbose TRUE wait-timeout 28800
To see the current system variable values actually used by the server as it runs, connect to it and execute this statement:
mysql> SHOW VARIABLES;
To see some statistical and status indicators for a running server, execute this statement:
mysql> SHOW STATUS;
System variable and status information also is available using the mysqladmin command:
shell>mysqladmin variablesshell>mysqladmin extended-status
For a full description of all command options, system variables, and status variables, see these sections:
More detailed monitoring information is available from the
Performance Schema; see Chapter 27, MySQL Performance Schema. In
addition, the MySQL sys schema is a set of
objects that provides convenient access to data collected by the
Performance Schema; see Chapter 28, MySQL sys Schema.
If you specify an option on the command line for mysqld or mysqld_safe, it remains in effect only for that invocation of the server. To use the option every time the server runs, put it in an option file. See Section 4.2.2.2, “Using Option Files”.
The MySQL server has many operating parameters, which you can change at server startup using command-line options or configuration files (option files). It is also possible to change many parameters at runtime. For general instructions on setting parameters at startup or runtime, see Section 5.1.7, “Server Command Options”, and Section 5.1.8, “Server System Variables”.
On Windows, MySQL Installer interacts with the user and creates a
file named my.ini in the base installation
directory as the default option file.
On Windows, the .ini or
.cnf option file extension might not be
displayed.
After completing the installation process, you can edit the
default option file at any time to modify the parameters used by
the server. For example, to use a parameter setting in the file
that is commented with a # character at the
beginning of the line, remove the #, and modify
the parameter value if necessary. To disable a setting, either add
a # to the beginning of the line or remove it.
For non-Windows platforms, no default option file is created during either the server installation or the data directory initialization process. Create your option file by following the instructions given in Section 4.2.2.2, “Using Option Files”. Without an option file, the server just starts with its default settings—see Section 5.1.2, “Server Configuration Defaults” on how to check those settings.
For additional information about option file format and syntax, see Section 4.2.2.2, “Using Option Files”.
As of MySQL 8.0.16, MySQL Server supports a
--validate-config option that
enables the startup configuration to be checked for problems
without running the server in normal operational mode:
mysqld --validate-config
If no errors are found, the server terminates with an exit code of 0. If an error is found, the server displays a diagnostic message and terminates with an exit code of 1. For example:
shell> mysqld --validate-config --no-such-option
2018-11-05T17:50:12.738919Z 0 [ERROR] [MY-000068] [Server] unknown
option '--no-such-option'.
2018-11-05T17:50:12.738962Z 0 [ERROR] [MY-010119] [Server] Aborting
The server terminates as soon as any error is found. For
additional checks to occur, correct the initial problem and run
the server with --validate-config
again.
For the preceding example, where use of
--validate-config results in
display of an error message, the server exit code is 1. Warning
and information messages may also be displayed, depending on the
log_error_verbosity value, but do
not produce immediate validation termination or an exit code of 1.
For example, this command produces multiple warnings, both of
which are displayed. But no error occurs, so the exit code is 0:
shell>mysqld --validate-config --log_error_verbosity=2--read-only=s --transaction_read_only=s2018-11-05T15:43:18.445863Z 0 [Warning] [MY-000076] [Server] option 'read_only': boolean value 's' was not recognized. Set to OFF. 2018-11-05T15:43:18.445882Z 0 [Warning] [MY-000076] [Server] option 'transaction-read-only': boolean value 's' was not recognized. Set to OFF.
This command produces the same warnings, but also an error, so the error message is displayed along with the warnings and the exit code is 1:
shell>mysqld --validate-config --log_error_verbosity=2--no-such-option --read-only=s --transaction_read_only=s2018-11-05T15:43:53.152886Z 0 [Warning] [MY-000076] [Server] option 'read_only': boolean value 's' was not recognized. Set to OFF. 2018-11-05T15:43:53.152913Z 0 [Warning] [MY-000076] [Server] option 'transaction-read-only': boolean value 's' was not recognized. Set to OFF. 2018-11-05T15:43:53.164889Z 0 [ERROR] [MY-000068] [Server] unknown option '--no-such-option'. 2018-11-05T15:43:53.165053Z 0 [ERROR] [MY-010119] [Server] Aborting
The scope of the --validate-config
option is limited to configuration checking that the server can
perform without undergoing its normal startup process. As such,
the configuration check does not initialize storage engines and
other plugins, components, and so forth, and does not validate
options associated with those uninitialized subsystems.
--validate-config can be used any
time, but is particularly useful after an upgrade, to check
whether any options previously used with the older server are
considered by the upgraded server to be deprecated or obsolete.
For example, the tx_read_only system variable
was deprecated in MySQL 5.7 and removed in 8.0. Suppose that a
MySQL 5.7 server was run using that system variable in its
my.cnf file and then upgraded to MySQL 8.0.
Running the upgraded server with
--validate-config to check the
configuration produces this result:
shell> mysqld --validate-config
2018-11-05T10:40:02.712141Z 0 [ERROR] [MY-000067] [Server] unknown variable
'tx_read_only=ON'.
2018-11-05T10:40:02.712178Z 0 [ERROR] [MY-010119] [Server] Aborting
--validate-config can be used with
the --defaults-file option to
validate only the options in a specific file:
shell> mysqld --defaults-file=./my.cnf-test --validate-config
2018-11-05T10:40:02.712141Z 0 [ERROR] [MY-000067] [Server] unknown variable
'tx_read_only=ON'.
2018-11-05T10:40:02.712178Z 0 [ERROR] [MY-010119] [Server] Aborting
Remember that --defaults-file, if
specified, must be the first option on the command line.
(Executing the preceding example with the option order reversed
produces a message that
--defaults-file itself is
unknown.)
The following table lists all command-line options, system
variables, and status variables applicable within
mysqld.
The table lists command-line options (Cmd-line), options valid in configuration files (Option file), server system variables (System Var), and status variables (Status var) in one unified list, with an indication of where each option or variable is valid. If a server option set on the command line or in an option file differs from the name of the corresponding system variable, the variable name is noted immediately below the corresponding option. For system and status variables, the scope of the variable (Var Scope) is Global, Session, or both. Please see the corresponding item descriptions for details on setting and using the options and variables. Where appropriate, direct links to further information about the items are provided.
For a version of this table that is specific to NDB Cluster, see Section 23.3.2.5, “NDB Cluster mysqld Option and Variable Reference”.
Table 5.1 Command-Line Option, System Variable, and Status Variable Summary
Notes:
1. This option is dynamic, but should be set only by server. You should not set this variable manually.
The following table lists all system variables applicable within
mysqld.
The table lists command-line options (Cmd-line), options valid in configuration files (Option file), server system variables (System Var), and status variables (Status var) in one unified list, with an indication of where each option or variable is valid. If a server option set on the command line or in an option file differs from the name of the corresponding system variable, the variable name is noted immediately below the corresponding option. The scope of the variable (Var Scope) is Global, Session, or both. Please see the corresponding item descriptions for details on setting and using the variables. Where appropriate, direct links to further information about the items are provided.
Table 5.2 System Variable Summary
Notes:
1. This option is dynamic, but should be set only by server. You should not set this variable manually.
The following table lists all status variables applicable within
mysqld.
The table lists each variable's data type and scope. The last column indicates whether the scope for each variable is Global, Session, or both. Please see the corresponding item descriptions for details on setting and using the variables. Where appropriate, direct links to further information about the items are provided.
Table 5.3 Status Variable Summary
When you start the mysqld server, you can specify program options using any of the methods described in Section 4.2.2, “Specifying Program Options”. The most common methods are to provide options in an option file or on the command line. However, in most cases it is desirable to make sure that the server uses the same options each time it runs. The best way to ensure this is to list them in an option file. See Section 4.2.2.2, “Using Option Files”. That section also describes option file format and syntax.
mysqld reads options from the
[mysqld] and [server]
groups. mysqld_safe reads options from the
[mysqld], [server],
[mysqld_safe], and
[safe_mysqld] groups.
mysql.server reads options from the
[mysqld] and [mysql.server]
groups.
mysqld accepts many command options. For a brief summary, execute this command:
mysqld --help
To see the full list, use this command:
mysqld --verbose --help
Some of the items in the list are actually system variables that
can be set at server startup. These can be displayed at runtime
using the SHOW VARIABLES statement.
Some items displayed by the preceding mysqld
command do not appear in SHOW
VARIABLES output; this is because they are options only
and not system variables.
The following list shows some of the most common server options. Additional options are described in other sections:
Options that affect security: See Section 6.1.4, “Security-Related mysqld Options and Variables”.
SSL-related options: See Command Options for Encrypted Connections.
Binary log control options: See Section 5.4.4, “The Binary Log”.
Replication-related options: See Section 17.1.6, “Replication and Binary Logging Options and Variables”.
Options for loading plugins such as pluggable storage engines: See Section 5.6.1, “Installing and Uninstalling Plugins”.
Options specific to particular storage engines: See Section 15.14, “InnoDB Startup Options and System Variables” and Section 16.2.1, “MyISAM Startup Options”.
Some options control the size of buffers or caches. For a given buffer, the server might need to allocate internal data structures. These structures typically are allocated from the total memory allocated to the buffer, and the amount of space required might be platform dependent. This means that when you assign a value to an option that controls a buffer size, the amount of space actually available might differ from the value assigned. In some cases, the amount might be less than the value assigned. It is also possible that the server adjusts a value upward. For example, if you assign a value of 0 to an option for which the minimal value is 1024, the server sets the value to 1024.
Values for buffer sizes, lengths, and stack sizes are given in bytes unless otherwise specified.
Some options take file name values. Unless otherwise specified,
the default file location is the data directory if the value is a
relative path name. To specify the location explicitly, use an
absolute path name. Suppose that the data directory is
/var/mysql/data. If a file-valued option is
given as a relative path name, it is located under
/var/mysql/data. If the value is an absolute
path name, its location is as given by the path name.
You can also set the values of server system variables at server
startup by using variable names as options. To assign a value to a
server system variable, use an option of the form
--.
For example,
var_name=value--sort_buffer_size=384M sets the
sort_buffer_size variable to a
value of 384MB.
When you assign a value to a variable, MySQL might automatically correct the value to stay within a given range, or adjust the value to the closest permissible value if only certain values are permitted.
To restrict the maximum value to which a system variable can be
set at runtime with the
SET
statement, specify this maximum by using an option of the form
--maximum-
at server startup.
var_name=value
You can change the values of most system variables at runtime with
the SET
statement. See Section 13.7.6.1, “SET Syntax for Variable Assignment”.
Section 5.1.8, “Server System Variables”, provides a full description for all variables, and additional information for setting them at server startup and runtime. For information on changing system variables, see Section 5.1.1, “Configuring the Server”.
--help,-?Command-Line Format --helpDisplay a short help message and exit. Use both the
--verboseand--helpoptions to see the full message.-
Command-Line Format --admin-ssl[={OFF|ON}]Introduced 8.0.21 Type Boolean Default Value ONThe
--admin-ssloption is like the--ssloption, except that it applies to the administrative connection interface rather than the main connection interface. For information about these interfaces, see Section 5.1.12.1, “Connection Interfaces”.The
--admin-ssloption specifies that the server permits but does not require encrypted connections on the administrative interface. This option is enabled by default.--admin-sslcan be specified in negated form as--skip-admin-sslor a synonym (--admin-ssl=OFF,--disable-admin-ssl). In this case, the option specifies that the server does not permit encrypted connections, regardless of the settings of theadmin_tsl_andxxxadmin_ssl_system variables.xxxThe
--admin-ssloption has an effect only at server startup on whether the administrative interface supports encrypted connections. It is ignored and has no effect on the operation ofALTER INSTANCE RELOAD TLSat runtime. For example, you can use--admin-ssl=OFFto start the administrative interface with encrypted connections disabled, then reconfigure TLS and executeALTER INSTANCE RELOAD TLS FOR CHANNEL mysql_adminto enable encrypted connections at runtime.For general information about configuring connection-encryption support, see Section 6.3.1, “Configuring MySQL to Use Encrypted Connections”. That discussion is written for the main connection interface, but the parameter names are similar for the administrative connection interface. Consider setting at least the
admin_ssl_certandadmin_ssl_keysystem variables on the server side and the--ssl-ca(or--ssl-capath) option on the client side. For additional information specifically about the administrative interface, see Administrative Interface Support for Encrypted Connections. -
Command-Line Format --allow-suspicious-udfs[={OFF|ON}]Type Boolean Default Value OFFThis option controls whether user-defined functions that have only an
xxxsymbol for the main function can be loaded. By default, the option is off and only UDFs that have at least one auxiliary symbol can be loaded; this prevents attempts at loading functions from shared object files other than those containing legitimate UDFs. See UDF Security Precautions. -
Command-Line Format --ansiUse standard (ANSI) SQL syntax instead of MySQL syntax. For more precise control over the server SQL mode, use the
--sql-modeoption instead. See Section 1.7, “MySQL Standards Compliance”, and Section 5.1.11, “Server SQL Modes”. --basedir=,dir_name-bdir_nameCommand-Line Format --basedir=dir_nameSystem Variable basedirScope Global Dynamic No SET_VARHint AppliesNo Type Directory name Default Value parent of mysqld installation directoryThe path to the MySQL installation directory. This option sets the
basedirsystem variable.The server executable determines its own full path name at startup and uses the parent of the directory in which it is located as the default
basedirvalue. This in turn enables the server to use thatbasedirwhen searching for server-related information such as thesharedirectory containing error messages.--character-set-client-handshakeCommand-Line Format --character-set-client-handshake[={OFF|ON}]Type Boolean Default Value ONDo not ignore character set information sent by the client. To ignore client information and use the default server character set, use
--skip-character-set-client-handshake; this makes MySQL behave like MySQL 4.0.--chroot=,dir_name-rdir_nameCommand-Line Format --chroot=dir_nameType Directory name Put the mysqld server in a closed environment during startup by using the
chroot()system call. This is a recommended security measure. Use of this option somewhat limitsLOAD DATAandSELECT ... INTO OUTFILE.-
Command-Line Format --consolePlatform Specific Windows (Windows only.) Cause the default error log destination to be the console. This affects log sinks that base their own output destination on the default destination. See Section 5.4.2, “The Error Log”. mysqld does not close the console window if this option is used.
--consoletakes precedence over--log-errorif both are given. -
Command-Line Format --core-file[={OFF|ON}]Type Boolean Default Value OFFWrite a core file if mysqld dies. The name and location of the core file is system dependent. On Linux, a core file named
core.is written to the current working directory of the process, which for mysqld is the data directory.pidpidrepresents the process ID of the server process. On macOS, a core file namedcore.is written to thepid/coresdirectory. On Solaris, use the coreadm command to specify where to write the core file and how to name it.For some systems, to get a core file you must also specify the
--core-file-sizeoption to mysqld_safe. See Section 4.3.2, “mysqld_safe — MySQL Server Startup Script”. On some systems, such as Solaris, you do not get a core file if you are also using the--useroption. There might be additional restrictions or limitations. For example, it might be necessary to execute ulimit -c unlimited before starting the server. Consult your system documentation.The
innodb_buffer_pool_in_core_filevariable can be used to reduce the size of core files on operating systems that support it. For more information, see Section 15.8.3.7, “Excluding Buffer Pool Pages from Core Files”. --daemonize,-DCommand-Line Format --daemonize[={OFF|ON}]Type Boolean Default Value OFFThis option causes the server to run as a traditional, forking daemon, permitting it to work with operating systems that use systemd for process control. For more information, see Section 2.5.9, “Managing MySQL Server with systemd”.
--daemonizeis mutually exclusive with--initializeand--initialize-insecure.If the server is started using the
--daemonizeoption and is not connected to a tty device, a default error logging option of--log-error=""is used in the absence of an explicit logging option, to direct error output to the default log file.-Dis a synonym for--daemonize.--datadir=,dir_name-hdir_nameCommand-Line Format --datadir=dir_nameSystem Variable datadirScope Global Dynamic No SET_VARHint AppliesNo Type Directory name The path to the MySQL server data directory. This option sets the
datadirsystem variable. See the description of that variable.--debug[=,debug_options]-# [debug_options]Command-Line Format --debug[=debug_options]System Variable debugScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String Default Value (Windows) d:t:i:O,\mysqld.traceDefault Value (Unix) d:t:i:o,/tmp/mysqld.traceIf MySQL is configured with the
-DWITH_DEBUG=1CMake option, you can use this option to get a trace file of what mysqld is doing. A typicaldebug_optionsstring isd:t:o,. The default isfile_named:t:i:o,/tmp/mysqld.traceon Unix andd:t:i:O,\mysqld.traceon Windows.Using
-DWITH_DEBUG=1to configure MySQL with debugging support enables you to use the--debug="d,parser_debug"option when you start the server. This causes the Bison parser that is used to process SQL statements to dump a parser trace to the server's standard error output. Typically, this output is written to the error log.This option may be given multiple times. Values that begin with
+or-are added to or subtracted from the previous value. For example,--debug=T--debug=+Psets the value toP:T.For more information, see Section 5.9.4, “The DBUG Package”.
-
Command-Line Format --debug-sync-timeout[=#]Type Integer Controls whether the Debug Sync facility for testing and debugging is enabled. Use of Debug Sync requires that MySQL be configured with the
-DENABLE_DEBUG_SYNC=1CMake option (see Section 2.9.7, “MySQL Source-Configuration Options”). If Debug Sync is not compiled in, this option is not available. The option value is a timeout in seconds. The default value is 0, which disables Debug Sync. To enable it, specify a value greater than 0; this value also becomes the default timeout for individual synchronization points. If the option is given without a value, the timeout is set to 300 seconds.For a description of the Debug Sync facility and how to use synchronization points, see MySQL Internals: Test Synchronization.
-
Command-Line Format --default-time-zone=nameType String Set the default server time zone. This option sets the global
time_zonesystem variable. If this option is not given, the default time zone is the same as the system time zone (given by the value of thesystem_time_zonesystem variable. --defaults-extra-file=file_nameRead this option file after the global option file but (on Unix) before the user option file. If the file does not exist or is otherwise inaccessible, an error occurs.
file_nameis interpreted relative to the current directory if given as a relative path name rather than a full path name. This must be the first option on the command line if it is used.For additional information about this and other option-file options, see Section 4.2.2.3, “Command-Line Options that Affect Option-File Handling”.
Read only the given option file. If the file does not exist or is otherwise inaccessible, an error occurs.
file_nameis interpreted relative to the current directory if given as a relative path name rather than a full path name.Exception: Even with
--defaults-file, mysqld readsmysqld-auto.cnf.NoteThis must be the first option on the command line if it is used, except that if the server is started with the
--defaults-fileand--install(or--install-manual) options,--install(or--install-manual) must be first.For additional information about this and other option-file options, see Section 4.2.2.3, “Command-Line Options that Affect Option-File Handling”.
Read not only the usual option groups, but also groups with the usual names and a suffix of
str. For example, mysqld normally reads the[mysqld]group. If the--defaults-group-suffix=_otheroption is given, mysqld also reads the[mysqld_other]group.For additional information about this and other option-file options, see Section 4.2.2.3, “Command-Line Options that Affect Option-File Handling”.
--early-plugin-load=plugin_listCommand-Line Format --early-plugin-load=plugin_listType String Default Value empty stringThis option tells the server which plugins to load before loading mandatory built-in plugins and before storage engine initialization. If multiple
--early-plugin-loadoptions are given, only the last one is used.The option value is a semicolon-separated list of
name=plugin_libraryandplugin_libraryvalues. Eachnameis the name of a plugin to load, andplugin_libraryis the name of the library file that contains the plugin code. If a plugin library is named without any preceding plugin name, the server loads all plugins in the library. The server looks for plugin library files in the directory named by theplugin_dirsystem variable.For example, if plugins named
myplug1andmyplug2have library filesmyplug1.soandmyplug2.so, use this option to perform an early plugin load:shell>
mysqld --early-plugin-load="myplug1=myplug1.so;myplug2=myplug2.so"Quotes are used around the argument value because otherwise a semicolon (
;) is interpreted as a special character by some command interpreters. (Unix shells treat it as a command terminator, for example.)Each named plugin is loaded early for a single invocation of mysqld only. After a restart, the plugin is not loaded early unless
--early-plugin-loadis used again.If the server is started using
--initializeor--initialize-insecure, plugins specified by--early-plugin-loadare not loaded.If the server is run with
--help, plugins specified by--early-plugin-loadare loaded but not initialized. This behavior ensures that plugin options are displayed in the help message.The default
--early-plugin-loadvalue is empty. To load thekeyring_fileplugin, you must use an explicit--early-plugin-loadoption with a nonempty value.The
InnoDBtablespace encryption feature relies on thekeyring_fileplugin for encryption key management, and thekeyring_fileplugin must be loaded prior to storage engine initialization to facilitateInnoDBrecovery for encrypted tables. Administrators who want thekeyring_fileplugin loaded at startup should use the appropriate nonempty option value (for example,keyring_file.soon Unix and Unix-like systems andkeyring_file.dllon Windows).For information about
InnoDBtablespace encryption, see Section 15.13, “InnoDB Data-at-Rest Encryption”. For general information about plugin loading, see Section 5.6.1, “Installing and Uninstalling Plugins”.--exit-info[=,flags]-T [flags]Command-Line Format --exit-info[=flags]Type Integer This is a bitmask of different flags that you can use for debugging the mysqld server. Do not use this option unless you know exactly what it does!
-
Command-Line Format --external-locking[={OFF|ON}]Type Boolean Default Value OFFEnable external locking (system locking), which is disabled by default. If you use this option on a system on which
lockddoes not fully work (such as Linux), it is easy for mysqld to deadlock.To disable external locking explicitly, use
--skip-external-locking.External locking affects only
MyISAMtable access. For more information, including conditions under which it can and cannot be used, see Section 8.11.5, “External Locking”. -
Command-Line Format --flush[={OFF|ON}]System Variable flushScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFFlush (synchronize) all changes to disk after each SQL statement. Normally, MySQL does a write of all changes to disk only after each SQL statement and lets the operating system handle the synchronizing to disk. See Section B.3.3.3, “What to Do If MySQL Keeps Crashing”.
NoteIf
--flushis specified, the value offlush_timedoes not matter and changes toflush_timehave no effect on flush behavior. -
Command-Line Format --gdb[={OFF|ON}]Type Boolean Default Value OFFInstall an interrupt handler for
SIGINT(needed to stop mysqld with^Cto set breakpoints) and disable stack tracing and core file handling. See Section 5.9.1.4, “Debugging mysqld under gdb”.On Windows, this option also suppresses the forking that is used to implement the
RESTARTstatement: Forking enables one process to act as a monitor to the other, which acts as the server. However, forking makes determining the server process to attach to for debugging more difficult, so starting the server with--gdbsuppresses forking. For a server started with this option,RESTARTsimply exits and does not restart.In non-debug settings,
--no-monitormay be used to suppress forking the monitor process. --initialize,-ICommand-Line Format --initialize[={OFF|ON}]Type Boolean Default Value OFFThis option is used to initialize a MySQL installation by creating the data directory and populating the tables in the
mysqlsystem schema. For more information, see Section 2.10.1, “Initializing the Data Directory”.When the server is started with
--initialize, some functionality is unavailable that limits the statements permitted in any file named by theinit_filesystem variable. For more information, see the description of that variable. In addition, thedisabled_storage_enginessystem variable has no effect.The
--ndbclusteroption is ignored when used together with--initialize.--initializeis mutually exclusive with--daemonize.-Iis a synonym for--initialize.-
Command-Line Format --initialize-insecure[={OFF|ON}]Type Boolean Default Value OFFThis option is used to initialize a MySQL installation by creating the data directory and populating the tables in the
mysqlsystem schema. This option implies--initialize. For more information, see the description of that option, and Section 2.10.1, “Initializing the Data Directory”.--initialize-insecureis mutually exclusive with--daemonize. --innodb-xxxSet an option for the
InnoDBstorage engine. TheInnoDBoptions are listed in Section 15.14, “InnoDB Startup Options and System Variables”.-
Command-Line Format --install [service_name]Platform Specific Windows (Windows only) Install the server as a Windows service that starts automatically during Windows startup. The default service name is
MySQLif noservice_namevalue is given. For more information, see Section 2.3.4.8, “Starting MySQL as a Windows Service”.NoteIf the server is started with the
--defaults-fileand--installoptions,--installmust be first. --install-manual [service_name]Command-Line Format --install-manual [service_name]Platform Specific Windows (Windows only) Install the server as a Windows service that must be started manually. It does not start automatically during Windows startup. The default service name is
MySQLif noservice_namevalue is given. For more information, see Section 2.3.4.8, “Starting MySQL as a Windows Service”.NoteIf the server is started with the
--defaults-fileand--install-manualoptions,--install-manualmust be first.--language=lang_name, -Llang_nameCommand-Line Format --language=nameDeprecated Yes; use lc-messages-dirinsteadSystem Variable languageScope Global Dynamic No SET_VARHint AppliesNo Type Directory name Default Value /usr/local/mysql/share/mysql/english/The language to use for error messages.
lang_namecan be given as the language name or as the full path name to the directory where the language files are installed. See Section 10.12, “Setting the Error Message Language”.--lc-messages-dirand--lc-messagesshould be used rather than--language, which is deprecated (and handled as a synonym for--lc-messages-dir). You should expect the--languageoption to be removed in a future MySQL release.-
Command-Line Format --large-pages[={OFF|ON}]System Variable large_pagesScope Global Dynamic No SET_VARHint AppliesNo Platform Specific Linux Type Boolean Default Value OFFSome hardware/operating system architectures support memory pages greater than the default (usually 4KB). The actual implementation of this support depends on the underlying hardware and operating system. Applications that perform a lot of memory accesses may obtain performance improvements by using large pages due to reduced Translation Lookaside Buffer (TLB) misses.
MySQL supports the Linux implementation of large page support (which is called HugeTLB in Linux). See Section 8.12.3.2, “Enabling Large Page Support”. For Solaris support of large pages, see the description of the
--super-large-pagesoption.--large-pagesis disabled by default. -
Command-Line Format --lc-messages=nameSystem Variable lc_messagesScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String Default Value en_USThe locale to use for error messages. The default is
en_US. The server converts the argument to a language name and combines it with the value of--lc-messages-dirto produce the location for the error message file. See Section 10.12, “Setting the Error Message Language”. -
Command-Line Format --lc-messages-dir=dir_nameSystem Variable lc_messages_dirScope Global Dynamic No SET_VARHint AppliesNo Type Directory name The directory where error messages are located. The server uses the value together with the value of
--lc-messagesto produce the location for the error message file. See Section 10.12, “Setting the Error Message Language”. -
Command-Line Format --local-service(Windows only) A
--local-serviceoption following the service name causes the server to run using theLocalServiceWindows account that has limited system privileges. If both--defaults-fileand--local-serviceare given following the service name, they can be in any order. See Section 2.3.4.8, “Starting MySQL as a Windows Service”. -
Command-Line Format --log-error[=file_name]System Variable log_errorScope Global Dynamic No SET_VARHint AppliesNo Type File name Set the default error log destination to the named file. This affects log sinks that base their own output destination on the default destination. See Section 5.4.2, “The Error Log”.
If the option names no file, the default error log destination on Unix and Unix-like systems is a file named
host_name.err--pid-fileoption is specified. In that case, the file name is the PID file base name with a suffix of.errin the data directory.If the option names a file, the default destination is that file (with an
.errsuffix added if the name has no suffix), located under the data directory unless an absolute path name is given to specify a different location.If error log output cannot be redirected to the error log file, an error occurs and startup fails.
On Windows,
--consoletakes precedence over--log-errorif both are given. In this case, the default error log destination is the console rather than a file. -
Command-Line Format --log-isam[=file_name]Type File name Log all
MyISAMchanges to this file (used only when debuggingMyISAM). -
Command-Line Format --log-raw[={OFF|ON}]System Variable (≥ 8.0.19) log_rawScope (≥ 8.0.19) Global Dynamic (≥ 8.0.19) Yes SET_VARHint Applies (≥ 8.0.19)No Type Boolean Default Value OFFPasswords in certain statements written to the general query log, slow query log, and binary log are rewritten by the server not to occur literally in plain text. Password rewriting can be suppressed for the general query log by starting the server with the
--log-rawoption. This option may be useful for diagnostic purposes, to see the exact text of statements as received by the server, but for security reasons is not recommended for production use.If a query rewrite plugin is installed, the
--log-rawoption affects statement logging as follows:For more information, see Section 6.1.2.3, “Passwords and Logging”.
-
Command-Line Format --log-short-format[={OFF|ON}]Type Boolean Default Value OFFLog less information to the slow query log, if it has been activated.
-
Command-Line Format --log-tc=file_nameType File name Default Value tc.logThe name of the memory-mapped transaction coordinator log file (for XA transactions that affect multiple storage engines when the binary log is disabled). The default name is
tc.log. The file is created under the data directory if not given as a full path name. This option is unused. -
Command-Line Format --log-tc-size=#Type Integer Default Value 6 * page sizeMinimum Value 6 * page sizeMaximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295The size in bytes of the memory-mapped transaction coordinator log. The default and minimum values are 6 times the page size, and the value must be a multiple of the page size.
-
Command-Line Format --memlock[={OFF|ON}]Type Boolean Default Value OFFLock the mysqld process in memory. This option might help if you have a problem where the operating system is causing mysqld to swap to disk.
--memlockworks on systems that support themlockall()system call; this includes Solaris, most Linux distributions that use a 2.4 or higher kernel, and perhaps other Unix systems. On Linux systems, you can tell whether or notmlockall()(and thus this option) is supported by checking to see whether or not it is defined in the systemmman.hfile, like this:shell>
grep mlockall /usr/include/sys/mman.hIf
mlockall()is supported, you should see in the output of the previous command something like the following:extern int mlockall (int __flags) __THROW;
ImportantUse of this option may require you to run the server as
root, which, for reasons of security, is normally not a good idea. See Section 6.1.5, “How to Run MySQL as a Normal User”.On Linux and perhaps other systems, you can avoid the need to run the server as
rootby changing thelimits.conffile. See the notes regarding the memlock limit in Section 8.12.3.2, “Enabling Large Page Support”.You must not use this option on a system that does not support the
mlockall()system call; if you do so, mysqld is very likely to exit as soon as you try to start it. -
Command-Line Format --myisam-block-size=#Type Integer Default Value 1024Minimum Value 1024Maximum Value 16384The block size to be used for
MyISAMindex pages. Do not read any option files. If program startup fails due to reading unknown options from an option file,
--no-defaultscan be used to prevent them from being read. This must be the first option on the command line if it is used.For additional information about this and other option-file options, see Section 4.2.2.3, “Command-Line Options that Affect Option-File Handling”.
-
Command-Line Format --no-dd-upgrade[={OFF|ON}]Deprecated 8.0.16 Type Boolean Default Value OFFNoteThis option is deprecated as of MySQL 8.0.16. It is superseded by the
--upgradeoption, which provides finer control over data dictionary and server upgrade behavior.Prevent automatic upgrade of the data dictionary tables during the MySQL server startup process. This option is typically used when starting the MySQL server following an in-place upgrade of an existing installation to a newer MySQL version, which may include changes to data dictionary table definitions.
When
--no-dd-upgradeis specified, and the server finds that its expected version of the data dictionary differs from the version stored in the data dictionary itself, startup fails with an error stating that data dictionary upgrade is prohibited;[ERROR] [MY-011091] [Server] Data dictionary upgrade prohibited by the command line option '--no_dd_upgrade'. [ERROR] [MY-010020] [Server] Data Dictionary initialization failed.
During a normal startup, the data dictionary version of the server is compared to the version stored in the data dictionary to determine whether data dictionary table definitions should be upgraded. If an upgrade is necessary and supported, the server creates data dictionary tables with updated definitions, copies persisted metadata to the new tables, atomically replaces the old tables with the new ones, and reinitializes the data dictionary. If an upgrade is not necessary, startup continues without updating data dictionary tables.
-
Command-Line Format --no-monitor[={OFF|ON}]Introduced 8.0.12 Platform Specific Windows Type Boolean Default Value OFF(Windows only). This option suppresses the forking that is used to implement the
RESTARTstatement: Forking enables one process to act as a monitor to the other, which acts as the server. For a server started with this option,RESTARTsimply exits and does not restart.--no-monitoris not available prior to MySQL 8.0.12. The--gdboption can be used as a workaround. -
Command-Line Format --old-style-user-limits[={OFF|ON}]Type Boolean Default Value OFFEnable old-style user limits. (Before MySQL 5.0.3, account resource limits were counted separately for each host from which a user connected rather than per account row in the
usertable.) See Section 6.2.20, “Setting Account Resource Limits”. --performance-schema-xxxConfigure a Performance Schema option. For details, see Section 27.14, “Performance Schema Command Options”.
-
Command-Line Format --plugin-load=plugin_listSystem Variable plugin_loadScope Global Dynamic No SET_VARHint AppliesNo Type String This option tells the server to load the named plugins at startup. If multiple
--plugin-loadoptions are given, only the last one is used. Additional plugins to load may be specified using--plugin-load-addoptions.The option value is a semicolon-separated list of
name=plugin_libraryandplugin_libraryvalues. Eachnameis the name of a plugin to load, andplugin_libraryis the name of the library file that contains the plugin code. If a plugin library is named without any preceding plugin name, the server loads all plugins in the library. The server looks for plugin library files in the directory named by theplugin_dirsystem variable.For example, if plugins named
myplug1andmyplug2have library filesmyplug1.soandmyplug2.so, use this option to perform an early plugin load:shell>
mysqld --plugin-load="myplug1=myplug1.so;myplug2=myplug2.so"Quotes are used around the argument value here because otherwise semicolon (
;) is interpreted as a special character by some command interpreters. (Unix shells treat it as a command terminator, for example.)Each named plugin is loaded for a single invocation of mysqld only. After a restart, the plugin is not loaded unless
--plugin-loadis used again. This is in contrast toINSTALL PLUGIN, which adds an entry to themysql.pluginstable to cause the plugin to be loaded for every normal server startup.During the normal startup sequence, the server determines which plugins to load by reading the
mysql.pluginssystem table. If the server is started with the--skip-grant-tablesoption, plugins registered in themysql.pluginstable are not loaded and are unavailable.--plugin-loadenables plugins to be loaded even when--skip-grant-tablesis given.--plugin-loadalso enables plugins to be loaded at startup that cannot be loaded at runtime.For additional information about plugin loading, see Section 5.6.1, “Installing and Uninstalling Plugins”.
-
Command-Line Format --plugin-load-add=plugin_listSystem Variable plugin_load_addScope Global Dynamic No SET_VARHint AppliesNo Type String This option complements the
--plugin-loadoption.--plugin-load-addadds a plugin or plugins to the set of plugins to be loaded at startup. The argument format is the same as for--plugin-load.--plugin-load-addcan be used to avoid specifying a large set of plugins as a single long unwieldy--plugin-loadargument.--plugin-load-addcan be given in the absence of--plugin-load, but any instance of--plugin-load-addthat appears before--plugin-load. has no effect because--plugin-loadresets the set of plugins to load. In other words, these options:--plugin-load=x --plugin-load-add=y
are equivalent to this option:
--plugin-load="x;y"
But these options:
--plugin-load-add=y --plugin-load=x
are equivalent to this option:
--plugin-load=x
For additional information about plugin loading, see Section 5.6.1, “Installing and Uninstalling Plugins”.
Specifies an option that pertains to a server plugin. For example, many storage engines can be built as plugins, and for such engines, options for them can be specified with a
--pluginprefix. Thus, the--innodb-file-per-tableoption forInnoDBcan be specified as--plugin-innodb-file-per-table.For boolean options that can be enabled or disabled, the
--skipprefix and other alternative formats are supported as well (see Section 4.2.2.4, “Program Option Modifiers”). For example,--skip-plugin-innodb-file-per-tabledisablesinnodb-file-per-table.The rationale for the
--pluginprefix is that it enables plugin options to be specified unambiguously if there is a name conflict with a built-in server option. For example, were a plugin writer to name a plugin “sql” and implement a “mode” option, the option name might be--sql-mode, which would conflict with the built-in option of the same name. In such cases, references to the conflicting name are resolved in favor of the built-in option. To avoid the ambiguity, users can specify the plugin option as--plugin-sql-mode. Use of the--pluginprefix for plugin options is recommended to avoid any question of ambiguity.--port=,port_num-Pport_numCommand-Line Format --port=port_numSystem Variable portScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 3306Minimum Value 0Maximum Value 65535The port number to use when listening for TCP/IP connections. On Unix and Unix-like systems, the port number must be 1024 or higher unless the server is started by the
rootoperating system user. Setting this option to 0 causes the default value to be used.-
Command-Line Format --port-open-timeout=#Type Integer Default Value 0On some systems, when the server is stopped, the TCP/IP port might not become available immediately. If the server is restarted quickly afterward, its attempt to reopen the port can fail. This option indicates how many seconds the server should wait for the TCP/IP port to become free if it cannot be opened. The default is not to wait.
Print the program name and all options that it gets from option files. Password values are masked. This must be the first option on the command line if it is used, except that it may be used immediately after
--defaults-fileor--defaults-extra-file.For additional information about this and other option-file options, see Section 4.2.2.3, “Command-Line Options that Affect Option-File Handling”.
-
Command-Line Format --remove [service_name]Platform Specific Windows (Windows only) Remove a MySQL Windows service. The default service name is
MySQLif noservice_namevalue is given. For more information, see Section 2.3.4.8, “Starting MySQL as a Windows Service”. -
Command-Line Format --safe-user-create[={OFF|ON}]Type Boolean Default Value OFFIf this option is enabled, a user cannot create new MySQL users by using the
GRANTstatement unless the user has theINSERTprivilege for themysql.usersystem table or any column in the table. If you want a user to have the ability to create new users that have those privileges that the user has the right to grant, you should grant the user the following privilege:GRANT INSERT(user) ON mysql.user TO '
user_name'@'host_name';This ensures that the user cannot change any privilege columns directly, but has to use the
GRANTstatement to give privileges to other users. -
Command-Line Format --skip-grant-tables[={OFF|ON}]Type Boolean Default Value OFFThis option affects the server startup sequence:
--skip-grant-tablescauses the server not to read the grant tables in themysqlsystem schema, and thus to start without using the privilege system at all. This gives anyone with access to the server unrestricted access to all databases.Because starting the server with
--skip-grant-tablesdisables authentication checks, the server also disables remote connections in that case by enablingskip_networking.To cause a server started with
--skip-grant-tablesto load the grant tables at runtime, perform a privilege-flushing operation, which can be done in these ways:Issue a MySQL
FLUSH PRIVILEGESstatement after connecting to the server.Execute a mysqladmin flush-privileges or mysqladmin reload command from the command line.
Privilege flushing might also occur implicitly as a result of other actions performed after startup, thus causing the server to start using the grant tables. For example, the server flushes the privileges if it performs an upgrade during the startup sequence.
--skip-grant-tablesdisables failed-login tracking and temporary account locking because those capabilities depend on the grant tables. See Section 6.2.15, “Password Management”.--skip-grant-tablescauses the server not to load certain other objects registered in the data dictionary or themysqlsystem schema:Scheduled events installed using
CREATE EVENTand registered in theeventsdata dictionary table.Plugins installed using
INSTALL PLUGINand registered in themysql.pluginsystem table.To cause plugins to be loaded even when using
--skip-grant-tables, use the--plugin-loador--plugin-load-addoption.User-defined functions (UDFs) installed using
CREATE FUNCTIONand registered in themysql.funcsystem table.
--skip-grant-tablesdoes not suppress loading during startup of components.--skip-grant-tablescauses thedisabled_storage_enginessystem variable to have no effect.
-
Command-Line Format --skip-host-cacheDisable use of the internal host cache for faster name-to-IP resolution. With the cache disabled, the server performs a DNS lookup every time a client connects.
Use of
--skip-host-cacheis similar to setting thehost_cache_sizesystem variable to 0, buthost_cache_sizeis more flexible because it can also be used to resize, enable, or disable the host cache at runtime, not just at server startup.Starting the server with
--skip-host-cachedoes not prevent runtime changes to the value ofhost_cache_size, but such changes have no effect and the cache is not re-enabled even ifhost_cache_sizeis set larger than 0.For more information about how the host cache works, see Section 5.1.12.3, “DNS Lookups and the Host Cache”.
Disable the
InnoDBstorage engine. In this case, because the default storage engine isInnoDB, the server does not start unless you also use--default-storage-engineand--default-tmp-storage-engineto set the default to some other engine for both permanent andTEMPORARYtables.The
InnoDBstorage engine cannot be disabled, and the--skip-innodboption is deprecated and has no effect. Its use results in a warning. Expect this option to be removed in a future MySQL release.-
Command-Line Format --skip-newThis option disables (what used to be considered) new, possibly unsafe behaviors. It results in these settings:
delay_key_write=OFF,concurrent_insert=NEVER,automatic_sp_privileges=OFF. It also causesOPTIMIZE TABLEto be mapped toALTER TABLEfor storage engines for whichOPTIMIZE TABLEis not supported. -
Command-Line Format --skip-show-databaseSystem Variable skip_show_databaseScope Global Dynamic No SET_VARHint AppliesNo This option sets the
skip_show_databasesystem variable that controls who is permitted to use theSHOW DATABASESstatement. See Section 5.1.8, “Server System Variables”. -
Command-Line Format --skip-stack-traceDo not write stack traces. This option is useful when you are running mysqld under a debugger. On some systems, you also must use this option to get a core file. See Section 5.9, “Debugging MySQL”.
-
Command-Line Format --slow-start-timeout=#Type Integer Default Value 15000This option controls the Windows service control manager's service start timeout. The value is the maximum number of milliseconds that the service control manager waits before trying to kill the windows service during startup. The default value is 15000 (15 seconds). If the MySQL service takes too long to start, you may need to increase this value. A value of 0 means there is no timeout.
-
Command-Line Format --socket={file_name|pipe_name}System Variable socketScope Global Dynamic No SET_VARHint AppliesNo Type String Default Value (Other) /tmp/mysql.sockDefault Value (Windows) MySQLOn Unix, this option specifies the Unix socket file to use when listening for local connections. The default value is
/tmp/mysql.sock. If this option is given, the server creates the file in the data directory unless an absolute path name is given to specify a different directory. On Windows, the option specifies the pipe name to use when listening for local connections that use a named pipe. The default value isMySQL(not case-sensitive). --sql-mode=value[,value[,value...]]Command-Line Format --sql-mode=nameSystem Variable sql_modeScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Set Default Value ONLY_FULL_GROUP_BY STRICT_TRANS_TABLES NO_ZERO_IN_DATE NO_ZERO_DATE ERROR_FOR_DIVISION_BY_ZERO NO_ENGINE_SUBSTITUTIONValid Values ALLOW_INVALID_DATESANSI_QUOTESERROR_FOR_DIVISION_BY_ZEROHIGH_NOT_PRECEDENCEIGNORE_SPACENO_AUTO_VALUE_ON_ZERONO_BACKSLASH_ESCAPESNO_DIR_IN_CREATENO_ENGINE_SUBSTITUTIONNO_UNSIGNED_SUBTRACTIONNO_ZERO_DATENO_ZERO_IN_DATEONLY_FULL_GROUP_BYPAD_CHAR_TO_FULL_LENGTHPIPES_AS_CONCATREAL_AS_FLOATSTRICT_ALL_TABLESSTRICT_TRANS_TABLESTIME_TRUNCATE_FRACTIONALSet the SQL mode. See Section 5.1.11, “Server SQL Modes”.
NoteMySQL installation programs may configure the SQL mode during the installation process.
If the SQL mode differs from the default or from what you expect, check for a setting in an option file that the server reads at startup.
-
Command-Line Format --ssl[={OFF|ON}]Disabled by skip-sslType Boolean Default Value ONThe
--ssloption specifies that the server permits but does not require encrypted connections. This option is enabled by default.--sslcan be specified in negated form as--skip-sslor a synonym (--ssl=OFF,--disable-ssl). In this case, the option specifies that the server does not permit encrypted connections, regardless of the settings of thetls_andxxxssl_system variables.xxxThe
--ssloption has an effect only at server startup on whether the server supports encrypted connections. It is ignored and has no effect on the operation ofALTER INSTANCE RELOAD TLSat runtime. For example, you can use--ssl=OFFto start the server with encrypted connections disabled, then reconfigure TLS and executeALTER INSTANCE RELOAD TLSto enable encrypted connections at runtime.For more information about configuring whether the server permits clients to connect using SSL and indicating where to find SSL keys and certificates, see Section 6.3.1, “Configuring MySQL to Use Encrypted Connections”, which also describes server capabilities for certificate and key file autogeneration and autodiscovery. Consider setting at least the
ssl_certandssl_keysystem variables on the server side and the--ssl-ca(or--ssl-capath) option on the client side. -
Command-Line Format --standalonePlatform Specific Windows Available on Windows only; instructs the MySQL server not to run as a service.
-
Command-Line Format --super-large-pages[={OFF|ON}]Platform Specific Solaris Type Boolean Default Value OFFStandard use of large pages in MySQL attempts to use the largest size supported, up to 4MB. Under Solaris, a “super large pages” feature enables uses of pages up to 256MB. This feature is available for recent SPARC platforms. It can be enabled or disabled by using the
--super-large-pagesor--skip-super-large-pagesoption. --symbolic-links,--skip-symbolic-linksCommand-Line Format --symbolic-links[={OFF|ON}]Deprecated Yes Type Boolean Default Value OFFEnable or disable symbolic link support. On Unix, enabling symbolic links means that you can link a
MyISAMindex file or data file to another directory with theINDEX DIRECTORYorDATA DIRECTORYoption of theCREATE TABLEstatement. If you delete or rename the table, the files that its symbolic links point to also are deleted or renamed. See Section 8.12.2.2, “Using Symbolic Links for MyISAM Tables on Unix”.NoteSymbolic link support, along with the
--symbolic-linksoption that controls it, is deprecated; you should expect it to be removed in a future version of MySQL. In addition, the option is disabled by default. The relatedhave_symlinksystem variable also is deprecated; expect it be removed in a future version of MySQL.This option has no meaning on Windows.
-
Command-Line Format --sysdate-is-now[={OFF|ON}]Type Boolean Default Value OFFSYSDATE()by default returns the time at which it executes, not the time at which the statement in which it occurs begins executing. This differs from the behavior ofNOW(). This option causesSYSDATE()to be a synonym forNOW(). For information about the implications for binary logging and replication, see the description forSYSDATE()in Section 12.7, “Date and Time Functions” and forSET TIMESTAMPin Section 5.1.8, “Server System Variables”. --tc-heuristic-recover={COMMIT|ROLLBACK}Command-Line Format --tc-heuristic-recover=nameType Enumeration Default Value OFFValid Values OFFCOMMITROLLBACKThe decision to use in a manual heuristic recovery.
If a
--tc-heuristic-recoveroption is specified, the server exits regardless of whether manual heuristic recovery is successful.On systems with more than one storage engine capable of two-phase commit, the
ROLLBACKoption is not safe and causes recovery to halt with the following error:[ERROR] --tc-heuristic-recover rollback strategy is not safe on systems with more than one 2-phase-commit-capable storage engine. Aborting crash recovery.
-
Command-Line Format --transaction-isolation=nameSystem Variable transaction_isolationScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value REPEATABLE-READValid Values READ-UNCOMMITTEDREAD-COMMITTEDREPEATABLE-READSERIALIZABLESets the default transaction isolation level. The
levelvalue can beREAD-UNCOMMITTED,READ-COMMITTED,REPEATABLE-READ, orSERIALIZABLE. See Section 13.3.7, “SET TRANSACTION Statement”.The default transaction isolation level can also be set at runtime using the
SET TRANSACTIONstatement or by setting thetransaction_isolationsystem variable. -
Command-Line Format --transaction-read-only[={OFF|ON}]System Variable transaction_read_onlyScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFSets the default transaction access mode. By default, read-only mode is disabled, so the mode is read/write.
To set the default transaction access mode at runtime, use the
SET TRANSACTIONstatement or set thetransaction_read_onlysystem variable. See Section 13.3.7, “SET TRANSACTION Statement”. --tmpdir=,dir_name-tdir_nameCommand-Line Format --tmpdir=dir_nameSystem Variable tmpdirScope Global Dynamic No SET_VARHint AppliesNo Type Directory name The path of the directory to use for creating temporary files. It might be useful if your default
/tmpdirectory resides on a partition that is too small to hold temporary tables. This option accepts several paths that are used in round-robin fashion. Paths should be separated by colon characters (:) on Unix and semicolon characters (;) on Windows.--tmpdircan be a non-permanent location, such as a directory on a memory-based file system or a directory that is cleared when the server host restarts. If the MySQL server is acting as a replica, and you are using a non-permanent location for--tmpdir, consider setting a different temporary directory for the replica using theslave_load_tmpdirsystem variable. For a replica, the temporary files used to replicateLOAD DATAstatements are stored in this directory, so with a permanent location they can survive machine restarts, although replication can now continue after a restart if the temporary files have been removed.For more information about the storage location of temporary files, see Section B.3.3.5, “Where MySQL Stores Temporary Files”.
-
Command-Line Format --upgrade=valueIntroduced 8.0.16 Type Enumeration Default Value AUTOValid Values AUTONONEMINIMALFORCEThis option controls whether and how the server performs an automatic upgrade at startup. Automatic upgrade involves two steps:
Step 1: Data dictionary upgrade.
This step upgrades:
The data dictionary tables in the
mysqlschema. If the actual data dictionary version is lower than the current expected version, the server upgrades the data dictionary. If it cannot, or is prevented from doing so, the server cannot run.The Performance Schema and
INFORMATION_SCHEMA.
Step 2: Server upgrade.
This step comprises all other upgrade tasks. If the existing installation data has a lower MySQL version than the server expects, it must be upgraded:
The system tables in the
mysqlschema (the remaining non-data dictionary tables).The
sysschema.User schemas.
For details about upgrade steps 1 and 2, see Section 2.11.3, “What the MySQL Upgrade Process Upgrades”.
These
--upgradeoption values are permitted:AUTOThe server performs an automatic upgrade of anything it finds to be out of date (steps 1 and 2). This is the default action if
--upgradeis not specified explicitly.NONEThe server performs no automatic upgrade steps during the startup process (skips steps 1 and 2). Because this option value prevents a data dictionary upgrade, the server exits with an error if the data dictionary is found to be out of date:
[ERROR] [MY-013381] [Server] Server shutting down because upgrade is required, yet prohibited by the command line option '--upgrade=NONE'. [ERROR] [MY-010334] [Server] Failed to initialize DD Storage Engine [ERROR] [MY-010020] [Server] Data Dictionary initialization failed.
MINIMALThe server upgrades the data dictionary, the Performance Schema, and the
INFORMATION_SCHEMA, if necessary (step 1). Note that following an upgrade with this option, Group Replication cannot be started, because system tables on which the replication internals depend are not updated, and reduced functionality might also be apparent in other areas.FORCEThe server upgrades the data dictionary, the Performance Schema, and the
INFORMATION_SCHEMA, if necessary (step 1). In addition, the server forces an upgrade of everything else (step 2). Expect server startup to take longer with this option because the server checks all objects in all schemas.FORCEis useful to force step 2 actions to be performed if the server thinks they are not necessary. For example, you may believe that a system table is missing or has become damaged and want to force a repair.
The following table summarizes the actions taken by the server for each option value.
Option Value Server Performs Step 1? Server Performs Step 2? AUTOIf necessary If necessary NONENo No MINIMALIf necessary No FORCEIf necessary Yes --user={,user_name|user_id}-u {user_name|user_id}Command-Line Format --user=nameType String Run the mysqld server as the user having the name
user_nameor the numeric user IDuser_id. (“User” in this context refers to a system login account, not a MySQL user listed in the grant tables.)This option is mandatory when starting mysqld as
root. The server changes its user ID during its startup sequence, causing it to run as that particular user rather than asroot. See Section 6.1.1, “Security Guidelines”.To avoid a possible security hole where a user adds a
--user=rootoption to amy.cnffile (thus causing the server to run asroot), mysqld uses only the first--useroption specified and produces a warning if there are multiple--useroptions. Options in/etc/my.cnfand$MYSQL_HOME/my.cnfare processed before command-line options, so it is recommended that you put a--useroption in/etc/my.cnfand specify a value other thanroot. The option in/etc/my.cnfis found before any other--useroptions, which ensures that the server runs as a user other thanroot, and that a warning results if any other--useroption is found.-
Command-Line Format --validate-config[={OFF|ON}]Introduced 8.0.16 Type Boolean Default Value OFFValidate the server startup configuration. If no errors are found, the server terminates with an exit code of 0. If an error is found, the server displays a diagnostic message and terminates with an exit code of 1. Warning and information messages may also be displayed, depending on the
log_error_verbosityvalue, but do not produce immediate validation termination or an exit code of 1. For more information, see Section 5.1.3, “Server Configuration Validation”. Use this option with the
--helpoption for detailed help.--version,-VDisplay version information and exit.
The MySQL server maintains many system variables that configure
its operation. Each system variable has a default value. System
variables can be set at server startup using options on the
command line or in an option file. Most of them can be changed
dynamically at runtime using the
SET
statement, which enables you to modify operation of the server
without having to stop and restart it. You can also use system
variable values in expressions.
Setting a global system variable runtime value normally requires
the SYSTEM_VARIABLES_ADMIN
privilege (or the deprecated SUPER
privilege). Setting a session system runtime variable value
normally requires no special privileges and can be done by any
user, although there are exceptions. For more information, see
Section 5.1.9.1, “System Variable Privileges”
There are several ways to see the names and values of system variables:
To see the values that a server uses based on its compiled-in defaults and any option files that it reads, use this command:
mysqld --verbose --help
To see the values that a server uses based only on its compiled-in defaults, ignoring the settings in any option files, use this command:
mysqld --no-defaults --verbose --help
To see the current values used by a running server, use the
SHOW VARIABLESstatement or the Performance Schema system variable tables. See Section 27.12.14, “Performance Schema System Variable Tables”.
This section provides a description of each system variable. For a system variable summary table, see Section 5.1.5, “Server System Variable Reference”. For more information about manipulation of system variables, see Section 5.1.9, “Using System Variables”.
For additional system variable information, see these sections:
Section 5.1.9, “Using System Variables”, discusses the syntax for setting and displaying system variable values.
Section 5.1.9.2, “Dynamic System Variables”, lists the variables that can be set at runtime.
Information on tuning system variables can be found in Section 5.1.1, “Configuring the Server”.
Section 15.14, “InnoDB Startup Options and System Variables”, lists
InnoDBsystem variables.Section 23.3.3.9.2, “NDB Cluster System Variables”, lists system variables which are specific to NDB Cluster.
For information on server system variables specific to replication, see Section 17.1.6, “Replication and Binary Logging Options and Variables”.
Some of the following variable descriptions refer to
“enabling” or “disabling” a variable.
These variables can be enabled with the
SET
statement by setting them to ON or
1, or disabled by setting them to
OFF or 0. Boolean
variables can be set at startup to the values
ON, TRUE,
OFF, and FALSE (not
case-sensitive), as well as 1 and
0. See Section 4.2.2.4, “Program Option Modifiers”.
Some system variables control the size of buffers or caches. For a given buffer, the server might need to allocate internal data structures. These structures typically are allocated from the total memory allocated to the buffer, and the amount of space required might be platform dependent. This means that when you assign a value to a system variable that controls a buffer size, the amount of space actually available might differ from the value assigned. In some cases, the amount might be less than the value assigned. It is also possible that the server adjusts a value upward. For example, if you assign a value of 0 to a variable for which the minimal value is 1024, the server sets the value to 1024.
Values for buffer sizes, lengths, and stack sizes are given in bytes unless otherwise specified.
Some system variables take file name values. Unless otherwise
specified, the default file location is the data directory if the
value is a relative path name. To specify the location explicitly,
use an absolute path name. Suppose that the data directory is
/var/mysql/data. If a file-valued variable is
given as a relative path name, it is located under
/var/mysql/data. If the value is an absolute
path name, its location is as given by the path name.
-
Command-Line Format --activate-all-roles-on-login[={OFF|ON}]System Variable activate_all_roles_on_loginScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFWhether to enable automatic activation of all granted roles when users log in to the server:
If
activate_all_roles_on_loginis enabled, the server activates all roles granted to each account at login time. This takes precedence over default roles specified withSET DEFAULT ROLE.If
activate_all_roles_on_loginis disabled, the server activates the default roles specified withSET DEFAULT ROLE, if any, at login time.
Granted roles include those granted explicitly to the user and those named in the
mandatory_rolessystem variable value.activate_all_roles_on_loginapplies only at login time, and at the beginning of execution for stored programs and views that execute in definer context. To change the active roles within a session, useSET ROLE. To change the active roles for a stored program, the program body should executeSET ROLE. -
Command-Line Format --admin-address=addrIntroduced 8.0.14 System Variable admin_addressScope Global Dynamic No SET_VARHint AppliesNo Type String The IP address on which to listen for TCP/IP connections on the administrative network interface (see Section 5.1.12.1, “Connection Interfaces”). There is no default
admin_addressvalue. If this variable is not specified at startup, the server maintains no administrative interface. The server also has abind_addresssystem variable for configuring regular (nonadministrative) client TCP/IP connections. See Section 5.1.12.1, “Connection Interfaces”.If
admin_addressis specified, its value must satisfy these requirements:The value must be a single IPv4 address, IPv6 address, or host name.
The value cannot specify a wildcard address format (
*,0.0.0.0, or::).As of MySQL 8.0.22, the value may include a network namespace specifier.
An IP address can be specified as an IPv4 or IPv6 address. If the value is a host name, the server resolves the name to an IP address and binds to that address. If a host name resolves to multiple IP addresses, the server uses the first IPv4 address if there are any, or the first IPv6 address otherwise.
The server treats different types of addresses as follows:
If the address is an IPv4-mapped address, the server accepts TCP/IP connections for that address, in either IPv4 or IPv6 format. For example, if the server is bound to
::ffff:127.0.0.1, clients can connect using--host=127.0.0.1or--host=::ffff:127.0.0.1.If the address is a “regular” IPv4 or IPv6 address (such as
127.0.0.1or::1), the server accepts TCP/IP connections only for that IPv4 or IPv6 address.
These rules apply to specifying a network namespace for an address:
A network namespace can be specified for an IP address or a host name.
A network namespace cannot be specified for a wildcard IP address.
For a given address, the network namespace is optional. If given, it must be specified as a
/suffix immediately following the address.nsAn address with no
/suffix uses the host system global namespace. The global namespace is therefore the default.nsAn address with a
/suffix uses the namespace namednsns.The host system must support network namespaces and each named namespace must previously have been set up. Naming a nonexistent namespace produces an error.
For additional information about network namespaces, see Section 5.1.14, “Network Namespace Support”.
If binding to the address fails, the server produces an error and does not start.
The
admin_addresssystem variable is similar to thebind_addresssystem variable that binds the server to an address for ordinary client connections, but with these differences:bind_addresspermits multiple addresses.admin_addresspermits a single address.bind_addresspermits wildcard addresses.admin_addressdoes not.
-
Command-Line Format --admin-port=port_numIntroduced 8.0.14 System Variable admin_portScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 33062Minimum Value 0Maximum Value 65535The TCP/IP port number to use for connections on the administrative network interface (see Section 5.1.12.1, “Connection Interfaces”). Setting this variable to 0 causes the default value to be used.
Setting
admin_porthas no effect ifadmin_addressis not specified because in that case the server maintains no administrative network interface. -
Command-Line Format --admin-ssl-ca=file_nameIntroduced 8.0.21 System Variable admin_ssl_caScope Global Dynamic Yes SET_VARHint AppliesNo Type File name Default Value NULLThe
admin_ssl_casystem variable is likessl_ca, except that it applies to the administrative connection interface rather than the main connection interface. For information about configuring encryption support for the administrative interface, see Administrative Interface Support for Encrypted Connections. -
Command-Line Format --admin-ssl-capath=dir_nameIntroduced 8.0.21 System Variable admin_ssl_capathScope Global Dynamic Yes SET_VARHint AppliesNo Type Directory name Default Value NULLThe
admin_ssl_capathsystem variable is likessl_capath, except that it applies to the administrative connection interface rather than the main connection interface. For information about configuring encryption support for the administrative interface, see Administrative Interface Support for Encrypted Connections. -
Command-Line Format --admin-ssl-cert=file_nameIntroduced 8.0.21 System Variable admin_ssl_certScope Global Dynamic Yes SET_VARHint AppliesNo Type File name Default Value NULLThe
admin_ssl_certsystem variable is likessl_cert, except that it applies to the administrative connection interface rather than the main connection interface. For information about configuring encryption support for the administrative interface, see Administrative Interface Support for Encrypted Connections. -
Command-Line Format --admin-ssl-cipher=nameIntroduced 8.0.21 System Variable admin_ssl_cipherScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value NULLThe
admin_ssl_ciphersystem variable is likessl_cipher, except that it applies to the administrative connection interface rather than the main connection interface. For information about configuring encryption support for the administrative interface, see Administrative Interface Support for Encrypted Connections. -
Command-Line Format --admin-ssl-crl=file_nameIntroduced 8.0.21 System Variable admin_ssl_crlScope Global Dynamic Yes SET_VARHint AppliesNo Type File name Default Value NULLThe
admin_ssl_crlsystem variable is likessl_crl, except that it applies to the administrative connection interface rather than the main connection interface. For information about configuring encryption support for the administrative interface, see Administrative Interface Support for Encrypted Connections. -
Command-Line Format --admin-ssl-crlpath=dir_nameIntroduced 8.0.21 System Variable admin_ssl_crlpathScope Global Dynamic Yes SET_VARHint AppliesNo Type Directory name Default Value NULLThe
admin_ssl_crlpathsystem variable is likessl_crlpath, except that it applies to the administrative connection interface rather than the main connection interface. For information about configuring encryption support for the administrative interface, see Administrative Interface Support for Encrypted Connections. -
Command-Line Format --admin-ssl-key=file_nameIntroduced 8.0.21 System Variable admin_ssl_keyScope Global Dynamic Yes SET_VARHint AppliesNo Type File name Default Value NULLThe
admin_ssl_keysystem variable is likessl_key, except that it applies to the administrative connection interface rather than the main connection interface. For information about configuring encryption support for the administrative interface, see Administrative Interface Support for Encrypted Connections. -
Command-Line Format --admin-tls-ciphersuites=ciphersuite_listIntroduced 8.0.21 System Variable admin_tls_ciphersuitesScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value NULLThe
admin_tls_ciphersuitessystem variable is liketls_ciphersuites, except that it applies to the administrative connection interface rather than the main connection interface. For information about configuring encryption support for the administrative interface, see Administrative Interface Support for Encrypted Connections. -
Command-Line Format --admin-tls-version=protocol_listIntroduced 8.0.21 System Variable admin_tls_versionScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value TLSv1,TLSv1.1,TLSv1.2,TLSv1.3(OpenSSL 1.1.1 and higher)TLSv1,TLSv1.1,TLSv1.2(otherwise)The
admin_tls_versionsystem variable is liketls_version, except that it applies to the administrative connection interface rather than the main connection interface. For information about configuring encryption support for the administrative interface, see Administrative Interface Support for Encrypted Connections. authentication_windows_log_levelCommand-Line Format --authentication-windows-log-level=#System Variable authentication_windows_log_levelScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 2Minimum Value 0Maximum Value 4This variable is available only if the
authentication_windowsWindows authentication plugin is enabled and debugging code is enabled. See Section 6.4.1.6, “Windows Pluggable Authentication”.This variable sets the logging level for the Windows authentication plugin. The following table shows the permitted values.
Value Description 0 No logging 1 Log only error messages 2 Log level 1 messages and warning messages 3 Log level 2 messages and information notes 4 Log level 3 messages and debug messages authentication_windows_use_principal_nameCommand-Line Format --authentication-windows-use-principal-name[={OFF|ON}]System Variable authentication_windows_use_principal_nameScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value ONThis variable is available only if the
authentication_windowsWindows authentication plugin is enabled. See Section 6.4.1.6, “Windows Pluggable Authentication”.A client that authenticates using the
InitSecurityContext()function should provide a string identifying the service to which it connects (targetName). MySQL uses the principal name (UPN) of the account under which the server is running. The UPN has the formuser_id@computer_nameThis variable controls whether the server sends the UPN in the initial challenge. By default, the variable is enabled. For security reasons, it can be disabled to avoid sending the server's account name to a client as cleartext. If the variable is disabled, the server always sends a
0x00byte in the first challenge, the client does not specifytargetName, and as a result, NTLM authentication is used.If the server fails to obtain its UPN (which happens primarily in environments that do not support Kerberos authentication), the UPN is not sent by the server and NTLM authentication is used.
-
Command-Line Format --autocommit[={OFF|ON}]System Variable autocommitScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value ONThe autocommit mode. If set to 1, all changes to a table take effect immediately. If set to 0, you must use
COMMITto accept a transaction orROLLBACKto cancel it. Ifautocommitis 0 and you change it to 1, MySQL performs an automaticCOMMITof any open transaction. Another way to begin a transaction is to use aSTART TRANSACTIONorBEGINstatement. See Section 13.3.1, “START TRANSACTION, COMMIT, and ROLLBACK Statements”.By default, client connections begin with
autocommitset to 1. To cause clients to begin with a default of 0, set the globalautocommitvalue by starting the server with the--autocommit=0option. To set the variable using an option file, include these lines:[mysqld] autocommit=0
-
Command-Line Format --automatic-sp-privileges[={OFF|ON}]System Variable automatic_sp_privilegesScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value ONWhen this variable has a value of 1 (the default), the server automatically grants the
EXECUTEandALTER ROUTINEprivileges to the creator of a stored routine, if the user cannot already execute and alter or drop the routine. (TheALTER ROUTINEprivilege is required to drop the routine.) The server also automatically drops those privileges from the creator when the routine is dropped. Ifautomatic_sp_privilegesis 0, the server does not automatically add or drop these privileges.The creator of a routine is the account used to execute the
CREATEstatement for it. This might not be the same as the account named as theDEFINERin the routine definition.If you start mysqld with
--skip-new,automatic_sp_privilegesis set toOFF.See also Section 25.2.2, “Stored Routines and MySQL Privileges”.
-
Command-Line Format --auto-generate-certs[={OFF|ON}]System Variable auto_generate_certsScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value ONThis variable controls whether the server autogenerates SSL key and certificate files in the data directory, if they do not already exist.
At startup, the server automatically generates server-side and client-side SSL certificate and key files in the data directory if the
auto_generate_certssystem variable is enabled, no SSL options other than--sslare specified, and the server-side SSL files are missing from the data directory. These files enable secure client connections using SSL; see Section 6.3.1, “Configuring MySQL to Use Encrypted Connections”.For more information about SSL file autogeneration, including file names and characteristics, see Section 6.3.3.1, “Creating SSL and RSA Certificates and Keys using MySQL”
The
sha256_password_auto_generate_rsa_keysandcaching_sha2_password_auto_generate_rsa_keyssystem variables are related but control autogeneration of RSA key-pair files needed for secure password exchange using RSA over unencypted connections. -
Command-Line Format --avoid-temporal-upgrade[={OFF|ON}]Deprecated Yes System Variable avoid_temporal_upgradeScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFThis variable controls whether
ALTER TABLEimplicitly upgrades temporal columns found to be in pre-5.6.4 format (TIME,DATETIME, andTIMESTAMPcolumns without support for fractional seconds precision). Upgrading such columns requires a table rebuild, which prevents any use of fast alterations that might otherwise apply to the operation to be performed.This variable is disabled by default. Enabling it causes
ALTER TABLEnot to rebuild temporal columns and thereby be able to take advantage of possible fast alterations.This variable is deprecated; expect it to be removed in a future MySQL release.
-
Command-Line Format --back-log=#System Variable back_logScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value -1(signifies autosizing; do not assign this literal value)Minimum Value 1Maximum Value 65535The number of outstanding connection requests MySQL can have. This comes into play when the main MySQL thread gets very many connection requests in a very short time. It then takes some time (although very little) for the main thread to check the connection and start a new thread. The
back_logvalue indicates how many requests can be stacked during this short time before MySQL momentarily stops answering new requests. You need to increase this only if you expect a large number of connections in a short period of time.In other words, this value is the size of the listen queue for incoming TCP/IP connections. Your operating system has its own limit on the size of this queue. The manual page for the Unix
listen()system call should have more details. Check your OS documentation for the maximum value for this variable.back_logcannot be set higher than your operating system limit.The default value is the value of
max_connections, which enables the permitted backlog to adjust to the maximum permitted number of connections. -
Command-Line Format --basedir=dir_nameSystem Variable basedirScope Global Dynamic No SET_VARHint AppliesNo Type Directory name Default Value parent of mysqld installation directoryThe path to the MySQL installation base directory.
-
Command-Line Format --big-tables[={OFF|ON}]System Variable big_tablesScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFIf enabled, the server stores all temporary tables on disk rather than in memory. This prevents most
The tableerrors fortbl_nameis fullSELECToperations that require a large temporary table, but also slows down queries for which in-memory tables would suffice.The default value for new connections is
OFF(use in-memory temporary tables). Normally, it should never be necessary to enable this variable. When in-memory internal temporary tables are managed by theTempTablestorage engine (the default), and the maximum amount of memory that can be occupied by theTempTablestorage engine is exceeded, theTempTablestorage engine starts storing data to temporary files on disk. When in-memory temporary tables are managed by theMEMORYstorage engine, in-memory tables are automatically converted to disk-based tables as required. For more information, see Section 8.4.4, “Internal Temporary Table Use in MySQL”. -
Command-Line Format --bind-address=addrSystem Variable bind_addressScope Global Dynamic No SET_VARHint AppliesNo Type String Default Value *The MySQL server listens on one or more network sockets for TCP/IP connections. Each socket is bound to one address, but it is possible for an address to map onto multiple network interfaces. To specify how the server should listen for TCP/IP connections, set the
bind_addresssystem variable at server startup. The server also has anadmin_addresssystem variable that enables administrative connections on a dedicated interface. See Section 5.1.12.1, “Connection Interfaces”.If
bind_addressis specified, its value must satisfy these requirements:Prior to MySQL 8.0.13,
bind_addressaccepts a single address value, which may specify a single non-wildcard IP address or host name, or one of the wildcard address formats that permit listening on multiple network interfaces (*,0.0.0.0, or::).As of MySQL 8.0.13,
bind_addressaccepts either a single value as just described, or a list of comma-separated values. When the variable names a list of multiple values, each value must specify a single non-wildcard IP address (either IPv4 or IPv6) or a host name. Wildcard address formats (*,0.0.0.0, or::) are not allowed in a list of values.As of MySQL 8.0.22, addresses may include a network namespace specifier.
IP addresses can be specified as IPv4 or IPv6 addresses. For any value that is a host name, the server resolves the name to an IP address and binds to that address. If a host name resolves to multiple IP addresses, the server uses the first IPv4 address if there are any, or the first IPv6 address otherwise.
The server treats different types of addresses as follows:
If the address is
*, the server accepts TCP/IP connections on all server host IPv4 interfaces, and, if the server host supports IPv6, on all IPv6 interfaces. Use this address to permit both IPv4 and IPv6 connections on all server interfaces. This value is the default. If the variable specifies a list of multiple values, this value is not permitted.If the address is
0.0.0.0, the server accepts TCP/IP connections on all server host IPv4 interfaces. If the variable specifies a list of multiple values, this value is not permitted.If the address is
::, the server accepts TCP/IP connections on all server host IPv4 and IPv6 interfaces. If the variable specifies a list of multiple values, this value is not permitted.If the address is an IPv4-mapped address, the server accepts TCP/IP connections for that address, in either IPv4 or IPv6 format. For example, if the server is bound to
::ffff:127.0.0.1, clients can connect using--host=127.0.0.1or--host=::ffff:127.0.0.1.If the address is a “regular” IPv4 or IPv6 address (such as
127.0.0.1or::1), the server accepts TCP/IP connections only for that IPv4 or IPv6 address.
These rules apply to specifying a network namespace for an address:
A network namespace can be specified for an IP address or a host name.
A network namespace cannot be specified for a wildcard IP address.
For a given address, the network namespace is optional. If given, it must be specified as a
/suffix immediately following the address.nsAn address with no
/suffix uses the host system global namespace. The global namespace is therefore the default.nsAn address with a
/suffix uses the namespace namednsns.The host system must support network namespaces and each named namespace must previously have been set up. Naming a nonexistent namespace produces an error.
If the variable value specifies multiple addresses, it can include addresses in the global namespace, in named namespaces, or a mix.
For additional information about network namespaces, see Section 5.1.14, “Network Namespace Support”.
If binding to any address fails, the server produces an error and does not start.
Examples:
bind_address=*The server listens on all IPv4 or IPv6 addresses, as specified by the
*wildcard.bind_address=198.51.100.20The server listens only on the
198.51.100.20IPv4 address.bind_address=198.51.100.20,2001:db8:0:f101::1The server listens on the
198.51.100.20IPv4 address and the2001:db8:0:f101::1IPv6 address.bind_address=198.51.100.20,*This produces an error because wildcard addresses are not permitted when
bind_addressnames a list of multiple values.bind_address=198.51.100.20/red,2001:db8:0:f101::1/blue,192.0.2.50The server listens on the
198.51.100.20IPv4 address in therednamespace, the2001:db8:0:f101::1IPv6 address in thebluenamespace, and the192.0.2.50IPv4 address in the global namespace.
When
bind_addressnames a single value (wildcard or non-wildcard), the server listens on a single socket, which for a wildcard address may be bound to multiple network interfaces. Whenbind_addressnames a list of multiple values, the server listens on one socket per value, with each socket bound to a single network interface. The number of sockets is linear with the number of values specified. Depending on operating system connection-acceptance efficiency, long value lists might incur a performance penalty for accepting TCP/IP connections.Because file descriptors are allocated for listening sockets and network namespace files, it may be necessary to increase the
open_files_limitsystem variable.If you intend to bind the server to a specific address, be sure that the
mysql.usersystem table contains an account with administrative privileges that you can use to connect to that address. Otherwise, you cannot shut down the server. For example, if you bind the server to*, you can connect to it using all existing accounts. But if you bind the server to::1, it accepts connections only on that address. In that case, first make sure that the'root'@'::1'account is present in themysql.usertable so you can still connect to the server to shut it down. -
Command-Line Format --block-encryption-mode=#System Variable block_encryption_modeScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String Default Value aes-128-ecbThis variable controls the block encryption mode for block-based algorithms such as AES. It affects encryption for
AES_ENCRYPT()andAES_DECRYPT().block_encryption_modetakes a value inaes-format, wherekeylen-modekeylenis the key length in bits andmodeis the encryption mode. The value is not case-sensitive. Permittedkeylenvalues are 128, 192, and 256. Permittedmodevalues areECB,CBC,CFB1,CFB8,CFB128, andOFB.For example, this statement causes the AES encryption functions to use a key length of 256 bits and the CBC mode:
SET block_encryption_mode = 'aes-256-cbc';
An error occurs for attempts to set
block_encryption_modeto a value containing an unsupported key length or a mode that the SSL library does not support. -
Command-Line Format --bulk-insert-buffer-size=#System Variable bulk_insert_buffer_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 8388608Minimum Value 0Maximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295MyISAMuses a special tree-like cache to make bulk inserts faster forINSERT ... SELECT,INSERT ... VALUES (...), (...), ..., andLOAD DATAwhen adding data to nonempty tables. This variable limits the size of the cache tree in bytes per thread. Setting it to 0 disables this optimization. The default value is 8MB.As of MySQL 8.0.14, setting the session value of this system variable is a restricted operation. The session user must have privileges sufficient to set restricted session variables. See Section 5.1.9.1, “System Variable Privileges”.
caching_sha2_password_digest_roundsCommand-Line Format --caching-sha2-password-digest-rounds=#Introduced 8.0.24 System Variable caching_sha2_password_digest_roundsScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 5000Minimum Value 5000Maximum Value 4095000The number of hash rounds for the
caching_sha2_passwordauthentication plugin.caching_sha2_password_auto_generate_rsa_keysCommand-Line Format --caching-sha2-password-auto-generate-rsa-keys[={OFF|ON}]System Variable caching_sha2_password_auto_generate_rsa_keysScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value ONThe server uses this variable to determine whether to autogenerate RSA private/public key-pair files in the data directory if they do not already exist.
At startup, the server automatically generates RSA private/public key-pair files in the data directory if all of these conditions are true: The
sha256_password_auto_generate_rsa_keysorcaching_sha2_password_auto_generate_rsa_keyssystem variable is enabled; no RSA options are specified; the RSA files are missing from the data directory. These key-pair files enable secure password exchange using RSA over unencrypted connections for accounts authenticated by thesha256_passwordorcaching_sha2_passwordplugin; see Section 6.4.1.3, “SHA-256 Pluggable Authentication”, and Section 6.4.1.2, “Caching SHA-2 Pluggable Authentication”.For more information about RSA file autogeneration, including file names and characteristics, see Section 6.3.3.1, “Creating SSL and RSA Certificates and Keys using MySQL”
The
auto_generate_certssystem variable is related but controls autogeneration of SSL certificate and key files needed for secure connections using SSL.caching_sha2_password_private_key_pathCommand-Line Format --caching-sha2-password-private-key-path=file_nameSystem Variable caching_sha2_password_private_key_pathScope Global Dynamic No SET_VARHint AppliesNo Type File name Default Value private_key.pemThis variable specifies the path name of the RSA private key file for the
caching_sha2_passwordauthentication plugin. If the file is named as a relative path, it is interpreted relative to the server data directory. The file must be in PEM format.ImportantBecause this file stores a private key, its access mode should be restricted so that only the MySQL server can read it.
For information about
caching_sha2_password, see Section 6.4.1.2, “Caching SHA-2 Pluggable Authentication”.caching_sha2_password_public_key_pathCommand-Line Format --caching-sha2-password-public-key-path=file_nameSystem Variable caching_sha2_password_public_key_pathScope Global Dynamic No SET_VARHint AppliesNo Type File name Default Value public_key.pemThis variable specifies the path name of the RSA public key file for the
caching_sha2_passwordauthentication plugin. If the file is named as a relative path, it is interpreted relative to the server data directory. The file must be in PEM format.For information about
caching_sha2_password, including information about how clients request the RSA public key, see Section 6.4.1.2, “Caching SHA-2 Pluggable Authentication”.-
System Variable character_set_clientScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String Default Value utf8mb4The character set for statements that arrive from the client. The session value of this variable is set using the character set requested by the client when the client connects to the server. (Many clients support a
--default-character-setoption to enable this character set to be specified explicitly. See also Section 10.4, “Connection Character Sets and Collations”.) The global value of the variable is used to set the session value in cases when the client-requested value is unknown or not available, or the server is configured to ignore client requests:The client requests a character set not known to the server. For example, a Japanese-enabled client requests
sjiswhen connecting to a server not configured withsjissupport.The client is from a version of MySQL older than MySQL 4.1, and thus does not request a character set.
mysqld was started with the
--skip-character-set-client-handshakeoption, which causes it to ignore client character set configuration. This reproduces MySQL 4.0 behavior and is useful should you wish to upgrade the server without upgrading all the clients.
Some character sets cannot be used as the client character set. Attempting to use them as the
character_set_clientvalue produces an error. See Impermissible Client Character Sets. -
System Variable character_set_connectionScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String Default Value utf8mb4The character set used for literals specified without a character set introducer and for number-to-string conversion. For information about introducers, see Section 10.3.8, “Character Set Introducers”.
-
System Variable character_set_databaseScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String Default Value utf8mb4Footnote This option is dynamic, but should be set only by server. You should not set this variable manually. The character set used by the default database. The server sets this variable whenever the default database changes. If there is no default database, the variable has the same value as
character_set_server.As of MySQL 8.0.14, setting the session value of this system variable is a restricted operation. The session user must have privileges sufficient to set restricted session variables. See Section 5.1.9.1, “System Variable Privileges”.
The global
character_set_databaseandcollation_databasesystem variables are deprecated; expect them to be removed in a future version of MySQL.Assigning a value to the session
character_set_databaseandcollation_databasesystem variables is deprecated and assignments produce a warning. Expect the session variables to become read-only (and assignments to them to produce an error) in a future version of MySQL in which it remains possible to access the session variables to determine the database character set and collation for the default database. -
Command-Line Format --character-set-filesystem=nameSystem Variable character_set_filesystemScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String Default Value binaryThe file system character set. This variable is used to interpret string literals that refer to file names, such as in the
LOAD DATAandSELECT ... INTO OUTFILEstatements and theLOAD_FILE()function. Such file names are converted fromcharacter_set_clienttocharacter_set_filesystembefore the file opening attempt occurs. The default value isbinary, which means that no conversion occurs. For systems on which multibyte file names are permitted, a different value may be more appropriate. For example, if the system represents file names using UTF-8, setcharacter_set_filesystemto'utf8mb4'.As of MySQL 8.0.14, setting the session value of this system variable is a restricted operation. The session user must have privileges sufficient to set restricted session variables. See Section 5.1.9.1, “System Variable Privileges”.
-
System Variable character_set_resultsScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String Default Value utf8mb4The character set used for returning query results to the client. This includes result data such as column values, result metadata such as column names, and error messages.
-
Command-Line Format --character-set-server=nameSystem Variable character_set_serverScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String Default Value utf8mb4The servers default character set. See Section 10.15, “Character Set Configuration”. If you set this variable, you should also set
collation_serverto specify the collation for the character set. -
System Variable character_set_systemScope Global Dynamic No SET_VARHint AppliesNo Type String Default Value utf8The character set used by the server for storing identifiers. The value is always
utf8. -
Command-Line Format --character-sets-dir=dir_nameSystem Variable character_sets_dirScope Global Dynamic No SET_VARHint AppliesNo Type Directory name The directory where character sets are installed. See Section 10.15, “Character Set Configuration”.
-
Command-Line Format --check-proxy-users[={OFF|ON}]System Variable check_proxy_usersScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFSome authentication plugins implement proxy user mapping for themselves (for example, the PAM and Windows authentication plugins). Other authentication plugins do not support proxy users by default. Of these, some can request that the MySQL server itself map proxy users according to granted proxy privileges:
mysql_native_password,sha256_password.If the
check_proxy_userssystem variable is enabled, the server performs proxy user mapping for any authentication plugins that make such a request. However, it may also be necessary to enable plugin-specific system variables to take advantage of server proxy user mapping support:For the
mysql_native_passwordplugin, enablemysql_native_password_proxy_users.For the
sha256_passwordplugin, enablesha256_password_proxy_users.
For information about user proxying, see Section 6.2.18, “Proxy Users”.
-
System Variable collation_connectionScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String The collation of the connection character set.
collation_connectionis important for comparisons of literal strings. For comparisons of strings with column values,collation_connectiondoes not matter because columns have their own collation, which has a higher collation precedence (see Section 10.8.4, “Collation Coercibility in Expressions”). -
System Variable collation_databaseScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String Default Value utf8mb4_0900_ai_ciFootnote This option is dynamic, but should be set only by server. You should not set this variable manually. The collation used by the default database. The server sets this variable whenever the default database changes. If there is no default database, the variable has the same value as
collation_server.As of MySQL 8.0.18, setting the session value of this system variable is no longer a restricted operation.
The global
character_set_databaseandcollation_databasesystem variables are deprecated; expect them to be removed in a future version of MySQL.Assigning a value to the session
character_set_databaseandcollation_databasesystem variables is deprecated and assignments produce a warning. Expect the session variables to become read-only (and assignments to produce an error) in a future version of MySQL in which it remains possible to access the session variables to determine the database character set and collation for the default database. -
Command-Line Format --collation-server=nameSystem Variable collation_serverScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String Default Value utf8mb4_0900_ai_ciThe server's default collation. See Section 10.15, “Character Set Configuration”.
-
Command-Line Format --completion-type=#System Variable completion_typeScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value NO_CHAINValid Values NO_CHAINCHAINRELEASE012The transaction completion type. This variable can take the values shown in the following table. The variable can be assigned using either the name values or corresponding integer values.
Value Description NO_CHAIN(or 0)COMMITandROLLBACKare unaffected. This is the default value.CHAIN(or 1)COMMITandROLLBACKare equivalent toCOMMIT AND CHAINandROLLBACK AND CHAIN, respectively. (A new transaction starts immediately with the same isolation level as the just-terminated transaction.)RELEASE(or 2)COMMITandROLLBACKare equivalent toCOMMIT RELEASEandROLLBACK RELEASE, respectively. (The server disconnects after terminating the transaction.)completion_typeaffects transactions that begin withSTART TRANSACTIONorBEGINand end withCOMMITorROLLBACK. It does not apply to implicit commits resulting from execution of the statements listed in Section 13.3.3, “Statements That Cause an Implicit Commit”. It also does not apply forXA COMMIT,XA ROLLBACK, or whenautocommit=1. -
Command-Line Format --concurrent-insert[=value]System Variable concurrent_insertScope Global Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value AUTOValid Values NEVERAUTOALWAYS012If
AUTO(the default), MySQL permitsINSERTandSELECTstatements to run concurrently forMyISAMtables that have no free blocks in the middle of the data file.This variable can take the values shown in the following table. The variable can be assigned using either the name values or corresponding integer values.
Value Description NEVER(or 0)Disables concurrent inserts AUTO(or 1)(Default) Enables concurrent insert for MyISAMtables that do not have holesALWAYS(or 2)Enables concurrent inserts for all MyISAMtables, even those that have holes. For a table with a hole, new rows are inserted at the end of the table if it is in use by another thread. Otherwise, MySQL acquires a normal write lock and inserts the row into the hole.If you start mysqld with
--skip-new,concurrent_insertis set toNEVER.See also Section 8.11.3, “Concurrent Inserts”.
-
Command-Line Format --connect-timeout=#System Variable connect_timeoutScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 10Minimum Value 2Maximum Value 31536000The number of seconds that the mysqld server waits for a connect packet before responding with
Bad handshake. The default value is 10 seconds.Increasing the
connect_timeoutvalue might help if clients frequently encounter errors of the formLost connection to MySQL server at '.XXX', system error:errno -
System Variable core_fileScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value OFFWhether to write a core file if the server unexpectedly exits. This variable is set by the
--core-fileoption. -
Command-Line Format --create-admin-listener-thread[={OFF|ON}]Introduced 8.0.14 System Variable create_admin_listener_threadScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value OFFWhether to use a dedicated listening thread for client connections on the administrative network interface (see Section 5.1.12.1, “Connection Interfaces”). The default is
OFF; that is, the manager thread for ordinary connections on the main interface also handles connections for the administrative interface.Depending on factors such as platform type and workload, you may find one setting for this variable yields better performance than the other setting.
Setting
create_admin_listener_threadhas no effect ifadmin_addressis not specified because in that case the server maintains no administrative network interface. -
Command-Line Format --cte-max-recursion-depth=#System Variable cte_max_recursion_depthScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 1000Minimum Value 0Maximum Value 4294967295The common table expression (CTE) maximum recursion depth. The server terminates execution of any CTE that recurses more levels than the value of this variable. For more information, see Limiting Common Table Expression Recursion.
-
Command-Line Format --datadir=dir_nameSystem Variable datadirScope Global Dynamic No SET_VARHint AppliesNo Type Directory name The path to the MySQL server data directory. Relative paths are resolved with respect to the current directory. If you expect the server to be started automatically (that is, in contexts for which you cannot know the current directory in advance), it is best to specify the
datadirvalue as an absolute path. -
Command-Line Format --debug[=debug_options]System Variable debugScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String Default Value (Windows) d:t:i:O,\mysqld.traceDefault Value (Unix) d:t:i:o,/tmp/mysqld.traceThis variable indicates the current debugging settings. It is available only for servers built with debugging support. The initial value comes from the value of instances of the
--debugoption given at server startup. The global and session values may be set at runtime.Setting the session value of this system variable is a restricted operation. The session user must have privileges sufficient to set restricted session variables. See Section 5.1.9.1, “System Variable Privileges”.
Assigning a value that begins with
+or-cause the value to added to or subtracted from the current value:mysql>
SET debug = 'T';mysql>SELECT @@debug;+---------+ | @@debug | +---------+ | T | +---------+ mysql>SET debug = '+P';mysql>SELECT @@debug;+---------+ | @@debug | +---------+ | P:T | +---------+ mysql>SET debug = '-P';mysql>SELECT @@debug;+---------+ | @@debug | +---------+ | T | +---------+For more information, see Section 5.9.4, “The DBUG Package”.
-
System Variable debug_syncScope Session Dynamic Yes SET_VARHint AppliesNo Type String This variable is the user interface to the Debug Sync facility. Use of Debug Sync requires that MySQL be configured with the
-DENABLE_DEBUG_SYNC=1CMake option (see Section 2.9.7, “MySQL Source-Configuration Options”). If Debug Sync is not compiled in, this system variable is not available.The global variable value is read only and indicates whether the facility is enabled. By default, Debug Sync is disabled and the value of
debug_syncisOFF. If the server is started with--debug-sync-timeout=, whereNNis a timeout value greater than 0, Debug Sync is enabled and the value ofdebug_syncisON - current signalfollowed by the signal name. Also,Nbecomes the default timeout for individual synchronization points.The session value can be read by any user and has the same value as the global variable. The session value can be set to control synchronization points.
Setting the session value of this system variable is a restricted operation. The session user must have privileges sufficient to set restricted session variables. See Section 5.1.9.1, “System Variable Privileges”.
For a description of the Debug Sync facility and how to use synchronization points, see MySQL Internals: Test Synchronization.
-
Command-Line Format --default-authentication-plugin=plugin_nameSystem Variable default_authentication_pluginScope Global Dynamic No SET_VARHint AppliesNo Type Enumeration Default Value caching_sha2_passwordValid Values mysql_native_passwordsha256_passwordcaching_sha2_passwordThe default authentication plugin. These values are permitted:
mysql_native_password: Use MySQL native passwords; see Section 6.4.1.1, “Native Pluggable Authentication”.sha256_password: Use SHA-256 passwords; see Section 6.4.1.3, “SHA-256 Pluggable Authentication”.caching_sha2_password: Use SHA-256 passwords; see Section 6.4.1.2, “Caching SHA-2 Pluggable Authentication”.
NoteIn MySQL 8.0,
caching_sha2_passwordis the default authentication plugin rather thanmysql_native_password. For information about the implications of this change for server operation and compatibility of the server with clients and connectors, see caching_sha2_password as the Preferred Authentication Plugin.The
default_authentication_pluginvalue affects these aspects of server operation:It determines which authentication plugin the server assigns to new accounts created by
CREATE USERandGRANTstatements that do not explicitly specify an authentication plugin.For an account created with the following statement, the server associates the account with the default authentication plugin and assigns the account the given password, hashed as required by that plugin:
CREATE USER ... IDENTIFIED BY '
cleartext password';
-
System Variable default_collation_for_utf8mb4Scope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Enumeration Valid Values utf8mb4_0900_ai_ciutf8mb4_general_ciFor internal use by replication. This system variable is set to the default collation for the
utf8mb4character set. The value of the variable is replicated from a source to a replica so that the replica can correctly process data originating from a source with a different default collation forutf8mb4. This variable is primarily intended to support replication from a MySQL 5.7 or older replication source server to a MySQL 8.0 replica server, or group replication with a MySQL 5.7 primary node and one or more MySQL 8.0 secondaries. The default collation forutf8mb4in MySQL 5.7 isutf8mb4_general_ci, bututf8mb4_0900_ai_ciin MySQL 8.0. The variable is not present in releases earlier than MySQL 8.0, so if the replica does not receive a value for the variable, it assumes the source is from an earlier release and sets the value to the previous default collationutf8mb4_general_ci.As of MySQL 8.0.18, setting the session value of this system variable is no longer a restricted operation.
The default
utf8mb4collation is used in the following statements:CREATE TABLEandALTER TABLEhaving aCHARACTER SET utf8mb4clause without aCOLLATIONclause, either for the table character set or for a column character set.CREATE DATABASEandALTER DATABASEhaving aCHARACTER SET utf8mb4clause without aCOLLATIONclause.Any statement containing a string literal of the form
_utf8mb4'without asome text'COLLATEclause.
-
Command-Line Format --default-password-lifetime=#System Variable default_password_lifetimeScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 65535This variable defines the global automatic password expiration policy. The default
default_password_lifetimevalue is 0, which disables automatic password expiration. If the value ofdefault_password_lifetimeis a positive integerN, it indicates the permitted password lifetime; passwords must be changed everyNdays.The global password expiration policy can be overridden as desired for individual accounts using the password expiration option of the
CREATE USERandALTER USERstatements. See Section 6.2.15, “Password Management”. -
Command-Line Format --default-storage-engine=nameSystem Variable default_storage_engineScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value InnoDBThe default storage engine for tables. See Chapter 16, Alternative Storage Engines. This variable sets the storage engine for permanent tables only. To set the storage engine for
TEMPORARYtables, set thedefault_tmp_storage_enginesystem variable.To see which storage engines are available and enabled, use the
SHOW ENGINESstatement or query theINFORMATION_SCHEMAENGINEStable.If you disable the default storage engine at server startup, you must set the default engine for both permanent and
TEMPORARYtables to a different engine, or else the server does not start. -
Command-Line Format --default-table-encryption[={OFF|ON}]Introduced 8.0.16 System Variable default_table_encryptionScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Boolean Default Value OFFDefines the default encryption setting applied to schemas and general tablespaces when they are created without specifying an
ENCRYPTIONclause.The
default_table_encryptionvariable is only applicable to user-created schemas and general tablespaces. It does not govern encryption of themysqlsystem tablespace.Setting the runtime value of
default_table_encryptionrequires theSYSTEM_VARIABLES_ADMINandTABLE_ENCRYPTION_ADMINprivileges, or the deprecatedSUPERprivilege.default_table_encryptionsupportsSET PERSISTandSET PERSIST_ONLYsyntax. See Section 5.1.9.3, “Persisted System Variables”.For more information, see Defining an Encryption Default for Schemas and General Tablespaces.
-
Command-Line Format --default-tmp-storage-engine=nameSystem Variable default_tmp_storage_engineScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Enumeration Default Value InnoDBThe default storage engine for
TEMPORARYtables (created withCREATE TEMPORARY TABLE). To set the storage engine for permanent tables, set thedefault_storage_enginesystem variable. Also see the discussion of that variable regarding possible values.If you disable the default storage engine at server startup, you must set the default engine for both permanent and
TEMPORARYtables to a different engine, or else the server does not start. -
Command-Line Format --default-week-format=#System Variable default_week_formatScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 7The default mode value to use for the
WEEK()function. See Section 12.7, “Date and Time Functions”. -
Command-Line Format --delay-key-write[={OFF|ON|ALL}]System Variable delay_key_writeScope Global Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value ONValid Values ONOFFALLThis variable specifies how to use delayed key writes. It applies only to
MyISAMtables. Delayed key writing causes key buffers not to be flushed between writes. See also Section 16.2.1, “MyISAM Startup Options”.This variable can have one of the following values to affect handling of the
DELAY_KEY_WRITEtable option that can be used inCREATE TABLEstatements.Option Description OFFDELAY_KEY_WRITEis ignored.ONMySQL honors any DELAY_KEY_WRITEoption specified inCREATE TABLEstatements. This is the default value.ALLAll new opened tables are treated as if they were created with the DELAY_KEY_WRITEoption enabled.NoteIf you set this variable to
ALL, you should not useMyISAMtables from within another program (such as another MySQL server or myisamchk) when the tables are in use. Doing so leads to index corruption.If
DELAY_KEY_WRITEis enabled for a table, the key buffer is not flushed for the table on every index update, but only when the table is closed. This speeds up writes on keys a lot, but if you use this feature, you should add automatic checking of allMyISAMtables by starting the server with themyisam_recover_optionssystem variable set (for example,myisam_recover_options='BACKUP,FORCE'). See Section 5.1.8, “Server System Variables”, and Section 16.2.1, “MyISAM Startup Options”.If you start mysqld with
--skip-new,delay_key_writeis set toOFF.WarningIf you enable external locking with
--external-locking, there is no protection against index corruption for tables that use delayed key writes. -
Command-Line Format --delayed-insert-limit=#Deprecated Yes System Variable delayed_insert_limitScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 100Minimum Value 1Maximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295This system variable is deprecated (because
DELAYEDinserts are not supported), and you should expect it to be removed in a future release. -
Command-Line Format --delayed-insert-timeout=#Deprecated Yes System Variable delayed_insert_timeoutScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 300This system variable is deprecated (because
DELAYEDinserts are not supported), and you should expect it to be removed in a future release. -
Command-Line Format --delayed-queue-size=#Deprecated Yes System Variable delayed_queue_sizeScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 1000Minimum Value 1Maximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295This system variable is deprecated (because
DELAYEDinserts are not supported), and you should expect it to be removed in a future release. -
Command-Line Format --disabled-storage-engines=engine[,engine]...System Variable disabled_storage_enginesScope Global Dynamic No SET_VARHint AppliesNo Type String Default Value empty stringThis variable indicates which storage engines cannot be used to create tables or tablespaces. For example, to prevent new
MyISAMorFEDERATEDtables from being created, start the server with these lines in the server option file:[mysqld] disabled_storage_engines="MyISAM,FEDERATED"
By default,
disabled_storage_enginesis empty (no engines disabled), but it can be set to a comma-separated list of one or more engines (not case-sensitive). Any engine named in the value cannot be used to create tables or tablespaces withCREATE TABLEorCREATE TABLESPACE, and cannot be used withALTER TABLE ... ENGINEorALTER TABLESPACE ... ENGINEto change the storage engine of existing tables or tablespaces. Attempts to do so result in anER_DISABLED_STORAGE_ENGINEerror.disabled_storage_enginesdoes not restrict other DDL statements for existing tables, such asCREATE INDEX,TRUNCATE TABLE,ANALYZE TABLE,DROP TABLE, orDROP TABLESPACE. This permits a smooth transition so that existing tables or tablespaces that use a disabled engine can be migrated to a permitted engine by means such asALTER TABLE ... ENGINE.permitted_engineIt is permitted to set the
default_storage_engineordefault_tmp_storage_enginesystem variable to a storage engine that is disabled. This could cause applications to behave erratically or fail, although that might be a useful technique in a development environment for identifying applications that use disabled engines, so that they can be modified.disabled_storage_enginesis disabled and has no effect if the server is started with any of these options:--initialize,--initialize-insecure,--skip-grant-tables.NoteSetting
disabled_storage_enginesmight cause an issue with mysql_upgrade. For details, see Section 4.4.5, “mysql_upgrade — Check and Upgrade MySQL Tables”. disconnect_on_expired_passwordCommand-Line Format --disconnect-on-expired-password[={OFF|ON}]System Variable disconnect_on_expired_passwordScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value ONThis variable controls how the server handles clients with expired passwords:
If the client indicates that it can handle expired passwords, the value of
disconnect_on_expired_passwordis irrelevant. The server permits the client to connect but puts it in sandbox mode.If the client does not indicate that it can handle expired passwords, the server handles the client according to the value of
disconnect_on_expired_password:If
disconnect_on_expired_password: is enabled, the server disconnects the client.If
disconnect_on_expired_password: is disabled, the server permits the client to connect but puts it in sandbox mode.
For more information about the interaction of client and server settings relating to expired-password handling, see Section 6.2.16, “Server Handling of Expired Passwords”.
-
Command-Line Format --div-precision-increment=#System Variable div_precision_incrementScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 4Minimum Value 0Maximum Value 30This variable indicates the number of digits by which to increase the scale of the result of division operations performed with the
/operator. The default value is 4. The minimum and maximum values are 0 and 30, respectively. The following example illustrates the effect of increasing the default value.mysql>
SELECT 1/7;+--------+ | 1/7 | +--------+ | 0.1429 | +--------+ mysql>SET div_precision_increment = 12;mysql>SELECT 1/7;+----------------+ | 1/7 | +----------------+ | 0.142857142857 | +----------------+ dragnet.log_error_filter_rulesCommand-Line Format --dragnet.log-error-filter-rules=valueSystem Variable dragnet.log_error_filter_rulesScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value IF prio>=INFORMATION THEN drop. IF EXISTS source_line THEN unset source_line.The filter rules that control operation of the
log_filter_dragneterror log filter component. Iflog_filter_dragnetis not installed,dragnet.log_error_filter_rulesis unavailable. Iflog_filter_dragnetis installed but not enabled, changes todragnet.log_error_filter_ruleshave no effect.The effect of the default value is similar to the filtering performed by the
log_sink_internalfilter with a setting oflog_error_verbosity=2.As of MySQL 8.0.12, the
dragnet.Statusstatus variable can be consulted to determine the result of the most recent assignment todragnet.log_error_filter_rules.Prior to MySQL 8.0.12, successful assignments to
dragnet.log_error_filter_rulesat runtime produce a note confirming the new value:mysql>
SET GLOBAL dragnet.log_error_filter_rules = 'IF prio <> 0 THEN unset prio.';Query OK, 0 rows affected, 1 warning (0.00 sec) mysql>SHOW WARNINGS\G*************************** 1. row *************************** Level: Note Code: 4569 Message: filter configuration accepted: SET @@GLOBAL.dragnet.log_error_filter_rules= 'IF prio!=ERROR THEN unset prio.';The value displayed by
SHOW WARNINGSindicates the “decompiled” canonical representation after the rule set has been successfully parsed and compiled into internal form. Semantically, this canonical form is identical to the value assigned todragnet.log_error_filter_rules, but there may be some differences between the assigned and canonical values, as illustrated by the preceding example:The
<>operator is changed to!=.The numeric priority of 0 is changed to the corresponding priority symbol
ERROR.Optional spaces are removed.
For additional information, see Section 5.4.2.4, “Types of Error Log Filtering”, and Section 5.5.3, “Error Log Components”.
-
Command-Line Format --end-markers-in-json[={OFF|ON}]System Variable end_markers_in_jsonScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Boolean Default Value OFFWhether optimizer JSON output should add end markers. See MySQL Internals: The end_markers_in_json System Variable.
-
Command-Line Format --eq-range-index-dive-limit=#System Variable eq_range_index_dive_limitScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 200Minimum Value 0Maximum Value 4294967295This variable indicates the number of equality ranges in an equality comparison condition when the optimizer should switch from using index dives to index statistics in estimating the number of qualifying rows. It applies to evaluation of expressions that have either of these equivalent forms, where the optimizer uses a nonunique index to look up
col_namevalues:col_nameIN(val1, ...,valN)col_name=val1OR ... ORcol_name=valNIn both cases, the expression contains
Nequality ranges. The optimizer can make row estimates using index dives or index statistics. Ifeq_range_index_dive_limitis greater than 0, the optimizer uses existing index statistics instead of index dives if there areeq_range_index_dive_limitor more equality ranges. Thus, to permit use of index dives for up toNequality ranges, seteq_range_index_dive_limittoN+ 1. To disable use of index statistics and always use index dives regardless ofN, seteq_range_index_dive_limitto 0.For more information, see Equality Range Optimization of Many-Valued Comparisons.
To update table index statistics for best estimates, use
ANALYZE TABLE. The number of errors that resulted from the last statement that generated messages. This variable is read only. See Section 13.7.7.17, “SHOW ERRORS Statement”.
-
Command-Line Format --event-scheduler[=value]System Variable event_schedulerScope Global Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value ONValid Values ONOFFDISABLEDThis variable enables or disables, and starts or stops, the Event Scheduler. The possible status values are
ON,OFF, andDISABLED, with the default beingOFF. Turning the Event SchedulerOFFis not the same as disabling the Event Scheduler, which requires setting the status toDISABLED. This variable and its effects on the Event Scheduler's operation are discussed in greater detail in Section 25.4.2, “Event Scheduler Configuration” explicit_defaults_for_timestampCommand-Line Format --explicit-defaults-for-timestamp[={OFF|ON}]Deprecated Yes System Variable explicit_defaults_for_timestampScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value ONThis system variable determines whether the server enables certain nonstandard behaviors for default values and
NULL-value handling inTIMESTAMPcolumns. By default,explicit_defaults_for_timestampis enabled, which disables the nonstandard behaviors. Disablingexplicit_defaults_for_timestampresults in a warning.As of MySQL 8.0.18, setting the session value of this system variable is no longer a restricted operation.
If
explicit_defaults_for_timestampis disabled, the server enables the nonstandard behaviors and handlesTIMESTAMPcolumns as follows:TIMESTAMPcolumns not explicitly declared with theNULLattribute are automatically declared with theNOT NULLattribute. Assigning such a column a value ofNULLis permitted and sets the column to the current timestamp. Exception: As of MySQL 8.0.22, attempting to insertNULLinto a generated column declared asTIMESTAMP NOT NULLis rejected with an error.The first
TIMESTAMPcolumn in a table, if not explicitly declared with theNULLattribute or an explicitDEFAULTorON UPDATEattribute, is automatically declared with theDEFAULT CURRENT_TIMESTAMPandON UPDATE CURRENT_TIMESTAMPattributes.TIMESTAMPcolumns following the first one, if not explicitly declared with theNULLattribute or an explicitDEFAULTattribute, are automatically declared asDEFAULT '0000-00-00 00:00:00'(the “zero” timestamp). For inserted rows that specify no explicit value for such a column, the column is assigned'0000-00-00 00:00:00'and no warning occurs.Depending on whether strict SQL mode or the
NO_ZERO_DATESQL mode is enabled, a default value of'0000-00-00 00:00:00'may be invalid. Be aware that theTRADITIONALSQL mode includes strict mode andNO_ZERO_DATE. See Section 5.1.11, “Server SQL Modes”.
The nonstandard behaviors just described are deprecated; expect them to be removed in a future MySQL release.
If
explicit_defaults_for_timestampis enabled, the server disables the nonstandard behaviors and handlesTIMESTAMPcolumns as follows:It is not possible to assign a
TIMESTAMPcolumn a value ofNULLto set it to the current timestamp. To assign the current timestamp, set the column toCURRENT_TIMESTAMPor a synonym such asNOW().TIMESTAMPcolumns not explicitly declared with theNOT NULLattribute are automatically declared with theNULLattribute and permitNULLvalues. Assigning such a column a value ofNULLsets it toNULL, not the current timestamp.TIMESTAMPcolumns declared with theNOT NULLattribute do not permitNULLvalues. For inserts that specifyNULLfor such a column, the result is either an error for a single-row insert or if strict SQL mode is enabled, or'0000-00-00 00:00:00'is inserted for multiple-row inserts with strict SQL mode disabled. In no case does assigning the column a value ofNULLset it to the current timestamp.TIMESTAMPcolumns explicitly declared with theNOT NULLattribute and without an explicitDEFAULTattribute are treated as having no default value. For inserted rows that specify no explicit value for such a column, the result depends on the SQL mode. If strict SQL mode is enabled, an error occurs. If strict SQL mode is not enabled, the column is declared with the implicit default of'0000-00-00 00:00:00'and a warning occurs. This is similar to how MySQL treats other temporal types such asDATETIME.No
TIMESTAMPcolumn is automatically declared with theDEFAULT CURRENT_TIMESTAMPorON UPDATE CURRENT_TIMESTAMPattributes. Those attributes must be explicitly specified.The first
TIMESTAMPcolumn in a table is not handled differently fromTIMESTAMPcolumns following the first one.
If
explicit_defaults_for_timestampis disabled at server startup, this warning appears in the error log:[Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server option (see documentation for more details).
As indicated by the warning, to disable the deprecated nonstandard behaviors, enable the
explicit_defaults_for_timestampsystem variable at server startup.Noteexplicit_defaults_for_timestampis itself deprecated because its only purpose is to permit control over deprecatedTIMESTAMPbehaviors that are to be removed in a future MySQL release. When removal of those behaviors occurs, expectexplicit_defaults_for_timestampto be removed as well.For additional information, see Section 11.2.5, “Automatic Initialization and Updating for TIMESTAMP and DATETIME”.
-
System Variable external_userScope Session Dynamic No SET_VARHint AppliesNo Type String The external user name used during the authentication process, as set by the plugin used to authenticate the client. With native (built-in) MySQL authentication, or if the plugin does not set the value, this variable is
NULL. See Section 6.2.18, “Proxy Users”. -
Command-Line Format --flush[={OFF|ON}]System Variable flushScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFIf
ON, the server flushes (synchronizes) all changes to disk after each SQL statement. Normally, MySQL does a write of all changes to disk only after each SQL statement and lets the operating system handle the synchronizing to disk. See Section B.3.3.3, “What to Do If MySQL Keeps Crashing”. This variable is set toONif you start mysqld with the--flushoption.NoteIf
flushis enabled, the value offlush_timedoes not matter and changes toflush_timehave no effect on flush behavior. -
Command-Line Format --flush-time=#System Variable flush_timeScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0If this is set to a nonzero value, all tables are closed every
flush_timeseconds to free up resources and synchronize unflushed data to disk. This option is best used only on systems with minimal resources.NoteIf
flushis enabled, the value offlush_timedoes not matter and changes toflush_timehave no effect on flush behavior. -
System Variable foreign_key_checksScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Boolean Default Value ONIf set to 1 (the default), foreign key constraints are checked. If set to 0, foreign key constraints are ignored, with a couple of exceptions. When re-creating a table that was dropped, an error is returned if the table definition does not conform to the foreign key constraints referencing the table. Likewise, an
ALTER TABLEoperation returns an error if a foreign key definition is incorrectly formed. For more information, see Section 13.1.20.5, “FOREIGN KEY Constraints”.Setting this variable has the same effect on
NDBtables as it does forInnoDBtables. Typically you leave this setting enabled during normal operation, to enforce referential integrity. Disabling foreign key checking can be useful for reloadingInnoDBtables in an order different from that required by their parent/child relationships. See Section 13.1.20.5, “FOREIGN KEY Constraints”.Setting
foreign_key_checksto 0 also affects data definition statements:DROP SCHEMAdrops a schema even if it contains tables that have foreign keys that are referred to by tables outside the schema, andDROP TABLEdrops tables that have foreign keys that are referred to by other tables.NoteSetting
foreign_key_checksto 1 does not trigger a scan of the existing table data. Therefore, rows added to the table whileforeign_key_checks = 0are not verified for consistency.Dropping an index required by a foreign key constraint is not permitted, even with
foreign_key_checks=0. The foreign key constraint must be removed before dropping the index. -
Command-Line Format --ft-boolean-syntax=nameSystem Variable ft_boolean_syntaxScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value + -><()~*:""&|The list of operators supported by boolean full-text searches performed using
IN BOOLEAN MODE. See Section 12.10.2, “Boolean Full-Text Searches”.The default variable value is
'+ -><()~*:""&|'. The rules for changing the value are as follows:Operator function is determined by position within the string.
The replacement value must be 14 characters.
Each character must be an ASCII nonalphanumeric character.
Either the first or second character must be a space.
No duplicates are permitted except the phrase quoting operators in positions 11 and 12. These two characters are not required to be the same, but they are the only two that may be.
Positions 10, 13, and 14 (which by default are set to
:,&, and|) are reserved for future extensions.
-
Command-Line Format --ft-max-word-len=#System Variable ft_max_word_lenScope Global Dynamic No SET_VARHint AppliesNo Type Integer Minimum Value 10The maximum length of the word to be included in a
MyISAMFULLTEXTindex.NoteFULLTEXTindexes onMyISAMtables must be rebuilt after changing this variable. UseREPAIR TABLE.tbl_nameQUICK -
Command-Line Format --ft-min-word-len=#System Variable ft_min_word_lenScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 4Minimum Value 1The minimum length of the word to be included in a
MyISAMFULLTEXTindex.NoteFULLTEXTindexes onMyISAMtables must be rebuilt after changing this variable. UseREPAIR TABLE.tbl_nameQUICK -
Command-Line Format --ft-query-expansion-limit=#System Variable ft_query_expansion_limitScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 20Minimum Value 0Maximum Value 1000The number of top matches to use for full-text searches performed using
WITH QUERY EXPANSION. -
Command-Line Format --ft-stopword-file=file_nameSystem Variable ft_stopword_fileScope Global Dynamic No SET_VARHint AppliesNo Type File name The file from which to read the list of stopwords for full-text searches on
MyISAMtables. The server looks for the file in the data directory unless an absolute path name is given to specify a different directory. All the words from the file are used; comments are not honored. By default, a built-in list of stopwords is used (as defined in thestorage/myisam/ft_static.cfile). Setting this variable to the empty string ('') disables stopword filtering. See also Section 12.10.4, “Full-Text Stopwords”.NoteFULLTEXTindexes onMyISAMtables must be rebuilt after changing this variable or the contents of the stopword file. UseREPAIR TABLE.tbl_nameQUICK -
Command-Line Format --general-log[={OFF|ON}]System Variable general_logScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFWhether the general query log is enabled. The value can be 0 (or
OFF) to disable the log or 1 (orON) to enable the log. The destination for log output is controlled by thelog_outputsystem variable; if that value isNONE, no log entries are written even if the log is enabled. -
Command-Line Format --general-log-file=file_nameSystem Variable general_log_fileScope Global Dynamic Yes SET_VARHint AppliesNo Type File name Default Value host_name.logThe name of the general query log file. The default value is
host_name.log--general_log_fileoption. generated_random_password_lengthCommand-Line Format --generated-random-password-length=#Introduced 8.0.18 System Variable generated_random_password_lengthScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 20Minimum Value 5Maximum Value 255The maximum number of characters permitted in random passwords generated for
CREATE USER,ALTER USER, andSET PASSWORDstatements. For more information, see Random Password Generation.-
Command-Line Format --group-concat-max-len=#System Variable group_concat_max_lenScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 1024Minimum Value 4Maximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295The maximum permitted result length in bytes for the
GROUP_CONCAT()function. The default is 1024. YESif thezlibcompression library is available to the server,NOif not. If not, theCOMPRESS()andUNCOMPRESS()functions cannot be used.YESif mysqld supports dynamic loading of plugins,NOif not. If the value isNO, you cannot use options such as--plugin-loadto load plugins at server startup, or theINSTALL PLUGINstatement to load plugins at runtime.YESif the server supports spatial data types,NOif not.This variable is a synonym for
have_ssl.YESif statement profiling capability is present,NOif not. If present, theprofilingsystem variable controls whether this capability is enabled or disabled. See Section 13.7.7.31, “SHOW PROFILES Statement”.This variable is deprecated and you should expect it to be removed in a future MySQL release.
The query cache was removed in MySQL 8.0.3.
have_query_cacheis deprecated, always has a value ofNO, and you should expect it to be removed in a future MySQL release.YESifRTREEindexes are available,NOif not. (These are used for spatial indexes inMyISAMtables.)-
System Variable have_sslScope Global Dynamic No SET_VARHint AppliesNo Type String Valid Values YES(SSL support available)DISABLED(SSL support was compiled into server, but server was not started with necessary options to enable it)YESif mysqld supports SSL connections,DISABLEDif the server was compiled with SSL support, but was not started with the appropriate connection-encryption options. For more information, see Section 2.9.6, “Configuring SSL Library Support”. -
System Variable have_statement_timeoutScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Whether the statement execution timeout feature is available (see Statement Execution Time Optimizer Hints). The value can be
NOif the background thread used by this feature could not be initialized. YESif symbolic link support is enabled,NOif not. This is required on Unix for support of theDATA DIRECTORYandINDEX DIRECTORYtable options. If the server is started with the--skip-symbolic-linksoption, the value isDISABLED.This variable has no meaning on Windows.
NoteSymbolic link support, along with the
--symbolic-linksoption that controls it, is deprecated; expect these to be removed in a future version of MySQL. In addition, the option is disabled by default. The relatedhave_symlinksystem variable also is deprecated and you should expect it to be removed in a future version of MySQL.histogram_generation_max_mem_sizeCommand-Line Format --histogram-generation-max-mem-size=#System Variable histogram_generation_max_mem_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 20000000Minimum Value 1000000Maximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295The maximum amount of memory available for generating histogram statistics. See Section 8.9.6, “Optimizer Statistics”, and Section 13.7.3.1, “ANALYZE TABLE Statement”.
Setting the session value of this system variable is a restricted operation. The session user must have privileges sufficient to set restricted session variables. See Section 5.1.9.1, “System Variable Privileges”.
-
Command-Line Format --host-cache-size=#System Variable host_cache_sizeScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value -1(signifies autosizing; do not assign this literal value)Minimum Value 0Maximum Value 65536The MySQL server maintains an in-memory host cache that contains client host name and IP address information and is used to avoid Domain Name System (DNS) lookups; see Section 5.1.12.3, “DNS Lookups and the Host Cache”.
The
host_cache_sizevariable controls the size of the host cache, as well as the size of the Performance Schemahost_cachetable that exposes the cache contents. Settinghost_cache_sizehas these effects:Setting the size to 0 disables the host cache. With the cache disabled, the server performs a DNS lookup every time a client connects.
Changing the size at runtime causes an implicit host cache flushing operation that clears the host cache, truncates the
host_cachetable, and unblocks any blocked hosts.
The default value is autosized to 128, plus 1 for a value of
max_connectionsup to 500, plus 1 for every increment of 20 over 500 in themax_connectionsvalue, capped to a limit of 2000.Using the
--skip-host-cacheoption is similar to setting thehost_cache_sizesystem variable to 0, buthost_cache_sizeis more flexible because it can also be used to resize, enable, and disable the host cache at runtime, not just at server startup. Starting the server with--skip-host-cachedoes not prevent runtime changes to the value ofhost_cache_size, but such changes have no effect and the cache is not re-enabled even ifhost_cache_sizeis set larger than 0. -
The server sets this variable to the server host name at startup. The maximum length is 255 characters as of MySQL 8.0.17, per RFC 1034, and 60 characters before that.
This variable is a synonym for the
last_insert_idvariable. It exists for compatibility with other database systems. You can read its value withSELECT @@identity, and set it usingSET identity.-
Command-Line Format --init-connect=nameSystem Variable init_connectScope Global Dynamic Yes SET_VARHint AppliesNo Type String A string to be executed by the server for each client that connects. The string consists of one or more SQL statements, separated by semicolon characters.
For users that have the
CONNECTION_ADMINprivilege (or the deprecatedSUPERprivilege), the content ofinit_connectis not executed. This is done so that an erroneous value forinit_connectdoes not prevent all clients from connecting. For example, the value might contain a statement that has a syntax error, thus causing client connections to fail. Not executinginit_connectfor users that have theCONNECTION_ADMINorSUPERprivilege enables them to open a connection and fix theinit_connectvalue.init_connectexecution is skipped for any client user with an expired password. This is done because such a user cannot execute arbitrary statements, and thusinit_connectexecution fails, leaving the client unable to connect. Skippinginit_connectexecution enables the user to connect and change password.The server discards any result sets produced by statements in the value of
init_connect. information_schema_stats_expiryCommand-Line Format --information-schema-stats-expiry=#System Variable information_schema_stats_expiryScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 86400Minimum Value 0Maximum Value 31536000Some
INFORMATION_SCHEMAtables contain columns that provide table statistics:STATISTICS.CARDINALITY TABLES.AUTO_INCREMENT TABLES.AVG_ROW_LENGTH TABLES.CHECKSUM TABLES.CHECK_TIME TABLES.CREATE_TIME TABLES.DATA_FREE TABLES.DATA_LENGTH TABLES.INDEX_LENGTH TABLES.MAX_DATA_LENGTH TABLES.TABLE_ROWS TABLES.UPDATE_TIME
Those columns represent dynamic table metadata; that is, information that changes as table contents change.
By default, MySQL retrieves cached values for those columns from the
mysql.index_statsandmysql.table_statsdictionary tables when the columns are queried, which is more efficient than retrieving statistics directly from the storage engine. If cached statistics are not available or have expired, MySQL retrieves the latest statistics from the storage engine and caches them in themysql.index_statsandmysql.table_statsdictionary tables. Subsequent queries retrieve the cached statistics until the cached statistics expire.The
information_schema_stats_expirysession variable defines the period of time before cached statistics expire. The default is 86400 seconds (24 hours), but the time period can be extended to as much as one year.To update cached values at any time for a given table, use
ANALYZE TABLE.To always retrieve the latest statistics directly from the storage engine and bypass cached values, set
information_schema_stats_expiryto0.Querying statistics columns does not store or update statistics in the
mysql.index_statsandmysql.table_statsdictionary tables under these circumstances:When cached statistics have not expired.
When
information_schema_stats_expiryis set to 0.When the server is started in
read_only,super_read_only,transaction_read_only, orinnodb_read_onlymode.When the query also fetches Performance Schema data.
information_schema_stats_expiryis a session variable, and each client session can define its own expiration value. Statistics that are retrieved from the storage engine and cached by one session are available to other sessions.For related information, see Section 8.2.3, “Optimizing INFORMATION_SCHEMA Queries”.
-
Command-Line Format --init-file=file_nameSystem Variable init_fileScope Global Dynamic No SET_VARHint AppliesNo Type File name If specified, this variable names a file containing SQL statements to be read and executed during the startup process. Prior to MySQL 8.0.18, each statement must be on a single line and should not include comments. As of MySQL 8.0.18, the acceptable format for statements in the file is expanded to support these constructs:
delimiter ;, to set the statement delimiter to the;character.delimiter $$, to set the statement delimiter to the$$character sequence.Multiple statements on the same line, delimited by the current delimiter.
Multiple-line statements.
Comments from a
#character to the end of the line.Comments from a
--sequence to the end of the line.C-style comments from a
/*sequence to the following*/sequence, including over multiple lines.Multiple-line string literals enclosed within either single quote (
') or double quote (") characters.
If the server is started with the
--initializeor--initialize-insecureoption, it operates in bootstap mode and some functionality is unavailable that limits the statements permitted in the file. These include statements that relate to account management (such asCREATE USERorGRANT), replication, and global transaction identifiers. See Section 17.1.3, “Replication with Global Transaction Identifiers”.As of MySQL 8.0.17, threads created during server startup are used for tasks such as creating the data dictionary, running upgrade procedures, and creating system tables. To ensure a stable and predictable environment, these threads are executed with the server built-in defaults for some system variables, such as
sql_mode,character_set_server,collation_server,completion_type,explicit_defaults_for_timestamp, anddefault_table_encryption.These threads are also used to execute the statements in any file specified with
init_filewhen starting the server, so such statements execute with the server's built-in default values for those system variables. innodb_xxxInnoDBsystem variables are listed in Section 15.14, “InnoDB Startup Options and System Variables”. These variables control many aspects of storage, memory use, and I/O patterns forInnoDBtables, and are especially important now thatInnoDBis the default storage engine.The value to be used by the following
INSERTorALTER TABLEstatement when inserting anAUTO_INCREMENTvalue. This is mainly used with the binary log.-
Command-Line Format --interactive-timeout=#System Variable interactive_timeoutScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 28800Minimum Value 1The number of seconds the server waits for activity on an interactive connection before closing it. An interactive client is defined as a client that uses the
CLIENT_INTERACTIVEoption tomysql_real_connect(). See alsowait_timeout. internal_tmp_disk_storage_engineCommand-Line Format --internal-tmp-disk-storage-engine=#Removed 8.0.16 System Variable internal_tmp_disk_storage_engineScope Global Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value INNODBValid Values MYISAMINNODBImportantIn MySQL 8.0.16 and later, on-disk internal temporary tables always use the
InnoDBstorage engine; as of MySQL 8.0.16, this variable has been removed and is thus no longer supported.Prior to MySQL 8.0.16, this variable determines the storage engine used for on-disk internal temporary tables (see Storage Engine for On-Disk Internal Temporary Tables). Permitted values are
MYISAMandINNODB(the default).internal_tmp_mem_storage_engineCommand-Line Format --internal-tmp-mem-storage-engine=#System Variable internal_tmp_mem_storage_engineScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Enumeration Default Value TempTableValid Values TempTableMEMORYThe storage engine for in-memory internal temporary tables (see Section 8.4.4, “Internal Temporary Table Use in MySQL”). Permitted values are
TempTable(the default) andMEMORY.The optimizer uses the storage engine defined by
internal_tmp_mem_storage_enginefor in-memory internal temporary tables.-
Command-Line Format --join-buffer-size=#System Variable join_buffer_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 262144Minimum Value 128Maximum Value (Other, 64-bit platforms) 18446744073709547520Maximum Value (Other, 32-bit platforms) 4294967295Maximum Value (Windows) 4294967295The minimum size of the buffer that is used for plain index scans, range index scans, and joins that do not use indexes and thus perform full table scans. Normally, the best way to get fast joins is to add indexes. Increase the value of
join_buffer_sizeto get a faster full join when adding indexes is not possible. One join buffer is allocated for each full join between two tables. For a complex join between several tables for which indexes are not used, multiple join buffers might be necessary.Unless a Block Nested-Loop or Batched Key Access algorithm is used, there is no gain from setting the buffer larger than required to hold each matching row, and all joins allocate at least the minimum size, so use caution in setting this variable to a large value globally. It is better to keep the global setting small and change the session setting to a larger value only in sessions that are doing large joins, or change the setting on a per-query basis by using a
SET_VARoptimizer hint (see Section 8.9.3, “Optimizer Hints”). Memory allocation time can cause substantial performance drops if the global size is larger than needed by most queries that use it.When Block Nested-Loop is used, a larger join buffer can be beneficial up to the point where all required columns from all rows in the first table are stored in the join buffer. This depends on the query; the optimal size may be smaller than holding all rows from the first tables.
When Batched Key Access is used, the value of
join_buffer_sizedefines how large the batch of keys is in each request to the storage engine. The larger the buffer, the more sequential access is made to the right hand table of a join operation, which can significantly improve performance.The default is 256KB. The maximum permissible setting for
join_buffer_sizeis 4GB−1. Larger values are permitted for 64-bit platforms (except 64-bit Windows, for which large values are truncated to 4GB−1 with a warning).For additional information about join buffering, see Section 8.2.1.7, “Nested-Loop Join Algorithms”. For information about Batched Key Access, see Section 8.2.1.12, “Block Nested-Loop and Batched Key Access Joins”.
-
Command-Line Format --keep-files-on-create[={OFF|ON}]System Variable keep_files_on_createScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFIf a
MyISAMtable is created with noDATA DIRECTORYoption, the.MYDfile is created in the database directory. By default, ifMyISAMfinds an existing.MYDfile in this case, it overwrites it. The same applies to.MYIfiles for tables created with noINDEX DIRECTORYoption. To suppress this behavior, set thekeep_files_on_createvariable toON(1), in which caseMyISAMdoes not overwrite existing files and returns an error instead. The default value isOFF(0).If a
MyISAMtable is created with aDATA DIRECTORYorINDEX DIRECTORYoption and an existing.MYDor.MYIfile is found, MyISAM always returns an error. It does not overwrite a file in the specified directory. -
Command-Line Format --key-buffer-size=#System Variable key_buffer_sizeScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 8388608Minimum Value 8Maximum Value (64-bit platforms) OS_PER_PROCESS_LIMITMaximum Value (32-bit platforms) 4294967295Index blocks for
MyISAMtables are buffered and are shared by all threads.key_buffer_sizeis the size of the buffer used for index blocks. The key buffer is also known as the key cache.The maximum permissible setting for
key_buffer_sizeis 4GB−1 on 32-bit platforms. Larger values are permitted for 64-bit platforms. The effective maximum size might be less, depending on your available physical RAM and per-process RAM limits imposed by your operating system or hardware platform. The value of this variable indicates the amount of memory requested. Internally, the server allocates as much memory as possible up to this amount, but the actual allocation might be less.You can increase the value to get better index handling for all reads and multiple writes; on a system whose primary function is to run MySQL using the
MyISAMstorage engine, 25% of the machine's total memory is an acceptable value for this variable. However, you should be aware that, if you make the value too large (for example, more than 50% of the machine's total memory), your system might start to page and become extremely slow. This is because MySQL relies on the operating system to perform file system caching for data reads, so you must leave some room for the file system cache. You should also consider the memory requirements of any other storage engines that you may be using in addition toMyISAM.For even more speed when writing many rows at the same time, use
LOCK TABLES. See Section 8.2.5.1, “Optimizing INSERT Statements”.You can check the performance of the key buffer by issuing a
SHOW STATUSstatement and examining theKey_read_requests,Key_reads,Key_write_requests, andKey_writesstatus variables. (See Section 13.7.7, “SHOW Statements”.) TheKey_reads/Key_read_requestsratio should normally be less than 0.01. TheKey_writes/Key_write_requestsratio is usually near 1 if you are using mostly updates and deletes, but might be much smaller if you tend to do updates that affect many rows at the same time or if you are using theDELAY_KEY_WRITEtable option.The fraction of the key buffer in use can be determined using
key_buffer_sizein conjunction with theKey_blocks_unusedstatus variable and the buffer block size, which is available from thekey_cache_block_sizesystem variable:1 - ((Key_blocks_unused * key_cache_block_size) / key_buffer_size)
This value is an approximation because some space in the key buffer is allocated internally for administrative structures. Factors that influence the amount of overhead for these structures include block size and pointer size. As block size increases, the percentage of the key buffer lost to overhead tends to decrease. Larger blocks results in a smaller number of read operations (because more keys are obtained per read), but conversely an increase in reads of keys that are not examined (if not all keys in a block are relevant to a query).
It is possible to create multiple
MyISAMkey caches. The size limit of 4GB applies to each cache individually, not as a group. See Section 8.10.2, “The MyISAM Key Cache”. -
Command-Line Format --key-cache-age-threshold=#System Variable key_cache_age_thresholdScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 300Minimum Value 100Maximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295This value controls the demotion of buffers from the hot sublist of a key cache to the warm sublist. Lower values cause demotion to happen more quickly. The minimum value is 100. The default value is 300. See Section 8.10.2, “The MyISAM Key Cache”.
-
Command-Line Format --key-cache-block-size=#System Variable key_cache_block_sizeScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 1024Minimum Value 512Maximum Value 16384The size in bytes of blocks in the key cache. The default value is 1024. See Section 8.10.2, “The MyISAM Key Cache”.
-
Command-Line Format --key-cache-division-limit=#System Variable key_cache_division_limitScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 100Minimum Value 1Maximum Value 100The division point between the hot and warm sublists of the key cache buffer list. The value is the percentage of the buffer list to use for the warm sublist. Permissible values range from 1 to 100. The default value is 100. See Section 8.10.2, “The MyISAM Key Cache”.
-
System Variable large_files_supportScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Whether mysqld was compiled with options for large file support.
-
Command-Line Format --large-pages[={OFF|ON}]System Variable large_pagesScope Global Dynamic No SET_VARHint AppliesNo Platform Specific Linux Type Boolean Default Value OFFWhether large page support is enabled (via the
--large-pagesoption). See Section 8.12.3.2, “Enabling Large Page Support”. -
System Variable large_page_sizeScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 0If large page support is enabled, this shows the size of memory pages. Large memory pages are supported only on Linux; on other platforms, the value of this variable is always 0. See Section 8.12.3.2, “Enabling Large Page Support”.
The value to be returned from
LAST_INSERT_ID(). This is stored in the binary log when you useLAST_INSERT_ID()in a statement that updates a table. Setting this variable does not update the value returned by themysql_insert_id()C API function.-
Command-Line Format --lc-messages=nameSystem Variable lc_messagesScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String Default Value en_USThe locale to use for error messages. The default is
en_US. The server converts the argument to a language name and combines it with the value oflc_messages_dirto produce the location for the error message file. See Section 10.12, “Setting the Error Message Language”. -
Command-Line Format --lc-messages-dir=dir_nameSystem Variable lc_messages_dirScope Global Dynamic No SET_VARHint AppliesNo Type Directory name The directory where error messages are located. The server uses the value together with the value of
lc_messagesto produce the location for the error message file. See Section 10.12, “Setting the Error Message Language”. -
Command-Line Format --lc-time-names=valueSystem Variable lc_time_namesScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String This variable specifies the locale that controls the language used to display day and month names and abbreviations. This variable affects the output from the
DATE_FORMAT(),DAYNAME()andMONTHNAME()functions. Locale names are POSIX-style values such as'ja_JP'or'pt_BR'. The default value is'en_US'regardless of your system's locale setting. For further information, see Section 10.16, “MySQL Server Locale Support”. -
System Variable licenseScope Global Dynamic No SET_VARHint AppliesNo Type String Default Value GPLThe type of license the server has.
-
Command-Line Format --local-infile[={OFF|ON}]System Variable local_infileScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFThis variable controls server-side
LOCALcapability forLOAD DATAstatements. Depending on thelocal_infilesetting, the server refuses or permits local data loading by clients that haveLOCALenabled on the client side.To explicitly cause the server to refuse or permit
LOAD DATA LOCALstatements (regardless of how client programs and libraries are configured at build time or runtime), start mysqld withlocal_infiledisabled or enabled, respectively.local_infilecan also be set at runtime. For more information, see Section 6.1.6, “Security Considerations for LOAD DATA LOCAL”. -
Command-Line Format --lock-wait-timeout=#System Variable lock_wait_timeoutScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 31536000Minimum Value 1Maximum Value 31536000This variable specifies the timeout in seconds for attempts to acquire metadata locks. The permissible values range from 1 to 31536000 (1 year). The default is 31536000.
This timeout applies to all statements that use metadata locks. These include DML and DDL operations on tables, views, stored procedures, and stored functions, as well as
LOCK TABLES,FLUSH TABLES WITH READ LOCK, andHANDLERstatements.This timeout does not apply to implicit accesses to system tables in the
mysqldatabase, such as grant tables modified byGRANTorREVOKEstatements or table logging statements. The timeout does apply to system tables accessed directly, such as withSELECTorUPDATE.The timeout value applies separately for each metadata lock attempt. A given statement can require more than one lock, so it is possible for the statement to block for longer than the
lock_wait_timeoutvalue before reporting a timeout error. When lock timeout occurs,ER_LOCK_WAIT_TIMEOUTis reported.lock_wait_timeoutalso defines the amount of time that aLOCK INSTANCE FOR BACKUPstatement waits for a lock before giving up. -
System Variable locked_in_memoryScope Global Dynamic No SET_VARHint AppliesNo -
Command-Line Format --log-error[=file_name]System Variable log_errorScope Global Dynamic No SET_VARHint AppliesNo Type File name The default error log destination. If the destination is the console, the value is
stderr. Otherwise, the destination is a file and thelog_errorvalue is the file name. See Section 5.4.2, “The Error Log”. -
Command-Line Format --log-error-services=valueSystem Variable log_error_servicesScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value log_filter_internal; log_sink_internalThe components to enable for error logging. The variable may contain a list with 0, 1, or many elements. In the latter case, elements may be delimited by semicolon or (as of MySQL 8.0.12) comma, optionally followed by space. A given setting cannot use both semicolon and comma separators. Component order is significant because the server executes components in the order listed. Any loadable (not built in) component named in the
log_error_servicesvalue must first be installed withINSTALL COMPONENT. For more information, see Section 5.4.2.1, “Error Log Configuration”. -
Command-Line Format --log-error-suppression-list=valueIntroduced 8.0.13 System Variable log_error_suppression_listScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value empty stringThe
log_error_suppression_listsystem variable applies to events intended for the error log and specifies which events to suppress when they occur with a priority ofWARNINGorINFORMATION. For example, if a particular type of warning is considered undesirable “noise” in the error log because it occurs frequently but is not of interest, it can be suppressed. This variable affects filtering performed by thelog_filter_internalerror log filter component, which is enabled by default (see Section 5.5.3, “Error Log Components”). Iflog_filter_internalis disabled,log_error_suppression_listhas no effect.The
log_error_suppression_listvalue may be the empty string for no suppression, or a list of one or more comma-separated values indicating the error codes to suppress. Error codes may be specified in symbolic or numeric form. A numeric code may be specified with or without theMY-prefix. Leading zeros in the numeric part are not significant. Examples of permitted code formats:ER_SERVER_SHUTDOWN_COMPLETE MY-000031 000031 MY-31 31
Symbolic values are preferable to numeric values for readability and portability. For information about the permitted error symbols and numbers, see MySQL 8.0 Error Message Reference.
The effect of
log_error_suppression_listcombines with that oflog_error_verbosity. For additional information, see Section 5.4.2.5, “Priority-Based Error Log Filtering (log_filter_internal)”. -
Command-Line Format --log-error-verbosity=#System Variable log_error_verbosityScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 2Minimum Value 1Maximum Value 3The
log_error_verbositysystem variable specifies the verbosity for handling events intended for the error log. This variable affects filtering performed by thelog_filter_internalerror log filter component, which is enabled by default (see Section 5.5.3, “Error Log Components”). Iflog_filter_internalis disabled,log_error_verbosityhas no effect.Events intended for the error log have a priority of
ERROR,WARNING, orINFORMATION.log_error_verbositycontrols verbosity based on which priorities to permit for messages written to the log, as shown in the following table.log_error_verbosity Value Permitted Message Priorities 1 ERROR2 ERROR,WARNING3 ERROR,WARNING,INFORMATIONThere is also a priority of
SYSTEM. System messages about non-error situations are printed to the error log regardless of thelog_error_verbosityvalue. These messages include startup and shutdown messages, and some significant changes to settings.The effect of
log_error_verbositycombines with that oflog_error_suppression_list. For additional information, see Section 5.4.2.5, “Priority-Based Error Log Filtering (log_filter_internal)”. -
Command-Line Format --log-output=nameSystem Variable log_outputScope Global Dynamic Yes SET_VARHint AppliesNo Type Set Default Value FILEValid Values TABLEFILENONEThe destination or destinations for general query log and slow query log output. The value is a list one or more comma-separated words chosen from
TABLE,FILE, andNONE.TABLEselects logging to thegeneral_logandslow_logtables in themysqlsystem schema.FILEselects logging to log files.NONEdisables logging. IfNONEis present in the value, it takes precedence over any other words that are present.TABLEandFILEcan both be given to select both log output destinations.This variable selects log output destinations, but does not enable log output. To do that, enable the
general_logandslow_query_logsystem variables. ForFILElogging, thegeneral_log_fileandslow_query_log_filesystem variables determine the log file locations. For more information, see Section 5.4.1, “Selecting General Query Log and Slow Query Log Output Destinations”. -
Command-Line Format --log-queries-not-using-indexes[={OFF|ON}]System Variable log_queries_not_using_indexesScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFIf you enable this variable with the slow query log enabled, queries that are expected to retrieve all rows are logged. See Section 5.4.5, “The Slow Query Log”. This option does not necessarily mean that no index is used. For example, a query that uses a full index scan uses an index but would be logged because the index would not limit the number of rows.
-
Command-Line Format --log-raw[={OFF|ON}]System Variable (≥ 8.0.19) log_rawScope (≥ 8.0.19) Global Dynamic (≥ 8.0.19) Yes SET_VARHint Applies (≥ 8.0.19)No Type Boolean Default Value OFFThe
log_rawsystem variable is initially set to the value of the--log-rawoption. See the description of that option for more information. The system variable may also be set at runtime to change password masking behavior. -
Command-Line Format --log-slow-admin-statements[={OFF|ON}]System Variable log_slow_admin_statementsScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFInclude slow administrative statements in the statements written to the slow query log. Administrative statements include
ALTER TABLE,ANALYZE TABLE,CHECK TABLE,CREATE INDEX,DROP INDEX,OPTIMIZE TABLE, andREPAIR TABLE. -
Command-Line Format --log-slow-extra[={OFF|ON}]Introduced 8.0.14 System Variable log_slow_extraScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFIf the slow query log is enabled and the output destination includes
FILE, the server writes additional fields to log file lines that provide information about slow statements. See Section 5.4.5, “The Slow Query Log”.TABLEoutput is unaffected. -
Command-Line Format --log-syslog[={OFF|ON}]Deprecated Yes (removed in 8.0.13) System Variable log_syslogScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value ON(when error logging to system log is enabled)Prior to MySQL 8.0, this variable controlled whether to perform error logging to the system log (the Event Log on Windows, and
syslogon Unix and Unix-like systems).In MySQL 8.0, the
log_sink_syseventloglog component implements error logging to the system log (see Section 5.4.2.8, “Error Logging to the System Log”), so this type of logging can be enabled by adding that component to thelog_error_servicessystem variable.log_syslogis removed. (Prior to MySQL 8.0.13,log_syslogexists but is deprecated and has no effect.) -
Command-Line Format --log-syslog-facility=valueRemoved 8.0.13 System Variable log_syslog_facilityScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value daemonThis variable was removed in MySQL 8.0.13 and replaced by
syseventlog.facility. -
Command-Line Format --log-syslog-include-pid[={OFF|ON}]Removed 8.0.13 System Variable log_syslog_include_pidScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value ONThis variable was removed in MySQL 8.0.13 and replaced by
syseventlog.include_pid. -
Command-Line Format --log-syslog-tag=tagRemoved 8.0.13 System Variable log_syslog_tagScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value empty stringThis variable was removed in MySQL 8.0.13 and replaced by
syseventlog.tag. -
Command-Line Format --log-timestamps=#System Variable log_timestampsScope Global Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value UTCValid Values UTCSYSTEMThis variable controls the time zone of timestamps in messages written to the error log, and in general query log and slow query log messages written to files. It does not affect the time zone of general query log and slow query log messages written to tables (
mysql.general_log,mysql.slow_log). Rows retrieved from those tables can be converted from the local system time zone to any desired time zone withCONVERT_TZ()or by setting the sessiontime_zonesystem variable.Permitted
log_timestampsvalues areUTC(the default) andSYSTEM(the local system time zone).Timestamps are written using ISO 8601 / RFC 3339 format:
YYYY-MM-DDThh:mm:ss.uuuuuuZsignifying Zulu time (UTC) or±hh:mm(an offset from UTC). log_throttle_queries_not_using_indexesCommand-Line Format --log-throttle-queries-not-using-indexes=#System Variable log_throttle_queries_not_using_indexesScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0If
log_queries_not_using_indexesis enabled, thelog_throttle_queries_not_using_indexesvariable limits the number of such queries per minute that can be written to the slow query log. A value of 0 (the default) means “no limit”. For more information, see Section 5.4.5, “The Slow Query Log”.-
Command-Line Format --long-query-time=#System Variable long_query_timeScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Numeric Default Value 10Minimum Value 0If a query takes longer than this many seconds, the server increments the
Slow_queriesstatus variable. If the slow query log is enabled, the query is logged to the slow query log file. This value is measured in real time, not CPU time, so a query that is under the threshold on a lightly loaded system might be above the threshold on a heavily loaded one. The minimum and default values oflong_query_timeare 0 and 10, respectively. The value can be specified to a resolution of microseconds. See Section 5.4.5, “The Slow Query Log”.Smaller values of this variable result in more statements being considered long-running, with the result that more space is required for the slow query log. For very small values (less than one second), the log may grow quite large in a small time. Increasing the number of statements considered long-running may also result in false positives for the “excessive Number of Long Running Processes” alert in MySQL Enterprise Monitor, especially if Group Replication is enabled. For these reasons, very small values should be used in test environments only, or, in production environments, only for a short period.
-
Command-Line Format --low-priority-updates[={OFF|ON}]System Variable low_priority_updatesScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFIf set to
1, allINSERT,UPDATE,DELETE, andLOCK TABLE WRITEstatements wait until there is no pendingSELECTorLOCK TABLE READon the affected table. The same effect can be obtained using{INSERT | REPLACE | DELETE | UPDATE} LOW_PRIORITY ...to lower the priority of only one query. This variable affects only storage engines that use only table-level locking (such asMyISAM,MEMORY, andMERGE). See Section 8.11.2, “Table Locking Issues”. -
System Variable lower_case_file_systemScope Global Dynamic No SET_VARHint AppliesNo Type Boolean This variable describes the case sensitivity of file names on the file system where the data directory is located.
OFFmeans file names are case-sensitive,ONmeans they are not case-sensitive. This variable is read only because it reflects a file system attribute and setting it would have no effect on the file system. -
Command-Line Format --lower-case-table-names[=#]System Variable lower_case_table_namesScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 2If set to 0, table names are stored as specified and comparisons are case-sensitive. If set to 1, table names are stored in lowercase on disk and comparisons are not case-sensitive. If set to 2, table names are stored as given but compared in lowercase. This option also applies to database names and table aliases. For additional details, see Section 9.2.3, “Identifier Case Sensitivity”.
On Windows the default value is 1. On macOS, the default value is 2. On Linux, a value of 2 is not supported; the server forces the value to 0 instead.
You should not set
lower_case_table_namesto 0 if you are running MySQL on a system where the data directory resides on a case-insensitive file system (such as on Windows or macOS). It is an unsupported combination that could result in a hang condition when running anINSERT INTO ... SELECT ... FROMoperation with the wrongtbl_nametbl_namelettercase. WithMyISAM, accessing table names using different lettercases could cause index corruption.An error message is printed and the server exits if you attempt to start the server with
--lower_case_table_names=0on a case-insensitive file system.If you are using
InnoDBtables, you should set this variable to 1 on all platforms to force names to be converted to lowercase.The setting of this variable affects the behavior of replication filtering options with regard to case sensitivity. For more information, see Section 17.2.5, “How Servers Evaluate Replication Filtering Rules”.
It is prohibited to start the server with a
lower_case_table_namessetting that is different from the setting used when the server was initialized. The restriction is necessary because collations used by various data dictionary table fields are determined by the setting defined when the server is initialized, and restarting the server with a different setting would introduce inconsistencies with respect to how identifiers are ordered and compared.It is therefore necessary to configure
lower_case_table_namesto the desired setting before initializing the server. In most cases, this requires configuringlower_case_table_namesin a MySQL option file before starting the MySQL server for the first time. For APT installations on Debian and Ubuntu, however, the server is initialized for you, and there is no opportunity to configure the setting in an option file beforehand. You must therefore use thedebconf-set-selectionutility prior to installing MySQL using APT to enablelower_case_table_names. To do so, run this command before installing MySQL using APT:shell> sudo debconf-set-selections <<< "mysql-server mysql-server/lowercase-table-names select Enabled
NoteThe ability to enable
lower_case_table_namesusingdebconf-set-selectionswas added in MySQL 8.0.17. Enablinglower_case_table_namessets the value to 1. -
Command-Line Format --mandatory-roles=valueSystem Variable mandatory_rolesScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value empty stringRoles the server should treat as mandatory. In effect, these roles are automatically granted to every user, although setting
mandatory_rolesdoes not actually change any user accounts, and the granted roles are not visible in themysql.role_edgessystem table.The variable value is a comma-separated list of role names. Example:
SET PERSIST mandatory_roles = '`role1`@`%`,`role2`,role3,role4@localhost';
Setting the runtime value of
mandatory_rolesrequires theROLE_ADMINprivilege, in addition to theSYSTEM_VARIABLES_ADMINprivilege (or the deprecatedSUPERprivilege) normally required to set a global system variable runtime value.Role names consist of a user part and host part in
user_name@host_name%. For additional information, see Section 6.2.5, “Specifying Role Names”.The
mandatory_rolesvalue is a string, so user names and host names, if quoted, must be written in a fashion permitted for quoting within quoted strings.Roles named in the value of
mandatory_rolescannot be revoked withREVOKEor dropped withDROP ROLEorDROP USER.To prevent sessions from being made system sessions by default, a role that has the
SYSTEM_USERprivilege cannot be listed in the value of themandatory_rolessystem variable:If
mandatory_rolesis assigned a role at startup that has theSYSTEM_USERprivilege, the server writes a message to the error log and exits.If
mandatory_rolesis assigned a role at runtime that has theSYSTEM_USERprivilege, an error occurs and themandatory_rolesvalue remains unchanged.
Mandatory roles, like explicitly granted roles, do not take effect until activated (see Activating Roles). At login time, role activation occurs for all granted roles if the
activate_all_roles_on_loginsystem variable is enabled; otherwise, or for roles that are set as default roles otherwise. At runtime,SET ROLEactivates roles.Roles that do not exist when assigned to
mandatory_rolesbut are created later may require special treatment to be considered mandatory. For details, see Defining Mandatory Roles.SHOW GRANTSdisplays mandatory roles according to the rules described in Section 13.7.7.21, “SHOW GRANTS Statement”. -
Command-Line Format --max-allowed-packet=#System Variable max_allowed_packetScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 67108864Minimum Value 1024Maximum Value 1073741824The maximum size of one packet or any generated/intermediate string, or any parameter sent by the
mysql_stmt_send_long_data()C API function. The default is 64MB.The packet message buffer is initialized to
net_buffer_lengthbytes, but can grow up tomax_allowed_packetbytes when needed. This value by default is small, to catch large (possibly incorrect) packets.You must increase this value if you are using large
BLOBcolumns or long strings. It should be as big as the largestBLOByou want to use. The protocol limit formax_allowed_packetis 1GB. The value should be a multiple of 1024; nonmultiples are rounded down to the nearest multiple.When you change the message buffer size by changing the value of the
max_allowed_packetvariable, you should also change the buffer size on the client side if your client program permits it. The defaultmax_allowed_packetvalue built in to the client library is 1GB, but individual client programs might override this. For example, mysql and mysqldump have defaults of 16MB and 24MB, respectively. They also enable you to change the client-side value by settingmax_allowed_packeton the command line or in an option file.The session value of this variable is read only. The client can receive up to as many bytes as the session value. However, the server does not send to the client more bytes than the current global
max_allowed_packetvalue. (The global value could be less than the session value if the global value is changed after the client connects.) -
Command-Line Format --max-connect-errors=#System Variable max_connect_errorsScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 100Minimum Value 1Maximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295After
max_connect_errorssuccessive connection requests from a host are interrupted without a successful connection, the server blocks that host from further connections. If a connection from a host is established successfully within fewer thanmax_connect_errorsattempts after a previous connection was interrupted, the error count for the host is cleared to zero. To unblock blocked hosts, flush the host cache; see Flushing the Host Cache. -
Command-Line Format --max-connections=#System Variable max_connectionsScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 151Minimum Value 1Maximum Value 100000The maximum permitted number of simultaneous client connections. For more information, see Section 5.1.12.1, “Connection Interfaces”.
-
Command-Line Format --max-delayed-threads=#Deprecated Yes System Variable max_delayed_threadsScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 20Minimum Value 0Maximum Value 16384This system variable is deprecated (because
DELAYEDinserts are not supported); expect it to be removed in a future release. -
Command-Line Format --max-digest-length=#System Variable max_digest_lengthScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 1024Minimum Value 0Maximum Value 1048576The maximum number of bytes of memory reserved per session for computation of normalized statement digests. Once that amount of space is used during digest computation, truncation occurs: no further tokens from a parsed statement are collected or figure into its digest value. Statements that differ only after that many bytes of parsed tokens produce the same normalized statement digest and are considered identical if compared or if aggregated for digest statistics.
Decreasing the
max_digest_lengthvalue reduces memory use but causes the digest value of more statements to become indistinguishable if they differ only at the end. Increasing the value permits longer statements to be distinguished but increases memory use, particularly for workloads that involve large numbers of simultaneous sessions (the server allocatesmax_digest_lengthbytes per session).The parser uses this system variable as a limit on the maximum length of normalized statement digests that it computes. The Performance Schema, if it tracks statement digests, makes a copy of the digest value, using the
performance_schema_max_digest_length. system variable as a limit on the maximum length of digests that it stores. Consequently, ifperformance_schema_max_digest_lengthis less thanmax_digest_length, digest values stored in the Performance Schema are truncated relative to the original digest values.For more information about statement digesting, see Section 27.10, “Performance Schema Statement Digests and Sampling”.
-
Command-Line Format --max-error-count=#System Variable max_error_countScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 1024Minimum Value 0Maximum Value 65535The maximum number of error, warning, and information messages to be stored for display by the
SHOW ERRORSandSHOW WARNINGSstatements. This is the same as the number of condition areas in the diagnostics area, and thus the number of conditions that can be inspected byGET DIAGNOSTICS. -
Command-Line Format --max-execution-time=#System Variable max_execution_timeScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 0The execution timeout for
SELECTstatements, in milliseconds. If the value is 0, timeouts are not enabled.max_execution_timeapplies as follows:The global
max_execution_timevalue provides the default for the session value for new connections. The session value applies toSELECTexecutions executed within the session that include noMAX_EXECUTION_TIME(optimizer hint or for whichN)Nis 0.max_execution_timeapplies to read-onlySELECTstatements. Statements that are not read only are those that invoke a stored function that modifies data as a side effect.max_execution_timeis ignored forSELECTstatements in stored programs.
-
Command-Line Format --max-heap-table-size=#System Variable max_heap_table_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 16777216Minimum Value 16384Maximum Value (64-bit platforms) 1844674407370954752Maximum Value (32-bit platforms) 4294967295This variable sets the maximum size to which user-created
MEMORYtables are permitted to grow. The value of the variable is used to calculateMEMORYtableMAX_ROWSvalues. Setting this variable has no effect on any existingMEMORYtable, unless the table is re-created with a statement such asCREATE TABLEor altered withALTER TABLEorTRUNCATE TABLE. A server restart also sets the maximum size of existingMEMORYtables to the globalmax_heap_table_sizevalue.This variable is also used in conjunction with
tmp_table_sizeto limit the size of internal in-memory tables. See Section 8.4.4, “Internal Temporary Table Use in MySQL”.max_heap_table_sizeis not replicated. See Section 17.5.1.21, “Replication and MEMORY Tables”, and Section 17.5.1.39, “Replication and Variables”, for more information. -
Deprecated Yes System Variable max_insert_delayed_threadsScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer This variable is a synonym for
max_delayed_threads.This system variable is deprecated (because
DELAYEDinserts are not supported); expect it to be removed in a future release. -
Command-Line Format --max-join-size=#System Variable max_join_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 18446744073709551615Minimum Value 1Maximum Value 18446744073709551615Do not permit statements that probably need to examine more than
max_join_sizerows (for single-table statements) or row combinations (for multiple-table statements) or that are likely to do more thanmax_join_sizedisk seeks. By setting this value, you can catch statements where keys are not used properly and that would probably take a long time. Set it if your users tend to perform joins that lack aWHEREclause, that take a long time, or that return millions of rows. For more information, see Using Safe-Updates Mode (--safe-updates).Setting this variable to a value other than
DEFAULTresets the value ofsql_big_selectsto0. If you set thesql_big_selectsvalue again, themax_join_sizevariable is ignored. -
Command-Line Format --max-length-for-sort-data=#Deprecated 8.0.20 System Variable max_length_for_sort_dataScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 4096Minimum Value 4Maximum Value 8388608This variable is deprecated as of MySQL 8.0.20 due to optimizer changes that make it obsolete and of no effect. Previously, it acted as the cutoff on the size of index values that determines which
filesortalgorithm to use. See Section 8.2.1.16, “ORDER BY Optimization”. -
Command-Line Format --max-points-in-geometry=#System Variable max_points_in_geometryScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 65536Minimum Value 3Maximum Value 1048576The maximum value of the
points_per_circleargument to theST_Buffer_Strategy()function. -
Command-Line Format --max-prepared-stmt-count=#System Variable max_prepared_stmt_countScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 16382Minimum Value 0Maximum Value (≥ 8.0.18) 4194304Maximum Value (≤ 8.0.17) 1048576This variable limits the total number of prepared statements in the server. It can be used in environments where there is the potential for denial-of-service attacks based on running the server out of memory by preparing huge numbers of statements. If the value is set lower than the current number of prepared statements, existing statements are not affected and can be used, but no new statements can be prepared until the current number drops below the limit. Setting the value to 0 disables prepared statements.
-
Command-Line Format --max-seeks-for-key=#System Variable max_seeks_for_keyScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value (Other, 64-bit platforms) 18446744073709551615Default Value (Other, 32-bit platforms) 4294967295Default Value (Windows) 4294967295Minimum Value 1Maximum Value (Other, 64-bit platforms) 18446744073709551615Maximum Value (Other, 32-bit platforms) 4294967295Maximum Value (Windows) 4294967295Limit the assumed maximum number of seeks when looking up rows based on a key. The MySQL optimizer assumes that no more than this number of key seeks are required when searching for matching rows in a table by scanning an index, regardless of the actual cardinality of the index (see Section 13.7.7.22, “SHOW INDEX Statement”). By setting this to a low value (say, 100), you can force MySQL to prefer indexes instead of table scans.
-
Command-Line Format --max-sort-length=#System Variable max_sort_lengthScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 1024Minimum Value 4Maximum Value 8388608The number of bytes to use when sorting data values. The server uses only the first
max_sort_lengthbytes of each value and ignores the rest. Consequently, values that differ only after the firstmax_sort_lengthbytes compare as equal forGROUP BY,ORDER BY, andDISTINCToperations.Increasing the value of
max_sort_lengthmay require increasing the value ofsort_buffer_sizeas well. For details, see Section 8.2.1.16, “ORDER BY Optimization” -
Command-Line Format --max-sp-recursion-depth[=#]System Variable max_sp_recursion_depthScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Maximum Value 255The number of times that any given stored procedure may be called recursively. The default value for this option is 0, which completely disables recursion in stored procedures. The maximum value is 255.
Stored procedure recursion increases the demand on thread stack space. If you increase the value of
max_sp_recursion_depth, it may be necessary to increase thread stack size by increasing the value ofthread_stackat server startup. -
Command-Line Format --max-user-connections=#System Variable max_user_connectionsScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 4294967295The maximum number of simultaneous connections permitted to any given MySQL user account. A value of 0 (the default) means “no limit.”
This variable has a global value that can be set at server startup or runtime. It also has a read-only session value that indicates the effective simultaneous-connection limit that applies to the account associated with the current session. The session value is initialized as follows:
If the user account has a nonzero
MAX_USER_CONNECTIONSresource limit, the sessionmax_user_connectionsvalue is set to that limit.Otherwise, the session
max_user_connectionsvalue is set to the global value.
Account resource limits are specified using the
CREATE USERorALTER USERstatement. See Section 6.2.20, “Setting Account Resource Limits”. -
Command-Line Format --max-write-lock-count=#System Variable max_write_lock_countScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value (Other, 64-bit platforms) 18446744073709551615Default Value (Other, 32-bit platforms) 4294967295Default Value (Windows) 4294967295Minimum Value 1Maximum Value (Other, 64-bit platforms) 18446744073709551615Maximum Value (Other, 32-bit platforms) 4294967295Maximum Value (Windows) 4294967295After this many write locks, permit some pending read lock requests to be processed in between. Write lock requests have higher priority than read lock requests. However, if
max_write_lock_countis set to some low value (say, 10), read lock requests may be preferred over pending write lock requests if the read lock requests have already been passed over in favor of 10 write lock requests. Normally this behavior does not occur becausemax_write_lock_countby default has a very large value. -
Command-Line Format --mecab-rc-file=file_nameSystem Variable mecab_rc_fileScope Global Dynamic No SET_VARHint AppliesNo Type File name The
mecab_rc_fileoption is used when setting up the MeCab full-text parser.The
mecab_rc_fileoption defines the path to themecabrcconfiguration file, which is the configuration file for MeCab. The option is read-only and can only be set at startup. Themecabrcconfiguration file is required to initialize MeCab.For information about the MeCab full-text parser, see Section 12.10.9, “MeCab Full-Text Parser Plugin”.
For information about options that can be specified in the MeCab
mecabrcconfiguration file, refer to the MeCab Documentation on the Google Developers site. -
Command-Line Format --metadata-locks-cache-size=#Deprecated Yes (removed in 8.0.13) System Variable metadata_locks_cache_sizeScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 1024Minimum Value 1Maximum Value 1048576This system variable was removed in MySQL 8.0.13.
-
Command-Line Format --metadata-locks-hash-instances=#Deprecated Yes (removed in 8.0.13) System Variable metadata_locks_hash_instancesScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 8Minimum Value 1Maximum Value 1024This system variable was removed in MySQL 8.0.13.
-
Command-Line Format --min-examined-row-limit=#System Variable min_examined_row_limitScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295Queries that examine fewer than this number of rows are not logged to the slow query log.
-
Command-Line Format --myisam-data-pointer-size=#System Variable myisam_data_pointer_sizeScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 6Minimum Value 2Maximum Value 7The default pointer size in bytes, to be used by
CREATE TABLEforMyISAMtables when noMAX_ROWSoption is specified. This variable cannot be less than 2 or larger than 7. The default value is 6. See Section B.3.2.10, “The table is full”. -
Command-Line Format --myisam-max-sort-file-size=#System Variable myisam_max_sort_file_sizeScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value (Other, 64-bit platforms) 9223372036853727232Default Value (Other, 32-bit platforms) 2147483648Default Value (Windows) 2146435072Maximum Value (Other, 64-bit platforms) 9223372036853727232Maximum Value (Other, 32-bit platforms) 2147483648Maximum Value (Windows) 2146435072The maximum size of the temporary file that MySQL is permitted to use while re-creating a
MyISAMindex (duringREPAIR TABLE,ALTER TABLE, orLOAD DATA). If the file size would be larger than this value, the index is created using the key cache instead, which is slower. The value is given in bytes.If
MyISAMindex files exceed this size and disk space is available, increasing the value may help performance. The space must be available in the file system containing the directory where the original index file is located. -
Command-Line Format --myisam-mmap-size=#System Variable myisam_mmap_sizeScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value (64-bit platforms) 18446744073709551615Default Value (32-bit platforms) 4294967295Minimum Value 7Maximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295The maximum amount of memory to use for memory mapping compressed
MyISAMfiles. If many compressedMyISAMtables are used, the value can be decreased to reduce the likelihood of memory-swapping problems. -
Command-Line Format --myisam-recover-options[=list]System Variable myisam_recover_optionsScope Global Dynamic No SET_VARHint AppliesNo Type Enumeration Default Value OFFValid Values OFFDEFAULTBACKUPFORCEQUICKSet the
MyISAMstorage engine recovery mode. The variable value is any combination of the values ofOFF,DEFAULT,BACKUP,FORCE, orQUICK. If you specify multiple values, separate them by commas. Specifying the variable with no value at server startup is the same as specifyingDEFAULT, and specifying with an explicit value of""disables recovery (same as a value ofOFF). If recovery is enabled, each time mysqld opens aMyISAMtable, it checks whether the table is marked as crashed or was not closed properly. (The last option works only if you are running with external locking disabled.) If this is the case, mysqld runs a check on the table. If the table was corrupted, mysqld attempts to repair it.The following options affect how the repair works.
Option Description OFFNo recovery. DEFAULTRecovery without backup, forcing, or quick checking. BACKUPIf the data file was changed during recovery, save a backup of the tbl_name.MYDtbl_name-datetime.BAKFORCERun recovery even if we would lose more than one row from the .MYDfile.QUICKDo not check the rows in the table if there are not any delete blocks. Before the server automatically repairs a table, it writes a note about the repair to the error log. If you want to be able to recover from most problems without user intervention, you should use the options
BACKUP,FORCE. This forces a repair of a table even if some rows would be deleted, but it keeps the old data file as a backup so that you can later examine what happened. -
Command-Line Format --myisam-repair-threads=#System Variable myisam_repair_threadsScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 1Minimum Value 1Maximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295If this value is greater than 1,
MyISAMtable indexes are created in parallel (each index in its own thread) during theRepair by sortingprocess. The default value is 1.NoteMultithreaded repair is still beta-quality code.
-
Command-Line Format --myisam-sort-buffer-size=#System Variable myisam_sort_buffer_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 8388608Minimum Value 4096Maximum Value (Other, 64-bit platforms) 18446744073709551615Maximum Value (Other, 32-bit platforms) 4294967295Maximum Value (Windows, 64-bit platforms) 18446744073709551615Maximum Value (Windows, 32-bit platforms) 4294967295The size of the buffer that is allocated when sorting
MyISAMindexes during aREPAIR TABLEor when creating indexes withCREATE INDEXorALTER TABLE. -
Command-Line Format --myisam-stats-method=nameSystem Variable myisam_stats_methodScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value nulls_unequalValid Values nulls_equalnulls_unequalnulls_ignoredHow the server treats
NULLvalues when collecting statistics about the distribution of index values forMyISAMtables. This variable has three possible values,nulls_equal,nulls_unequal, andnulls_ignored. Fornulls_equal, allNULLindex values are considered equal and form a single value group that has a size equal to the number ofNULLvalues. Fornulls_unequal,NULLvalues are considered unequal, and eachNULLforms a distinct value group of size 1. Fornulls_ignored,NULLvalues are ignored.The method that is used for generating table statistics influences how the optimizer chooses indexes for query execution, as described in Section 8.3.8, “InnoDB and MyISAM Index Statistics Collection”.
-
Command-Line Format --myisam-use-mmap[={OFF|ON}]System Variable myisam_use_mmapScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFUse memory mapping for reading and writing
MyISAMtables. mysql_native_password_proxy_usersCommand-Line Format --mysql-native-password-proxy-users[={OFF|ON}]System Variable mysql_native_password_proxy_usersScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFThis variable controls whether the
mysql_native_passwordbuilt-in authentication plugin supports proxy users. It has no effect unless thecheck_proxy_userssystem variable is enabled. For information about user proxying, see Section 6.2.18, “Proxy Users”.-
Command-Line Format --named-pipe[={OFF|ON}]System Variable named_pipeScope Global Dynamic No SET_VARHint AppliesNo Platform Specific Windows Type Boolean Default Value OFF(Windows only.) Indicates whether the server supports connections over named pipes.
-
Command-Line Format --named-pipe-full-access-group=valueIntroduced 8.0.14 System Variable named_pipe_full_access_groupScope Global Dynamic No SET_VARHint AppliesNo Platform Specific Windows Type String Default Value *everyone*Valid Values *everyone*empty string(Windows only.) The access control granted to clients on the named pipe created by the MySQL server is set to the minimum necessary for successful communication when the
named_pipesystem variable is enabled to support named-pipe connections. Newer MySQL client software can open named pipe connections without any additional configuration, however, older client software may still require full access to open a named pipe connection.This variable sets the name of a Windows local group whose members are granted sufficient access by the MySQL server to use older named-pipe clients. Initially, the value is set to
'*everyone*'by default, which permits users of the Everyone group on Windows to continue using older clients until the older clients are upgraded. In contrast, setting the value to an empty string means that no Windows user is granted full access to the named pipe. The default value'*everyone*'provides a language-independent way of referring to the Everyone group on Windows.Ideally, a new Windows local group name (for example,
mysql_old_client_users) should be created in Windows and then used to replace the default value for this variable when access to older client software is absolutely necessary. In this case, limit the membership of the group to as few users as possible, removing users from the group when their client software is upgraded. A non-member of the group who attempts to open a connection to MySQL with the older named-pipe client is denied access until the user is added to the group by a Windows administrator, and then the user logs out and logs in (required by Windows). -
Command-Line Format --net-buffer-length=#System Variable net_buffer_lengthScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 16384Minimum Value 1024Maximum Value 1048576Each client thread is associated with a connection buffer and result buffer. Both begin with a size given by
net_buffer_lengthbut are dynamically enlarged up tomax_allowed_packetbytes as needed. The result buffer shrinks tonet_buffer_lengthafter each SQL statement.This variable should not normally be changed, but if you have very little memory, you can set it to the expected length of statements sent by clients. If statements exceed this length, the connection buffer is automatically enlarged. The maximum value to which
net_buffer_lengthcan be set is 1MB.The session value of this variable is read only.
-
Command-Line Format --net-read-timeout=#System Variable net_read_timeoutScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 30Minimum Value 1The number of seconds to wait for more data from a connection before aborting the read. When the server is reading from the client,
net_read_timeoutis the timeout value controlling when to abort. When the server is writing to the client,net_write_timeoutis the timeout value controlling when to abort. See alsoslave_net_timeout. -
Command-Line Format --net-retry-count=#System Variable net_retry_countScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 10Minimum Value 1Maximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295If a read or write on a communication port is interrupted, retry this many times before giving up. This value should be set quite high on FreeBSD because internal interrupts are sent to all threads.
-
Command-Line Format --net-write-timeout=#System Variable net_write_timeoutScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 60Minimum Value 1The number of seconds to wait for a block to be written to a connection before aborting the write. See also
net_read_timeout. -
Command-Line Format --new[={OFF|ON}]System Variable newScope Global, Session Dynamic Yes SET_VARHint AppliesNo Disabled by skip-newType Boolean Default Value OFFThis variable was used in MySQL 4.0 to turn on some 4.1 behaviors, and is retained for backward compatibility. Its value is always
OFF.In NDB Cluster, setting this variable to
ONmakes it possible to employ partitioning types other thanKEYorLINEAR KEYwithNDBtables. This feature is experimental only, and not supported in production. For additional information, see User-defined partitioning and the NDB storage engine (NDB Cluster). -
Command-Line Format --ngram-token-size=#System Variable ngram_token_sizeScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 2Minimum Value 1Maximum Value 10Defines the n-gram token size for the n-gram full-text parser. The
ngram_token_sizeoption is read-only and can only be modified at startup. The default value is 2 (bigram). The maximum value is 10.For more information about how to configure this variable, see Section 12.10.8, “ngram Full-Text Parser”.
-
Command-Line Format --offline-mode[={OFF|ON}]System Variable offline_modeScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFWhether the server is in “offline mode”, which has these characteristics:
Connected client users who do not have the
CONNECTION_ADMINprivilege (or the deprecatedSUPERprivilege) are disconnected on the next request, with an appropriate error. Disconnection includes terminating running statements and releasing locks. Such clients also cannot initiate new connections, and receive an appropriate error.Connected client users who have the
CONNECTION_ADMINorSUPERprivilege are not disconnected, and can initiate new connections to manage the server.Replication threads are permitted to keep applying data to the server.
Only users who have the
SYSTEM_VARIABLES_ADMINorSUPERprivilege can control offline mode. To put a server in offline mode, change the value of theoffline_modesystem variable fromOFFtoON. To resume normal operations, changeoffline_modefromONtoOFF. In offline mode, clients that are refused access receive anER_SERVER_OFFLINE_MODEerror. -
Command-Line Format --old[={OFF|ON}]System Variable oldScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value OFFoldis a compatibility variable. It is disabled by default, but can be enabled at startup to revert the server to behaviors present in older versions.When
oldis enabled, it changes the default scope of index hints to that used prior to MySQL 5.1.17. That is, index hints with noFORclause apply only to how indexes are used for row retrieval and not to resolution ofORDER BYorGROUP BYclauses. (See Section 8.9.4, “Index Hints”.) Take care about enabling this in a replication setup. With statement-based binary logging, having different modes for the source and replicas might lead to replication errors. -
Command-Line Format --old-alter-table[={OFF|ON}]System Variable old_alter_tableScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFWhen this variable is enabled, the server does not use the optimized method of processing an
ALTER TABLEoperation. It reverts to using a temporary table, copying over the data, and then renaming the temporary table to the original, as used by MySQL 5.0 and earlier. For more information on the operation ofALTER TABLE, see Section 13.1.9, “ALTER TABLE Statement”.ALTER TABLE ... DROP PARTITIONwithold_alter_table=ONrebuilds the partitioned table and attempts to move data from the dropped partition to another partition with a compatiblePARTITION ... VALUESdefinition. Data that cannot be moved to another partition is deleted. In earlier releases,ALTER TABLE ... DROP PARTITIONwithold_alter_table=ONdeletes data stored in the partition and drops the partition. -
Command-Line Format --open-files-limit=#System Variable open_files_limitScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 5000, with possible adjustmentMinimum Value 0Maximum Value platform dependentThe number of file descriptors available to mysqld from the operating system:
At startup, mysqld reserves descriptors with
setrlimit(), using the value requested at by setting this variable directly or by using the--open-files-limitoption to mysqld_safe. If mysqld produces the errorToo many open files, try increasing theopen_files_limitvalue. Internally, the maximum value for this variable is the maximum unsigned integer value, but the actual maximum is platform dependent.At runtime, the value of
open_files_limitindicates the number of file descriptors actually permitted to mysqld by the operating system, which might differ from the value requested at startup. If the number of file descriptors requested during startup cannot be allocated, mysqld writes a warning to the error log.
The effective
open_files_limitvalue is based on the value specified at system startup (if any) and the values ofmax_connectionsandtable_open_cache, using these formulas:10 + max_connections + (table_open_cache * 2)max_connections * 5MySQL 8.0.19 and higher: The operating system limit.
Prior to MySQL 8.0.19:
The operating system limit if that limit is positive but not Infinity.
If the operating system limit is Infinity:
open_files_limitvalue if specified at startup, 5000 if not.
The server attempts to obtain the number of file descriptors using the maximum of those values, capped to the maximum unsigned integer value. If that many descriptors cannot be obtained, the server attempts to obtain as many as the system permits.
The effective value is 0 on systems where MySQL cannot change the number of open files.
On Unix, the value cannot be set greater than the value displayed by the ulimit -n command.
-
Command-Line Format --optimizer-prune-level=#System Variable optimizer_prune_levelScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 1Minimum Value 0Maximum Value 1Controls the heuristics applied during query optimization to prune less-promising partial plans from the optimizer search space. A value of 0 disables heuristics so that the optimizer performs an exhaustive search. A value of 1 causes the optimizer to prune plans based on the number of rows retrieved by intermediate plans.
-
Command-Line Format --optimizer-search-depth=#System Variable optimizer_search_depthScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 62Minimum Value 0Maximum Value 62The maximum depth of search performed by the query optimizer. Values larger than the number of relations in a query result in better query plans, but take longer to generate an execution plan for a query. Values smaller than the number of relations in a query return an execution plan quicker, but the resulting plan may be far from being optimal. If set to 0, the system automatically picks a reasonable value.
-
Command-Line Format --optimizer-switch=valueSystem Variable optimizer_switchScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Set Valid Values (≥ 8.0.22) batched_key_access={on|off}block_nested_loop={on|off}condition_fanout_filter={on|off}derived_condition_pushdown={on|off}derived_merge={on|off}duplicateweedout={on|off}engine_condition_pushdown={on|off}firstmatch={on|off}hash_join={on|off}index_condition_pushdown={on|off}index_merge={on|off}index_merge_intersection={on|off}index_merge_sort_union={on|off}index_merge_union={on|off}loosescan={on|off}materialization={on|off}mrr={on|off}mrr_cost_based={on|off}prefer_ordering_index={on|off}semijoin={on|off}skip_scan={on|off}subquery_materialization_cost_based={on|off}use_index_extensions={on|off}use_invisible_indexes={on|off}Valid Values (≥ 8.0.21) batched_key_access={on|off}block_nested_loop={on|off}condition_fanout_filter={on|off}derived_merge={on|off}duplicateweedout={on|off}engine_condition_pushdown={on|off}firstmatch={on|off}hash_join={on|off}index_condition_pushdown={on|off}index_merge={on|off}index_merge_intersection={on|off}index_merge_sort_union={on|off}index_merge_union={on|off}loosescan={on|off}materialization={on|off}mrr={on|off}mrr_cost_based={on|off}prefer_ordering_index={on|off}semijoin={on|off}skip_scan={on|off}subquery_materialization_cost_based={on|off}use_index_extensions={on|off}use_invisible_indexes={on|off}Valid Values (≥ 8.0.18) batched_key_access={on|off}block_nested_loop={on|off}condition_fanout_filter={on|off}derived_merge={on|off}duplicateweedout={on|off}engine_condition_pushdown={on|off}firstmatch={on|off}hash_join={on|off}index_condition_pushdown={on|off}index_merge={on|off}index_merge_intersection={on|off}index_merge_sort_union={on|off}index_merge_union={on|off}loosescan={on|off}materialization={on|off}mrr={on|off}mrr_cost_based={on|off}semijoin={on|off}skip_scan={on|off}subquery_materialization_cost_based={on|off}use_index_extensions={on|off}use_invisible_indexes={on|off}Valid Values (≥ 8.0.13) batched_key_access={on|off}block_nested_loop={on|off}condition_fanout_filter={on|off}derived_merge={on|off}duplicateweedout={on|off}engine_condition_pushdown={on|off}firstmatch={on|off}index_condition_pushdown={on|off}index_merge={on|off}index_merge_intersection={on|off}index_merge_sort_union={on|off}index_merge_union={on|off}loosescan={on|off}materialization={on|off}mrr={on|off}mrr_cost_based={on|off}semijoin={on|off}skip_scan={on|off}subquery_materialization_cost_based={on|off}use_index_extensions={on|off}use_invisible_indexes={on|off}Valid Values (≤ 8.0.12) batched_key_access={on|off}block_nested_loop={on|off}condition_fanout_filter={on|off}derived_merge={on|off}duplicateweedout={on|off}engine_condition_pushdown={on|off}firstmatch={on|off}index_condition_pushdown={on|off}index_merge={on|off}index_merge_intersection={on|off}index_merge_sort_union={on|off}index_merge_union={on|off}loosescan={on|off}materialization={on|off}mrr={on|off}mrr_cost_based={on|off}semijoin={on|off}subquery_materialization_cost_based={on|off}use_index_extensions={on|off}use_invisible_indexes={on|off}The
optimizer_switchsystem variable enables control over optimizer behavior. The value of this variable is a set of flags, each of which has a value ofonoroffto indicate whether the corresponding optimizer behavior is enabled or disabled. This variable has global and session values and can be changed at runtime. The global default can be set at server startup.To see the current set of optimizer flags, select the variable value:
mysql>
SELECT @@optimizer_switch\G*************************** 1. row *************************** @@optimizer_switch: index_merge=on,index_merge_union=on, index_merge_sort_union=on,index_merge_intersection=on, engine_condition_pushdown=on,index_condition_pushdown=on, mrr=on,mrr_cost_based=on,block_nested_loop=on, batched_key_access=off,materialization=on,semijoin=on, loosescan=on,firstmatch=on,duplicateweedout=on, subquery_materialization_cost_based=on, use_index_extensions=on,condition_fanout_filter=on, derived_merge=on,use_invisible_indexes=off,skip_scan=on, hash_join=on,subquery_to_derived=off, prefer_ordering_index=on,hypergraph_optimizer=off, derived_condition_pushdown=onFor more information about the syntax of this variable and the optimizer behaviors that it controls, see Section 8.9.2, “Switchable Optimizations”.
-
Command-Line Format --optimizer-trace=valueSystem Variable optimizer_traceScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String This variable controls optimizer tracing. For details, see MySQL Internals: Tracing the Optimizer.
-
Command-Line Format --optimizer-trace-features=valueSystem Variable optimizer_trace_featuresScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String This variable enables or disables selected optimizer tracing features. For details, see MySQL Internals: Tracing the Optimizer.
-
Command-Line Format --optimizer-trace-limit=#System Variable optimizer_trace_limitScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 1The maximum number of optimizer traces to display. For details, see MySQL Internals: Tracing the Optimizer.
-
Command-Line Format --optimizer-trace-max-mem-size=#System Variable optimizer_trace_max_mem_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 1048576The maximum cumulative size of stored optimizer traces. For details, see MySQL Internals: Tracing the Optimizer.
-
Command-Line Format --optimizer-trace-offset=#System Variable optimizer_trace_offsetScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value -1The offset of optimizer traces to display. For details, see MySQL Internals: Tracing the Optimizer.
performance_schema_xxxPerformance Schema system variables are listed in Section 27.15, “Performance Schema System Variables”. These variables may be used to configure Performance Schema operation.
-
Command-Line Format --parser-max-mem-size=#System Variable parser_max_mem_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value (64-bit platforms) 18446744073709551615Default Value (32-bit platforms) 4294967295Minimum Value 10000000Maximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295The maximum amount of memory available to the parser. The default value places no limit on memory available. The value can be reduced to protect against out-of-memory situations caused by parsing long or complex SQL statements.
-
Command-Line Format --partial-revokes[={OFF|ON}]Introduced 8.0.16 System Variable partial_revokesScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFF(if partial revokes do not exist)ON(if partial revokes exist)Enabling this variable makes it possible to revoke privileges partially. Specifically, for users who have privileges at the global level,
partial_revokesenables privileges for specific schemas to be revoked while leaving the privileges in place for other schemas. For example, a user who has the globalUPDATEprivilege can be restricted from exercising this privilege on themysqlsystem schema. (Or, stated another way, the user is enabled to exercise theUPDATEprivilege on all schemas except themysqlschema.) In this sense, the user's globalUPDATEprivilege is partially revoked.Once enabled,
partial_revokescannot be disabled if any account has privilege restrictions. If any such account exists, disablingpartial_revokesfails:For attempts to disable
partial_revokesat startup, the server logs an error message and enablespartial_revokes.For attempts to disable
partial_revokesat runtime, an error occurs and thepartial_revokesvalue remains unchanged.
To disable
partial_revokesin this case, first modify each account that has partially revoked privileges, either by re-granting the privileges or by removing the account.For more information, including instructions for removing partial revokes, see Section 6.2.12, “Privilege Restriction Using Partial Revokes”.
-
Command-Line Format --password-history=#System Variable password_historyScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 4294967295This variable defines the global policy for controlling reuse of previous passwords based on required minimum number of password changes. For an account password used previously, this variable indicates the number of subsequent account password changes that must occur before the password can be reused. If the value is 0 (the default), there is no reuse restriction based on number of password changes.
Changes to this variable apply immediately to all accounts defined with the
PASSWORD HISTORY DEFAULToption.The global number-of-changes password reuse policy can be overridden as desired for individual accounts using the
PASSWORD HISTORYoption of theCREATE USERandALTER USERstatements. See Section 6.2.15, “Password Management”. -
Command-Line Format --password-require-current[={OFF|ON}]Introduced 8.0.13 System Variable password_require_currentScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFThis variable defines the global policy for controlling whether attempts to change an account password must specify the current password to be replaced.
Changes to this variable apply immediately to all accounts defined with the
PASSWORD REQUIRE CURRENT DEFAULToption.The global verification-required policy can be overridden as desired for individual accounts using the
PASSWORD REQUIREoption of theCREATE USERandALTER USERstatements. See Section 6.2.15, “Password Management”. -
Command-Line Format --password-reuse-interval=#System Variable password_reuse_intervalScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 4294967295This variable defines the global policy for controlling reuse of previous passwords based on time elapsed. For an account password used previously, this variable indicates the number of days that must pass before the password can be reused. If the value is 0 (the default), there is no reuse restriction based on time elapsed.
Changes to this variable apply immediately to all accounts defined with the
PASSWORD REUSE INTERVAL DEFAULToption.The global time-elapsed password reuse policy can be overridden as desired for individual accounts using the
PASSWORD REUSE INTERVALoption of theCREATE USERandALTER USERstatements. See Section 6.2.15, “Password Management”. -
Command-Line Format --persisted-globals-load[={OFF|ON}]System Variable persisted_globals_loadScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value ONWhether to load persisted configuration settings from the
mysqld-auto.cnffile in the data directory. The server normally processes this file at startup after all other option files (see Section 4.2.2.2, “Using Option Files”). Disablingpersisted_globals_loadcauses the server startup sequence to skipmysqld-auto.cnf.To modify the contents of
mysqld-auto.cnf, use theSET PERSIST,SET PERSIST_ONLY, andRESET PERSISTstatements. See Section 5.1.9.3, “Persisted System Variables”. persist_only_admin_x509_subjectCommand-Line Format --persist-only-admin-x509-subject=stringIntroduced 8.0.14 System Variable persist_only_admin_x509_subjectScope Global Dynamic No SET_VARHint AppliesNo Type String Default Value empty stringSET PERSISTandSET PERSIST_ONLYenable system variables to be persisted to themysqld-auto.cnfoption file in the data directory (see Section 13.7.6.1, “SET Syntax for Variable Assignment”). Persisting system variables enables runtime configuration changes that affect subsequent server restarts, which is convenient for remote administration not requiring direct access to MySQL server host option files. However, some system variables are nonpersistible or can be persisted only under certain restrictive conditions.The
persist_only_admin_x509_subjectsystem variable specifies the SSL certificate X.509 Subject value that users must have to be able to persist system variables that are persist-restricted. The default value is the empty string, which disables the Subject check so that persist-restricted system variables cannot be persisted by any user.If
persist_only_admin_x509_subjectis nonempty, users who connect to the server using an encrypted connection and supply an SSL certificate with the designated Subject value then can useSET PERSIST_ONLYto persist persist-restricted system variables. For information about persist-restricted system variables and instructions for configuring MySQL to enablepersist_only_admin_x509_subject, see Section 5.1.9.4, “Nonpersistible and Persist-Restricted System Variables”.-
Command-Line Format --pid-file=file_nameSystem Variable pid_fileScope Global Dynamic No SET_VARHint AppliesNo Type File name The path name of the file in which the server writes its process ID. The server creates the file in the data directory unless an absolute path name is given to specify a different directory. If you specify this variable, you must specify a value. If you do not specify this variable, MySQL uses a default value of
host_name.pidhost_nameis the name of the host machine.The process ID file is used by other programs such as mysqld_safe to determine the server's process ID. On Windows, this variable also affects the default error log file name. See Section 5.4.2, “The Error Log”.
-
Command-Line Format --plugin-dir=dir_nameSystem Variable plugin_dirScope Global Dynamic No SET_VARHint AppliesNo Type Directory name Default Value BASEDIR/lib/pluginThe path name of the plugin directory.
If the plugin directory is writable by the server, it may be possible for a user to write executable code to a file in the directory using
SELECT ... INTO DUMPFILE. This can be prevented by makingplugin_dirread only to the server or by settingsecure_file_privto a directory whereSELECTwrites can be made safely. -
Command-Line Format --port=port_numSystem Variable portScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 3306Minimum Value 0Maximum Value 65535The number of the port on which the server listens for TCP/IP connections. This variable can be set with the
--portoption. -
Command-Line Format --preload-buffer-size=#System Variable preload_buffer_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 32768Minimum Value 1024Maximum Value 1073741824The size of the buffer that is allocated when preloading indexes.
-
Command-Line Format --print-identified-with-as-hex[={OFF|ON}]Introduced 8.0.17 System Variable print_identified_with_as_hexScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFPassword hash values displayed in the
IDENTIFIED WITHclause of output fromSHOW CREATE USERmay contain unprintable characters that have adverse effects on terminal displays and in other environments. Enablingprint_identified_with_as_hexcausesSHOW CREATE USERto display such hash values as hexadecimal strings rather than as regular string literals. Hash values that do not contain unprintable characters still display as regular string literals, even with this variable enabled. If set to 0 or
OFF(the default), statement profiling is disabled. If set to 1 orON, statement profiling is enabled and theSHOW PROFILEandSHOW PROFILESstatements provide access to profiling information. See Section 13.7.7.31, “SHOW PROFILES Statement”.This variable is deprecated; expect it to be removed in a future MySQL release.
The number of statements for which to maintain profiling information if
profilingis enabled. The default value is 15. The maximum value is 100. Setting the value to 0 effectively disables profiling. See Section 13.7.7.31, “SHOW PROFILES Statement”.This variable is deprecated; expect it to be removed in a future MySQL release.
protocol_compression_algorithmsCommand-Line Format --protocol-compression-algorithms=valueIntroduced 8.0.18 System Variable protocol_compression_algorithmsScope Global Dynamic Yes SET_VARHint AppliesNo Type Set Default Value zlib,zstd,uncompressedValid Values zlibzstduncompressedThe compression algorithms that the server permits for incoming connections. These include connections by client programs and by servers participating in source/replica replication or Group Replication. Compression does not apply to connections for
FEDERATEDtables.protocol_compression_algorithmsdoes not control connection compression for X Protocol. See Section 20.5.5, “Connection Compression with X Plugin” for information on how this operates.The variable value is a list of one or more comma-separated compression algorithm names, in any order, chosen from the following items (not case-sensitive):
zlib: Permit connections that use thezlibcompression algorithm.zstd: Permit connections that use thezstdcompression algorithm (zstd 1.3).uncompressed: Permit uncompressed connections. If this algorithm name is not included in theprotocol_compression_algorithmsvalue, the server does not permit uncompressed connections. It permits only compressed connections that use whichever other algorithms are specified in the value, and there is no fallback to uncompressed connections.
The default value of
zlib,zstd,uncompressedindicates that the server permits all compression algorithms.For more information, see Section 4.2.8, “Connection Compression Control”.
-
System Variable protocol_versionScope Global Dynamic No SET_VARHint AppliesNo Type Integer The version of the client/server protocol used by the MySQL server.
-
System Variable proxy_userScope Session Dynamic No SET_VARHint AppliesNo Type String If the current client is a proxy for another user, this variable is the proxy user account name. Otherwise, this variable is
NULL. See Section 6.2.18, “Proxy Users”. -
System Variable pseudo_slave_modeScope Session Dynamic Yes SET_VARHint AppliesNo Type Boolean This system variable is for internal server use.
pseudo_slave_modeassists with the correct handling of transactions that originated on older or newer servers than the server currently processing them. mysqlbinlog sets the value ofpseudo_slave_modeto true before executing any SQL statements.Setting the session value of this system variable is a restricted operation. The session user must have either the
REPLICATION_APPLIERprivilege (see Section 17.3.3, “Replication Privilege Checks”), or privileges sufficient to set restricted session variables (see Section 5.1.9.1, “System Variable Privileges”). However, note that the variable is not intended for users to set; it is set automatically by the replication infrastructure.pseudo_slave_modehas the following effects on the handling of prepared XA transactions, which can be attached to or detached from the handling session (by default, the session that issuesXA START):If true, and the handling session has executed an internal-use
BINLOGstatement, XA transactions are automatically detached from the session as soon as the first part of the transaction up toXA PREPAREfinishes, so they can be committed or rolled back by any session that has theXA_RECOVER_ADMINprivilege.If false, XA transactions remain attached to the handling session as long as that session is alive, during which time no other session can commit the transaction. The prepared transaction is only detached if the session disconnects or the server restarts.
pseudo_slave_modehas the following effects on theoriginal_commit_timestampreplication delay timestamp and theoriginal_server_versionsystem variable:If true, transactions that do not explicitly set
original_commit_timestampororiginal_server_versionare assumed to originate on another, unknown server, so the value 0, meaning unknown, is assigned to both the timestamp and the system variable.If false, transactions that do not explicitly set
original_commit_timestampororiginal_server_versionare assumed to originate on the current server, so the current timestamp and the current server's version are assigned to the timestamp and the system variable.
In MySQL 8.0.14 and later,
pseudo_slave_modehas the following effects on the handling of a statement that sets one or more unsupported (removed or unknown) SQL modes:If true, the server ignores the unsupported mode and raises a warning.
If false, the server rejects the statement with
ER_UNSUPPORTED_SQL_MODE.
-
System Variable pseudo_thread_idScope Session Dynamic Yes SET_VARHint AppliesNo Type Integer This variable is for internal server use.
WarningChanging the session value of the
pseudo_thread_idsystem variable changes the value returned by theCONNECTION_ID()function.As of MySQL 8.0.14, setting the session value of this system variable is a restricted operation. The session user must have privileges sufficient to set restricted session variables. See Section 5.1.9.1, “System Variable Privileges”.
-
Command-Line Format --query-alloc-block-size=#System Variable query_alloc_block_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 8192Minimum Value 1024Maximum Value 4294967295Unit bytesBlock Size 1024The allocation size in bytes of memory blocks that are allocated for objects created during statement parsing and execution. If you have problems with memory fragmentation, it might help to increase this parameter.
-
Command-Line Format --query-prealloc-size=#System Variable query_prealloc_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 8192Minimum Value 8192Maximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295Block Size 1024The size in bytes of the persistent buffer used for statement parsing and execution. This buffer is not freed between statements. If you are running complex queries, a larger
query_prealloc_sizevalue might be helpful in improving performance, because it can reduce the need for the server to perform memory allocation during query execution operations. -
System Variable rand_seed1Scope Session Dynamic Yes SET_VARHint AppliesNo Type Integer The
rand_seed1andrand_seed2variables exist as session variables only, and can be set but not read. The variables—but not their values—are shown in the output ofSHOW VARIABLES.The purpose of these variables is to support replication of the
RAND()function. For statements that invokeRAND(), the source passes two values to the replica, where they are used to seed the random number generator. The replica uses these values to set the session variablesrand_seed1andrand_seed2so thatRAND()on the replica generates the same value as on the source. See the description for
rand_seed1.-
Command-Line Format --range-alloc-block-size=#System Variable range_alloc_block_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 4096Minimum Value 4096Maximum Value (64-bit platforms) 18446744073709547520Maximum Value 4294967295Block Size 1024The size in bytes of blocks that are allocated when doing range optimization.
-
Command-Line Format --range-optimizer-max-mem-size=#System Variable range_optimizer_max_mem_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 8388608Minimum Value 0Maximum Value 18446744073709551615The limit on memory consumption for the range optimizer. A value of 0 means “no limit.” If an execution plan considered by the optimizer uses the range access method but the optimizer estimates that the amount of memory needed for this method would exceed the limit, it abandons the plan and considers other plans. For more information, see Limiting Memory Use for Range Optimization.
-
System Variable rbr_exec_modeScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value STRICTValid Values IDEMPOTENTSTRICTFor internal use by mysqlbinlog. This variable switches the server between
IDEMPOTENTmode andSTRICTmode.IDEMPOTENTmode causes suppression of duplicate-key and no-key-found errors inBINLOGstatements generated by mysqlbinlog. This mode is useful when replaying a row-based binary log on a server that causes conflicts with existing data. mysqlbinlog sets this mode when you specify the--idempotentoption by writing the following to the output:SET SESSION RBR_EXEC_MODE=IDEMPOTENT;
As of MySQL 8.0.18, setting the session value of this system variable is no longer a restricted operation.
-
Command-Line Format --read-buffer-size=#System Variable read_buffer_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 131072Minimum Value 8192Maximum Value 2147479552Each thread that does a sequential scan for a
MyISAMtable allocates a buffer of this size (in bytes) for each table it scans. If you do many sequential scans, you might want to increase this value, which defaults to 131072. The value of this variable should be a multiple of 4KB. If it is set to a value that is not a multiple of 4KB, its value is rounded down to the nearest multiple of 4KB.This option is also used in the following context for all storage engines:
For caching the indexes in a temporary file (not a temporary table), when sorting rows for
ORDER BY.For bulk insert into partitions.
For caching results of nested queries.
read_buffer_sizeis also used in one other storage engine-specific way: to determine the memory block size forMEMORYtables.Beginning with MySQL 8.0.22, the value of
select_into_buffer_sizeis used in place of the value ofread_buffer_sizefor the buffer used when executingSELECT INTO DUMPFILEandSELECT INTO OUTFILEstatements.For more information about memory use during different operations, see Section 8.12.3.1, “How MySQL Uses Memory”.
-
Command-Line Format --read-only[={OFF|ON}]System Variable read_onlyScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFIf the
read_onlysystem variable is enabled, the server permits no client updates except from users who have theCONNECTION_ADMINprivilege (or the deprecatedSUPERprivilege). This variable is disabled by default.The server also supports a
super_read_onlysystem variable (disabled by default), which has these effects:If
super_read_onlyis enabled, the server prohibits client updates, even from users who have theCONNECTION_ADMINorSUPERprivilege.Setting
super_read_onlytoONimplicitly forcesread_onlytoON.Setting
read_onlytoOFFimplicitly forcessuper_read_onlytoOFF.
Even with
read_onlyenabled, the server permits these operations:Updates performed by replication threads, if the server is a replica. In replication setups, it can be useful to enable
read_onlyon replica servers to ensure that replicas accept updates only from the replication source server and not from clients.Writes to the system table
mysql.gtid_executed, which stores GTIDs for executed transactions that are not present in the current binary log file.Use of
ANALYZE TABLEorOPTIMIZE TABLEstatements. The purpose of read-only mode is to prevent changes to table structure or contents. Analysis and optimization do not qualify as such changes. This means, for example, that consistency checks on read-only replicas can be performed with mysqlcheck --all-databases --analyze.Operations on
TEMPORARYtables.Inserts into the log tables (
mysql.general_logandmysql.slow_log); see Section 5.4.1, “Selecting General Query Log and Slow Query Log Output Destinations”.Updates to Performance Schema tables, such as
UPDATEorTRUNCATE TABLEoperations.
Changes to
read_onlyon a replication source server are not replicated to replica servers. The value can be set on a replica server independent of the setting on the source.The following conditions apply to attempts to enable
read_only(including implicit attempts resulting from enablingsuper_read_only):The attempt fails and an error occurs if you have any explicit locks (acquired with
LOCK TABLES) or have a pending transaction.The attempt blocks while other clients have any ongoing statement, active
LOCK TABLES WRITE, or ongoing commit, until the locks are released and the statements and transactions end. While the attempt to enableread_onlyis pending, requests by other clients for table locks or to begin transactions also block untilread_onlyhas been set.The attempt blocks if there are active transactions that hold metadata locks, until those transactions end.
read_onlycan be enabled while you hold a global read lock (acquired withFLUSH TABLES WITH READ LOCK) because that does not involve table locks.
-
Command-Line Format --read-rnd-buffer-size=#System Variable read_rnd_buffer_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 262144Minimum Value 1Maximum Value 2147483647This variable is used for reads from
MyISAMtables, and, for any storage engine, for Multi-Range Read optimization.When reading rows from a
MyISAMtable in sorted order following a key-sorting operation, the rows are read through this buffer to avoid disk seeks. See Section 8.2.1.16, “ORDER BY Optimization”. Setting the variable to a large value can improveORDER BYperformance by a lot. However, this is a buffer allocated for each client, so you should not set the global variable to a large value. Instead, change the session variable only from within those clients that need to run large queries.For more information about memory use during different operations, see Section 8.12.3.1, “How MySQL Uses Memory”. For information about Multi-Range Read optimization, see Section 8.2.1.11, “Multi-Range Read Optimization”.
-
Command-Line Format --regexp-stack-limit=#System Variable regexp_stack_limitScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 8000000Minimum Value 0Maximum Value 2147483647The maximum available memory in bytes for the internal stack used for regular expression matching operations performed by
REGEXP_LIKE()and similar functions (see Section 12.8.2, “Regular Expressions”). -
Command-Line Format --regexp-time-limit=#System Variable regexp_time_limitScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 32Minimum Value 0Maximum Value 2147483647The time limit for regular expression matching operations performed by
REGEXP_LIKE()and similar functions (see Section 12.8.2, “Regular Expressions”). This limit is expressed as the maximum permitted number of steps performed by the match engine, and thus affects execution time only indirectly. Typically, it is on the order of milliseconds. -
Introduced 8.0.19 System Variable require_row_formatScope Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFThis variable is for internal server use by replication and mysqlbinlog. It restricts DML events executed in the session to events encoded in row-based binary logging format only, and temporary tables cannot be created. Queries that do not respect the restrictions fail.
Setting the session value of this system variable to
ONrequires no privileges. Setting the session value of this system variable toOFFis a restricted operation, and the session user must have privileges sufficient to set restricted session variables. See Section 5.1.9.1, “System Variable Privileges”. -
Command-Line Format --require-secure-transport[={OFF|ON}]System Variable require_secure_transportScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFWhether client connections to the server are required to use some form of secure transport. When this variable is enabled, the server permits only TCP/IP connections encrypted using TLS/SSL, or connections that use a socket file (on Unix) or shared memory (on Windows). The server rejects nonsecure connection attempts, which fail with an
ER_SECURE_TRANSPORT_REQUIREDerror.This capability supplements per-account SSL requirements, which take precedence. For example, if an account is defined with
REQUIRE SSL, enablingrequire_secure_transportdoes not make it possible to use the account to connect using a Unix socket file.It is possible for a server to have no secure transports available. For example, a server on Windows supports no secure transports if started without specifying any SSL certificate or key files and with the
shared_memorysystem variable disabled. Under these conditions, attempts to enablerequire_secure_transportat startup cause the server to write a message to the error log and exit. Attempts to enable the variable at runtime fail with anER_NO_SECURE_TRANSPORTS_CONFIGUREDerror. -
System Variable resultset_metadataScope Session Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value FULLValid Values FULLNONEFor connections for which metadata transfer is optional, the client sets the
resultset_metadatasystem variable to control whether the server returns result set metadata. Permitted values areFULL(return all metadata; this is the default) andNONE(return no metadata).For connections that are not metadata-optional, setting
resultset_metadatatoNONEproduces an error.For details about managing result set metadata transfer, see C API Optional Result Set Metadata.
secondary_engine_cost_thresholdIntroduced 8.0.16 System Variable secondary_engine_cost_thresholdScope Session Dynamic Yes SET_VARHint AppliesYes Type Numeric Default Value 100000.000000Minimum Value 0Maximum Value DBL_MAX (maximum double value)The optimizer cost threshold for query offload to a secondary engine.
For use with HeatWave. See HeatWave User Guide.
-
Command-Line Format --schema-definition-cache=#System Variable schema_definition_cacheScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 256Minimum Value 256Maximum Value 524288Defines a limit for the number of schema definition objects, both used and unused, that can be kept in the dictionary object cache.
Unused schema definition objects are only kept in the dictionary object cache when the number in use is less than the capacity defined by
schema_definition_cache.A setting of
0means that schema definition objects are only kept in the dictionary object cache while they are in use.For more information, see Section 14.4, “Dictionary Object Cache”.
-
Command-Line Format --secure-file-priv=dir_nameSystem Variable secure_file_privScope Global Dynamic No SET_VARHint AppliesNo Type String Default Value platform specificValid Values empty stringdirnameNULLThis variable is used to limit the effect of data import and export operations, such as those performed by the
LOAD DATAandSELECT ... INTO OUTFILEstatements and theLOAD_FILE()function. These operations are permitted only to users who have theFILEprivilege.secure_file_privmay be set as follows:If empty, the variable has no effect. This is not a secure setting.
If set to the name of a directory, the server limits import and export operations to work only with files in that directory. The directory must exist; the server does not create it.
If set to
NULL, the server disables import and export operations.
The default value is platform specific and depends on the value of the
INSTALL_LAYOUTCMake option, as shown in the following table. To specify the defaultsecure_file_privvalue explicitly if you are building from source, use theINSTALL_SECURE_FILE_PRIVDIRCMake option.INSTALL_LAYOUTValueDefault secure_file_privValueSTANDALONEempty DEB,RPM,SVR4/var/lib/mysql-filesOtherwise mysql-filesunder theCMAKE_INSTALL_PREFIXvalueThe server checks the value of
secure_file_privat startup and writes a warning to the error log if the value is insecure. A non-NULLvalue is considered insecure if it is empty, or the value is the data directory or a subdirectory of it, or a directory that is accessible by all users. Ifsecure_file_privis set to a nonexistent path, the server writes an error message to the error log and exits. -
Command-Line Format --select-into-buffer-size=#Introduced 8.0.22 System Variable select_into_buffer_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 131072Minimum Value 8192Maximum Value 2147479552Unit bytesWhen using
SELECT INTO OUTFILEorSELECT INTO DUMPFILEto dump data into one or more files for backup creation, data migration, or other purposes, writes can often be buffered and then trigger a large burst of write I/O activity to the disk or other storage device and stall other queries that are more sensitive to latency. You can use this variable to control the size of the buffer used to write data to the storage device to determine when buffer synchronization should occur, and thus to prevent write stalls of the kind just described from occurring.select_into_buffer_sizeoverrides any value set forread_buffer_size. (select_into_buffer_sizeandread_buffer_sizehave the same default, maximum, and minimum values.) You can also useselect_into_disk_sync_delayto set a timeout to be observed afterwards, each time synchronization takes place. -
Command-Line Format --select-into-disk-sync={ON|OFF}Introduced 8.0.22 System Variable select_into_disk_syncScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Boolean Default Value OFFValid Values OFFONWhen set on
ON, enables buffer synchronization of writes to an output file by a long-runningSELECT INTO OUTFILEorSELECT INTO DUMPFILEstatement usingselect_into_buffer_size. -
Command-Line Format --select-into-disk-sync-delay=#Introduced 8.0.22 System Variable select_into_disk_sync_delayScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 0Minimum Value 0Maximum Value 31536000Unit millisecondsWhen buffer synchronization of writes to an output file by a long-running
SELECT INTO OUTFILEorSELECT INTO DUMPFILEstatement is enabled byselect_into_disk_sync, this variable sets an optional delay (in milliseconds) following synchronization.0(the default) means no delay. -
Command-Line Format --session-track-gtids=valueSystem Variable session_track_gtidsScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value OFFValid Values OFFOWN_GTIDALL_GTIDSControls whether the server returns GTIDs to the client, enabling the client to use them to track the server state. Depending on the variable value, at the end of executing each transaction, the server’s GTIDs are captured and returned to the client as part of the acknowledgement. The possible values for
session_track_gtidsare as follows:OFF: The server does not return GTIDs to the client. This is the default.OWN_GTID: The server returns the GTIDs for all transactions that were successfully committed by this client in its current session since the last acknowledgement. Typically, this is the single GTID for the last transaction committed, but if a single client request resulted in multiple transactions, the server returns a GTID set containing all the relevant GTIDs.ALL_GTIDS: The server returns the global value of itsgtid_executedsystem variable, which it reads at a point after the transaction is successfully committed. As well as the GTID for the transaction just committed, this GTID set includes all transactions committed on the server by any client, and can include transactions committed after the point when the transaction currently being acknowledged was committed.
session_track_gtidscannot be set within transactional context.For more information about session state tracking, see Section 5.1.18, “Server Tracking of Client Session State Changes”.
-
Command-Line Format --session-track-schema[={OFF|ON}]System Variable session_track_schemaScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value ONControls whether the server tracks when the default schema (database) is set within the current session and notifies the client to make the schema name available.
If the schema name tracker is enabled, name notification occurs each time the default schema is set, even if the new schema name is the same as the old.
For more information about session state tracking, see Section 5.1.18, “Server Tracking of Client Session State Changes”.
-
Command-Line Format --session-track-state-change[={OFF|ON}]System Variable session_track_state_changeScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFControls whether the server tracks changes to the state of the current session and notifies the client when state changes occur. Changes can be reported for these attributes of client session state:
The default schema (database).
Session-specific values for system variables.
User-defined variables.
Temporary tables.
Prepared statements.
If the session state tracker is enabled, notification occurs for each change that involves tracked session attributes, even if the new attribute values are the same as the old. For example, setting a user-defined variable to its current value results in a notification.
The
session_track_state_changevariable controls only notification of when changes occur, not what the changes are. For example, state-change notifications occur when the default schema is set or tracked session system variables are assigned, but the notification does not include the schema name or variable values. To receive notification of the schema name or session system variable values, use thesession_track_schemaorsession_track_system_variablessystem variable, respectively.NoteAssigning a value to
session_track_state_changeitself is not considered a state change and is not reported as such. However, if its name listed in the value ofsession_track_system_variables, any assignments to it do result in notification of the new value.For more information about session state tracking, see Section 5.1.18, “Server Tracking of Client Session State Changes”.
session_track_system_variablesCommand-Line Format --session-track-system-variables=#System Variable session_track_system_variablesScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String Default Value time_zone, autocommit, character_set_client, character_set_results, character_set_connectionControls whether the server tracks assignments to session system variables and notifies the client of the name and value of each assigned variable. The variable value is a comma-separated list of variables for which to track assignments. By default, notification is enabled for
time_zone,autocommit,character_set_client,character_set_results, andcharacter_set_connection. (The latter three variables are those affected bySET NAMES.)The special value
*causes the server to track assignments to all session variables. If given, this value must be specified by itself without specific system variable names.To disable notification of session variable assignments, set
session_track_system_variablesto the empty string.If session system variable tracking is enabled, notification occurs for all assignments to tracked session variables, even if the new values are the same as the old.
For more information about session state tracking, see Section 5.1.18, “Server Tracking of Client Session State Changes”.
session_track_transaction_infoCommand-Line Format --session-track-transaction-info=valueSystem Variable session_track_transaction_infoScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value OFFValid Values OFFSTATECHARACTERISTICSControls whether the server tracks the state and characteristics of transactions within the current session and notifies the client to make this information available. These
session_track_transaction_infovalues are permitted:OFF: Disable transaction state tracking. This is the default.STATE: Enable transaction state tracking without characteristics tracking. State tracking enables the client to determine whether a transaction is in progress and whether it could be moved to a different session without being rolled back.CHARACTERISTICS: Enable transaction state tracking, including characteristics tracking. Characteristics tracking enables the client to determine how to restart a transaction in another session so that it has the same characteristics as in the original session. The following characteristics are relevant for this purpose:ISOLATION LEVEL READ ONLY READ WRITE WITH CONSISTENT SNAPSHOT
For a client to safely relocate a transaction to another session, it must track not only transaction state but also transaction characteristics. In addition, the client must track the
transaction_isolationandtransaction_read_onlysystem variables to correctly determine the session defaults. (To track these variables, list them in the value of thesession_track_system_variablessystem variable.)For more information about session state tracking, see Section 5.1.18, “Server Tracking of Client Session State Changes”.
sha256_password_auto_generate_rsa_keysCommand-Line Format --sha256-password-auto-generate-rsa-keys[={OFF|ON}]System Variable sha256_password_auto_generate_rsa_keysScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value ONThe server uses this variable to determine whether to autogenerate RSA private/public key-pair files in the data directory if they do not already exist.
At startup, the server automatically generates RSA private/public key-pair files in the data directory if all of these conditions are true: The
sha256_password_auto_generate_rsa_keysorcaching_sha2_password_auto_generate_rsa_keyssystem variable is enabled; no RSA options are specified; the RSA files are missing from the data directory. These key-pair files enable secure password exchange using RSA over unencrypted connections for accounts authenticated by thesha256_passwordorcaching_sha2_passwordplugin; see Section 6.4.1.3, “SHA-256 Pluggable Authentication”, and Section 6.4.1.2, “Caching SHA-2 Pluggable Authentication”.For more information about RSA file autogeneration, including file names and characteristics, see Section 6.3.3.1, “Creating SSL and RSA Certificates and Keys using MySQL”
The
auto_generate_certssystem variable is related but controls autogeneration of SSL certificate and key files needed for secure connections using SSL.sha256_password_private_key_pathCommand-Line Format --sha256-password-private-key-path=file_nameSystem Variable sha256_password_private_key_pathScope Global Dynamic No SET_VARHint AppliesNo Type File name Default Value private_key.pemThe value of this variable is the path name of the RSA private key file for the
sha256_passwordauthentication plugin. If the file is named as a relative path, it is interpreted relative to the server data directory. The file must be in PEM format.ImportantBecause this file stores a private key, its access mode should be restricted so that only the MySQL server can read it.
For information about
sha256_password, see Section 6.4.1.3, “SHA-256 Pluggable Authentication”.-
Command-Line Format --sha256-password-proxy-users[={OFF|ON}]System Variable sha256_password_proxy_usersScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFThis variable controls whether the
sha256_passwordbuilt-in authentication plugin supports proxy users. It has no effect unless thecheck_proxy_userssystem variable is enabled. For information about user proxying, see Section 6.2.18, “Proxy Users”. sha256_password_public_key_pathCommand-Line Format --sha256-password-public-key-path=file_nameSystem Variable sha256_password_public_key_pathScope Global Dynamic No SET_VARHint AppliesNo Type File name Default Value public_key.pemThe value of this variable is the path name of the RSA public key file for the
sha256_passwordauthentication plugin. If the file is named as a relative path, it is interpreted relative to the server data directory. The file must be in PEM format. Because this file stores a public key, copies can be freely distributed to client users. (Clients that explicitly specify a public key when connecting to the server using RSA password encryption must use the same public key as that used by the server.)For information about
sha256_password, including information about how clients specify the RSA public key, see Section 6.4.1.3, “SHA-256 Pluggable Authentication”.-
Command-Line Format --shared-memory[={OFF|ON}]System Variable shared_memoryScope Global Dynamic No SET_VARHint AppliesNo Platform Specific Windows Type Boolean Default Value OFF(Windows only.) Whether the server permits shared-memory connections.
-
Command-Line Format --shared-memory-base-name=nameSystem Variable shared_memory_base_nameScope Global Dynamic No SET_VARHint AppliesNo Platform Specific Windows Type String Default Value MYSQL(Windows only.) The name of shared memory to use for shared-memory connections. This is useful when running multiple MySQL instances on a single physical machine. The default name is
MYSQL. The name is case-sensitive.This variable applies only if the server is started with the
shared_memorysystem variable enabled to support shared-memory connections. show_create_table_skip_secondary_engineCommand-Line Format --show-create-table-skip-secondary-engine[={OFF|ON}]Introduced 8.0.18 System Variable show_create_table_skip_secondary_engineScope Session Dynamic Yes SET_VARHint AppliesYes Type Boolean Default Value OFFEnabling
show_create_table_skip_secondary_enginecauses theSECONDARY ENGINEclause to be excluded fromSHOW CREATE TABLEoutput, and fromCREATE TABLEstatements dumped by the mysqldump utility.mysqldump provides the
--show-create-skip-secondary-engineoption. When specified, it enables theshow_create_table_skip_secondary_enginesystem variable for the duration of the dump operation.Attempting a mysqldump operation with the
--show-create-skip-secondary-engineoption on a release prior to MySQL 8.0.18 that does not support theshow_create_table_skip_secondary_enginevariable causes an error.For use with HeatWave. See HeatWave User Guide.
-
Command-Line Format --show-create-table-verbosity[={OFF|ON}]System Variable show_create_table_verbosityScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFSHOW CREATE TABLEnormally does not show theROW_FORMATtable option if the row format is the default format. Enabling this variable causesSHOW CREATE TABLEto displayROW_FORMATregardless of whether it is the default format. -
Command-Line Format --show-old-temporals[={OFF|ON}]Deprecated Yes System Variable show_old_temporalsScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFWhether
SHOW CREATE TABLEoutput includes comments to flag temporal columns found to be in pre-5.6.4 format (TIME,DATETIME, andTIMESTAMPcolumns without support for fractional seconds precision). This variable is disabled by default. If enabled,SHOW CREATE TABLEoutput looks like this:CREATE TABLE `mytbl` ( `ts` timestamp /* 5.5 binary format */ NOT NULL DEFAULT CURRENT_TIMESTAMP, `dt` datetime /* 5.5 binary format */ DEFAULT NULL, `t` time /* 5.5 binary format */ DEFAULT NULL ) DEFAULT CHARSET=utf8mb4
Output for the
COLUMN_TYPEcolumn of theINFORMATION_SCHEMA.COLUMNStable is affected similarly.This variable is deprecated; expect it to be removed in a future MySQL release.
-
Command-Line Format --skip-external-locking[={OFF|ON}]System Variable skip_external_lockingScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value ONThis is
OFFif mysqld uses external locking (system locking),ONif external locking is disabled. This affects onlyMyISAMtable access.This variable is set by the
--external-lockingor--skip-external-lockingoption. External locking is disabled by default.External locking affects only
MyISAMtable access. For more information, including conditions under which it can and cannot be used, see Section 8.11.5, “External Locking”. -
Command-Line Format --skip-name-resolve[={OFF|ON}]System Variable skip_name_resolveScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value OFFWhether to resolve host names when checking client connections. If this variable is
OFF, mysqld resolves host names when checking client connections. If it isON, mysqld uses only IP numbers; in this case, allHostcolumn values in the grant tables must be IP addresses. See Section 5.1.12.3, “DNS Lookups and the Host Cache”.Depending on the network configuration of your system and the
Hostvalues for your accounts, clients may need to connect using an explicit--hostoption, such as--host=127.0.0.1or--host=::1.An attempt to connect to the host
127.0.0.1normally resolves to thelocalhostaccount. However, this fails if the server is run withskip_name_resolveenabled. If you plan to do that, make sure an account exists that can accept a connection. For example, to be able to connect asrootusing--host=127.0.0.1or--host=::1, create these accounts:CREATE USER 'root'@'127.0.0.1' IDENTIFIED BY '
root-password'; CREATE USER 'root'@'::1' IDENTIFIED BY 'root-password'; -
Command-Line Format --skip-networking[={OFF|ON}]System Variable skip_networkingScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value OFFThis variable controls whether the server permits TCP/IP connections. By default, it is disabled (permit TCP connections). If enabled, the server permits only local (non-TCP/IP) connections and all interaction with mysqld must be made using named pipes or shared memory (on Windows) or Unix socket files (on Unix). This option is highly recommended for systems where only local clients are permitted. See Section 5.1.12.3, “DNS Lookups and the Host Cache”.
Because starting the server with
--skip-grant-tablesdisables authentication checks, the server also disables remote connections in that case by enablingskip_networking. -
Command-Line Format --skip-show-databaseSystem Variable skip_show_databaseScope Global Dynamic No SET_VARHint AppliesNo This prevents people from using the
SHOW DATABASESstatement if they do not have theSHOW DATABASESprivilege. This can improve security if you have concerns about users being able to see databases belonging to other users. Its effect depends on theSHOW DATABASESprivilege: If the variable value isON, theSHOW DATABASESstatement is permitted only to users who have theSHOW DATABASESprivilege, and the statement displays all database names. If the value isOFF,SHOW DATABASESis permitted to all users, but displays the names of only those databases for which the user has theSHOW DATABASESor other privilege.CautionBecause any static global privilege is considered a privilege for all databases, any static global privilege enables a user to see all database names with
SHOW DATABASESor by examining theSCHEMATAtable ofINFORMATION_SCHEMA, except databases that have been restricted at the database level by partial revokes. -
Command-Line Format --slow-launch-time=#System Variable slow_launch_timeScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 2If creating a thread takes longer than this many seconds, the server increments the
Slow_launch_threadsstatus variable. -
Command-Line Format --slow-query-log[={OFF|ON}]System Variable slow_query_logScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFWhether the slow query log is enabled. The value can be 0 (or
OFF) to disable the log or 1 (orON) to enable the log. The destination for log output is controlled by thelog_outputsystem variable; if that value isNONE, no log entries are written even if the log is enabled.“Slow” is determined by the value of the
long_query_timevariable. See Section 5.4.5, “The Slow Query Log”. -
Command-Line Format --slow-query-log-file=file_nameSystem Variable slow_query_log_fileScope Global Dynamic Yes SET_VARHint AppliesNo Type File name Default Value host_name-slow.logThe name of the slow query log file. The default value is
host_name-slow.log--slow_query_log_fileoption. -
Command-Line Format --socket={file_name|pipe_name}System Variable socketScope Global Dynamic No SET_VARHint AppliesNo Type String Default Value (Other) /tmp/mysql.sockDefault Value (Windows) MySQLOn Unix platforms, this variable is the name of the socket file that is used for local client connections. The default is
/tmp/mysql.sock. (For some distribution formats, the directory might be different, such as/var/lib/mysqlfor RPMs.)On Windows, this variable is the name of the named pipe that is used for local client connections. The default value is
MySQL(not case-sensitive). -
Command-Line Format --sort-buffer-size=#System Variable sort_buffer_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 262144Minimum Value 32768Maximum Value (Other, 64-bit platforms) 18446744073709551615Maximum Value (Other, 32-bit platforms) 4294967295Maximum Value (Windows) 4294967295Each session that must perform a sort allocates a buffer of this size.
sort_buffer_sizeis not specific to any storage engine and applies in a general manner for optimization. At minimum thesort_buffer_sizevalue must be large enough to accommodate fifteen tuples in the sort buffer. Also, increasing the value ofmax_sort_lengthmay require increasing the value ofsort_buffer_size. For more information, see Section 8.2.1.16, “ORDER BY Optimization”If you see many
Sort_merge_passesper second inSHOW GLOBAL STATUSoutput, you can consider increasing thesort_buffer_sizevalue to speed upORDER BYorGROUP BYoperations that cannot be improved with query optimization or improved indexing.The optimizer tries to work out how much space is needed but can allocate more, up to the limit. Setting it larger than required globally slows down most queries that perform sorts. It is best to increase it as a session setting, and only for the sessions that need a larger size. On Linux, there are thresholds of 256KB and 2MB where larger values may significantly slow down memory allocation, so you should consider staying below one of those values. Experiment to find the best value for your workload. See Section B.3.3.5, “Where MySQL Stores Temporary Files”.
The maximum permissible setting for
sort_buffer_sizeis 4GB−1. Larger values are permitted for 64-bit platforms (except 64-bit Windows, for which large values are truncated to 4GB−1 with a warning). -
System Variable sql_auto_is_nullScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Boolean Default Value OFFIf this variable is enabled, then after a statement that successfully inserts an automatically generated
AUTO_INCREMENTvalue, you can find that value by issuing a statement of the following form:SELECT * FROM
tbl_nameWHEREauto_colIS NULLIf the statement returns a row, the value returned is the same as if you invoked the
LAST_INSERT_ID()function. For details, including the return value after a multiple-row insert, see Section 12.16, “Information Functions”. If noAUTO_INCREMENTvalue was successfully inserted, theSELECTstatement returns no row.The behavior of retrieving an
AUTO_INCREMENTvalue by using anIS NULLcomparison is used by some ODBC programs, such as Access. See Obtaining Auto-Increment Values. This behavior can be disabled by settingsql_auto_is_nulltoOFF.Prior to MySQL 8.0.16, the transformation of
WHEREtoauto_colIS NULLWHEREwas performed only when the statement was executed, so that the value ofauto_col= LAST_INSERT_ID()sql_auto_is_nullduring execution determined whether the query was transformed. In MySQL 8.0.16 and later, the transformation is performed during statement preparation.The default value of
sql_auto_is_nullisOFF. -
System Variable sql_big_selectsScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Boolean Default Value ONIf set to
OFF, MySQL abortsSELECTstatements that are likely to take a very long time to execute (that is, statements for which the optimizer estimates that the number of examined rows exceeds the value ofmax_join_size). This is useful when an inadvisableWHEREstatement has been issued. The default value for a new connection isON, which permits allSELECTstatements.If you set the
max_join_sizesystem variable to a value other thanDEFAULT,sql_big_selectsis set toOFF. -
System Variable sql_buffer_resultScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Boolean Default Value OFFIf enabled,
sql_buffer_resultforces results fromSELECTstatements to be put into temporary tables. This helps MySQL free the table locks early and can be beneficial in cases where it takes a long time to send results to the client. The default value isOFF. -
System Variable sql_log_offScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFValid Values OFF(enable logging)ON(disable logging)This variable controls whether logging to the general query log is disabled for the current session (assuming that the general query log itself is enabled). The default value is
OFF(that is, enable logging). To disable or enable general query logging for the current session, set the sessionsql_log_offvariable toONorOFF.Setting the session value of this system variable is a restricted operation. The session user must have privileges sufficient to set restricted session variables. See Section 5.1.9.1, “System Variable Privileges”.
-
Command-Line Format --sql-mode=nameSystem Variable sql_modeScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Set Default Value ONLY_FULL_GROUP_BY STRICT_TRANS_TABLES NO_ZERO_IN_DATE NO_ZERO_DATE ERROR_FOR_DIVISION_BY_ZERO NO_ENGINE_SUBSTITUTIONValid Values ALLOW_INVALID_DATESANSI_QUOTESERROR_FOR_DIVISION_BY_ZEROHIGH_NOT_PRECEDENCEIGNORE_SPACENO_AUTO_VALUE_ON_ZERONO_BACKSLASH_ESCAPESNO_DIR_IN_CREATENO_ENGINE_SUBSTITUTIONNO_UNSIGNED_SUBTRACTIONNO_ZERO_DATENO_ZERO_IN_DATEONLY_FULL_GROUP_BYPAD_CHAR_TO_FULL_LENGTHPIPES_AS_CONCATREAL_AS_FLOATSTRICT_ALL_TABLESSTRICT_TRANS_TABLESTIME_TRUNCATE_FRACTIONALThe current server SQL mode, which can be set dynamically. For details, see Section 5.1.11, “Server SQL Modes”.
NoteMySQL installation programs may configure the SQL mode during the installation process.
If the SQL mode differs from the default or from what you expect, check for a setting in an option file that the server reads at startup.
-
System Variable sql_notesScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value ONIf enabled (the default), diagnostics of
Notelevel incrementwarning_countand the server records them. If disabled,Notediagnostics do not incrementwarning_countand the server does not record them. mysqldump includes output to disable this variable so that reloading the dump file does not produce warnings for events that do not affect the integrity of the reload operation. -
System Variable sql_quote_show_createScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value ONIf enabled (the default), the server quotes identifiers for
SHOW CREATE TABLEandSHOW CREATE DATABASEstatements. If disabled, quoting is disabled. This option is enabled by default so that replication works for identifiers that require quoting. See Section 13.7.7.10, “SHOW CREATE TABLE Statement”, and Section 13.7.7.6, “SHOW CREATE DATABASE Statement”. -
Command-Line Format --sql-require-primary-key[={OFF|ON}]Introduced 8.0.13 System Variable sql_require_primary_keyScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Boolean Default Value OFFWhether statements that create new tables or alter the structure of existing tables enforce the requirement that tables have a primary key.
Setting the session value of this system variable is a restricted operation. The session user must have privileges sufficient to set restricted session variables. See Section 5.1.9.1, “System Variable Privileges”.
Enabling this variable helps avoid performance problems in row-based replication that can occur when tables have no primary key. Suppose that a table has no primary key and an update or delete modifies multiple rows. On the replication source server, this operation can be performed using a single table scan but, when replicated using row-based replication, results in a table scan for each row to be modified on the replica. With a primary key, these table scans do not occur.
sql_require_primary_keyapplies to both base tables andTEMPORARYtables, and changes to its value are replicated to replica servers. As of MySQL 8.0.18, it applies only to storage engines that can participate in replication.When enabled,
sql_require_primary_keyhas these effects:Attempts to create a new table with no primary key fail with an error. This includes
CREATE TABLE ... LIKE. It also includesCREATE TABLE ... SELECT, unless theCREATE TABLEpart includes a primary key definition.Attempts to drop the primary key from an existing table fail with an error, with the exception that dropping the primary key and adding a primary key in the same
ALTER TABLEstatement is permitted.Dropping the primary key fails even if the table also contains a
UNIQUE NOT NULLindex.Attempts to import a table with no primary key fail with an error.
The
REQUIRE_TABLE_PRIMARY_KEY_CHECKoption of theCHANGE MASTER TOstatement enables a replica to select its own policy for primary key checks. When the option is set toONfor a replication channel, the replica always uses the valueONfor thesql_require_primary_keysystem variable in replication operations, requiring a primary key. When the option is set toOFF, the replica always uses the valueOFFfor thesql_require_primary_keysystem variable in replication operations, so that a primary key is never required, even if the source required one. When theREQUIRE_TABLE_PRIMARY_KEY_CHECKoption is set toSTREAM, which is the default, the replica uses whatever value is replicated from the source for each transaction. With theSTREAMsetting for theREQUIRE_TABLE_PRIMARY_KEY_CHECKoption, if privilege checks are in use for the replication channel, thePRIVILEGE_CHECKS_USERaccount needs privileges sufficient to set restricted session variables, so that it can set the session value for thesql_require_primary_keysystem variable. With theONorOFFsettings, the account does not need these privileges. For more information, see Section 17.3.3, “Replication Privilege Checks”. -
System Variable sql_safe_updatesScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Boolean Default Value OFFIf this variable is enabled,
UPDATEandDELETEstatements that do not use a key in theWHEREclause or aLIMITclause produce an error. This makes it possible to catchUPDATEandDELETEstatements where keys are not used properly and that would probably change or delete a large number of rows. The default value isOFF.For the mysql client,
sql_safe_updatescan be enabled by using the--safe-updatesoption. For more information, see Using Safe-Updates Mode (--safe-updates). -
System Variable sql_select_limitScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer The maximum number of rows to return from
SELECTstatements. For more information, see Using Safe-Updates Mode (--safe-updates).The default value for a new connection is the maximum number of rows that the server permits per table. Typical default values are (232)−1 or (264)−1. If you have changed the limit, the default value can be restored by assigning a value of
DEFAULT.If a
SELECThas aLIMITclause, theLIMITtakes precedence over the value ofsql_select_limit. -
System Variable sql_warningsScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFThis variable controls whether single-row
INSERTstatements produce an information string if warnings occur. The default isOFF. Set the value toONto produce an information string. -
Command-Line Format --ssl-ca=file_nameSystem Variable ssl_caScope Global Dynamic (≥ 8.0.16) Yes Dynamic (≤ 8.0.15) No SET_VARHint AppliesNo Type File name Default Value NULLThe path name of the Certificate Authority (CA) certificate file in PEM format. The file contains a list of trusted SSL Certificate Authorities.
As of MySQL 8.0.16, this variable is dynamic and can be modified at runtime to affect the TSL context the server uses for new connections. See Server-Side Runtime Configuration and Monitoring for Encrypted Connections. Prior to MySQL 8.0.16, this variable can be set only at server startup.
-
Command-Line Format --ssl-capath=dir_nameSystem Variable ssl_capathScope Global Dynamic (≥ 8.0.16) Yes Dynamic (≤ 8.0.15) No SET_VARHint AppliesNo Type Directory name Default Value NULLThe path name of the directory that contains trusted SSL Certificate Authority (CA) certificate files in PEM format.
As of MySQL 8.0.16, this variable is dynamic and can be modified at runtime to affect the TSL context the server uses for new connections. See Server-Side Runtime Configuration and Monitoring for Encrypted Connections. Prior to MySQL 8.0.16, this variable can be set only at server startup.
-
Command-Line Format --ssl-cert=file_nameSystem Variable ssl_certScope Global Dynamic (≥ 8.0.16) Yes Dynamic (≤ 8.0.15) No SET_VARHint AppliesNo Type File name Default Value NULLThe path name of the server SSL public key certificate file in PEM format.
If the server is started with
ssl_certset to a certificate that uses any restricted cipher or cipher category, the server starts with support for encrypted connections disabled. For information about cipher restrictions, see Connection Cipher Configuration.As of MySQL 8.0.16, this variable is dynamic and can be modified at runtime to affect the TSL context the server uses for new connections. See Server-Side Runtime Configuration and Monitoring for Encrypted Connections. Prior to MySQL 8.0.16, this variable can be set only at server startup.
-
Command-Line Format --ssl-cipher=nameSystem Variable ssl_cipherScope Global Dynamic (≥ 8.0.16) Yes Dynamic (≤ 8.0.15) No SET_VARHint AppliesNo Type String Default Value NULLThe list of permissible encryption ciphers for connections that use TLS protocols up through TLSv1.2. If no cipher in the list is supported, encrypted connections that use these TLS protocols do not work.
For greatest portability, the cipher list should be a list of one or more cipher names, separated by colons. Examples:
[mysqld] ssl_cipher="AES128-SHA" ssl_cipher="DHE-RSA-AES128-GCM-SHA256:AES128-SHA"
OpenSSL supports the syntax for specifying ciphers described in the OpenSSL documentation at https://www.openssl.org/docs/manmaster/man1/ciphers.html.
For information about which encryption ciphers MySQL supports, see Section 6.3.2, “Encrypted Connection TLS Protocols and Ciphers”.
As of MySQL 8.0.16, this variable is dynamic and can be modified at runtime to affect the TSL context the server uses for new connections. See Server-Side Runtime Configuration and Monitoring for Encrypted Connections. Prior to MySQL 8.0.16, this variable can be set only at server startup.
-
Command-Line Format --ssl-crl=file_nameSystem Variable ssl_crlScope Global Dynamic (≥ 8.0.16) Yes Dynamic (≤ 8.0.15) No SET_VARHint AppliesNo Type File name Default Value NULLThe path name of the file containing certificate revocation lists in PEM format.
As of MySQL 8.0.16, this variable is dynamic and can be modified at runtime to affect the TSL context the server uses for new connections. See Server-Side Runtime Configuration and Monitoring for Encrypted Connections. Prior to MySQL 8.0.16, this variable can be set only at server startup.
-
Command-Line Format --ssl-crlpath=dir_nameSystem Variable ssl_crlpathScope Global Dynamic (≥ 8.0.16) Yes Dynamic (≤ 8.0.15) No SET_VARHint AppliesNo Type Directory name Default Value NULLThe path of the directory that contains certificate revocation-list files in PEM format.
As of MySQL 8.0.16, this variable is dynamic and can be modified at runtime to affect the TSL context the server uses for new connections. See Server-Side Runtime Configuration and Monitoring for Encrypted Connections. Prior to MySQL 8.0.16, this variable can be set only at server startup.
-
Command-Line Format --ssl-fips-mode={OFF|ON|STRICT}System Variable ssl_fips_modeScope Global Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value OFFValid Values OFF(or 0)ON(or 1)STRICT(or 2)Controls whether to enable FIPS mode on the server side. The
ssl_fips_modesystem variable differs from otherssl_system variables in that it is not used to control whether the server permits encrypted connections, but rather to affect which cryptographic operations are permitted. See Section 6.8, “FIPS Support”.xxxThese
ssl_fips_modevalues are permitted:OFF(or 0): Disable FIPS mode.ON(or 1): Enable FIPS mode.STRICT(or 2): Enable “strict” FIPS mode.
NoteIf the OpenSSL FIPS Object Module is not available, the only permitted value for
ssl_fips_modeisOFF. In this case, settingssl_fips_modetoONorSTRICTat startup causes the server to produce an error message and exit. -
Command-Line Format --ssl-key=file_nameSystem Variable ssl_keyScope Global Dynamic (≥ 8.0.16) Yes Dynamic (≤ 8.0.15) No SET_VARHint AppliesNo Type File name Default Value NULLThe path name of the server SSL private key file in PEM format. For better security, use a certificate with an RSA key size of at least 2048 bits.
If the key file is protected by a passphrase, the server prompts the user for the passphrase. The password must be given interactively; it cannot be stored in a file. If the passphrase is incorrect, the program continues as if it could not read the key.
As of MySQL 8.0.16, this variable is dynamic and can be modified at runtime to affect the TSL context the server uses for new connections. See Server-Side Runtime Configuration and Monitoring for Encrypted Connections. Prior to MySQL 8.0.16, this variable can be set only at server startup.
-
Command-Line Format --stored-program-cache=#System Variable stored_program_cacheScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 256Minimum Value 16Maximum Value 524288Sets a soft upper limit for the number of cached stored routines per connection. The value of this variable is specified in terms of the number of stored routines held in each of the two caches maintained by the MySQL Server for, respectively, stored procedures and stored functions.
Whenever a stored routine is executed this cache size is checked before the first or top-level statement in the routine is parsed; if the number of routines of the same type (stored procedures or stored functions according to which is being executed) exceeds the limit specified by this variable, the corresponding cache is flushed and memory previously allocated for cached objects is freed. This allows the cache to be flushed safely, even when there are dependencies between stored routines.
The stored procedure and stored function caches exists in parallel with the stored program definition cache partition of the dictionary object cache. The stored procedure and stored function caches are per connection, while the stored program definition cache is shared. The existence of objects in the stored procedure and stored function caches have no dependence on the existence of objects in the stored program definition cache, and vice versa. For more information, see Section 14.4, “Dictionary Object Cache”.
stored_program_definition_cacheCommand-Line Format --stored-program-definition-cache=#System Variable stored_program_definition_cacheScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 256Minimum Value 256Maximum Value 524288Defines a limit for the number of stored program definition objects, both used and unused, that can be kept in the dictionary object cache.
Unused stored program definition objects are only kept in the dictionary object cache when the number in use is less than the capacity defined by
stored_program_definition_cache.A setting of 0 means that stored program definition objects are only kept in the dictionary object cache while they are in use.
The stored program definition cache partition exists in parallel with the stored procedure and stored function caches that are configured using the
stored_program_cacheoption.The
stored_program_cacheoption sets a soft upper limit for the number of cached stored procedures or functions per connection, and the limit is checked each time a connection executes a stored procedure or function. The stored program definition cache partition, on the other hand, is a shared cache that stores stored program definition objects for other purposes. The existence of objects in the stored program definition cache partition has no dependence on the existence of objects in the stored procedure cache or stored function cache, and vice versa.For related information, see Section 14.4, “Dictionary Object Cache”.
-
Command-Line Format --super-read-only[={OFF|ON}]System Variable super_read_onlyScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFIf the
read_onlysystem variable is enabled, the server permits no client updates except from users who have theCONNECTION_ADMINprivilege (or the deprecatedSUPERprivilege). If thesuper_read_onlysystem variable is also enabled, the server prohibits client updates even from users who haveCONNECTION_ADMINorSUPER. See the description of theread_onlysystem variable for a description of read-only mode and information about howread_onlyandsuper_read_onlyinteract.Client updates prevented when
super_read_onlyis enabled include operations that do not necessarily appear to be updates, such asCREATE FUNCTION(to install a UDF),INSTALL PLUGIN, andINSTALL COMPONENT. These operations are prohibited because they involve changes to tables in themysqlsystem schema.Changes to
super_read_onlyon a replication source server are not replicated to replica servers. The value can be set on a replica independent of the setting on the source. -
Command-Line Format --syseventlog.facility=valueIntroduced 8.0.13 System Variable syseventlog.facilityScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value daemonThe facility for error log output written to
syslog(what type of program is sending the message). This variable is unavailable unless thelog_sink_syseventlogerror log component is installed. See Section 5.4.2.8, “Error Logging to the System Log”.The permitted values can vary per operating system; consult your system
syslogdocumentation.This variable does not exist on Windows.
-
Command-Line Format --syseventlog.include-pid[={OFF|ON}]Introduced 8.0.13 System Variable syseventlog.include_pidScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value ONWhether to include the server process ID in each line of error log output written to
syslog. This variable is unavailable unless thelog_sink_syseventlogerror log component is installed. See Section 5.4.2.8, “Error Logging to the System Log”.This variable does not exist on Windows.
-
Command-Line Format --syseventlog.tag=tagIntroduced 8.0.13 System Variable syseventlog.tagScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value empty stringThe tag to be added to the server identifier in error log output written to
syslogor the Windows Event Log. This variable is unavailable unless thelog_sink_syseventlogerror log component is installed. See Section 5.4.2.8, “Error Logging to the System Log”.By default, no tag is set, so the server identifier is simply
MySQLon Windows, andmysqldon other platforms. If a tag value oftagis specified, it is appended to the server identifier with a leading hyphen, resulting in asyslogidentifier ofmysqld-(ortagMySQL-on Windows).tagOn Windows, to use a tag that does not already exist, the server must be run from an account with Administrator privileges, to permit creation of a registry entry for the tag. Elevated privileges are not required if the tag already exists.
-
System Variable system_time_zoneScope Global Dynamic No SET_VARHint AppliesNo Type String The server system time zone. When the server begins executing, it inherits a time zone setting from the machine defaults, possibly modified by the environment of the account used for running the server or the startup script. The value is used to set
system_time_zone. Typically the time zone is specified by theTZenvironment variable. It also can be specified using the--timezoneoption of the mysqld_safe script.The
system_time_zonevariable differs fromtime_zone. Although they might have the same value, the latter variable is used to initialize the time zone for each client that connects. See Section 5.1.15, “MySQL Server Time Zone Support”. -
Command-Line Format --table-definition-cache=#System Variable table_definition_cacheScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value -1(signifies autosizing; do not assign this literal value)Minimum Value 400Maximum Value 524288The number of table definitions that can be stored in the definition cache. If you use a large number of tables, you can create a large table definition cache to speed up opening of tables. The table definition cache takes less space and does not use file descriptors, unlike the normal table cache. The minimum value is 400. The default value is based on the following formula, capped to a limit of 2000:
MIN(400 + table_open_cache / 2, 2000)
For
InnoDB,table_definition_cacheacts as a soft limit for the number of open table instances in theInnoDBdata dictionary cache. If the number of open table instances exceeds thetable_definition_cachesetting, the LRU mechanism begins to mark table instances for eviction and eventually removes them from the data dictionary cache. The limit helps address situations in which significant amounts of memory would be used to cache rarely used table instances until the next server restart. The number of table instances with cached metadata could be higher than the limit defined bytable_definition_cache, because parent and child table instances with foreign key relationships are not placed on the LRU list and are not subject to eviction from memory.Additionally,
table_definition_cachedefines a soft limit for the number ofInnoDBfile-per-table tablespaces that can be open at one time, which is also controlled byinnodb_open_files. If bothtable_definition_cacheandinnodb_open_filesare set, the highest setting is used. If neither variable is set,table_definition_cache, which has a higher default value, is used. If the number of open tablespace file handles exceeds the limit defined bytable_definition_cacheorinnodb_open_files, the LRU mechanism searches the tablespace file LRU list for files that are fully flushed and are not currently being extended. This process is performed each time a new tablespace is opened. If there are no “inactive” tablespaces, no tablespace files are closed.The table definition cache exists in parallel with the table definition cache partition of the dictionary object cache. Both caches store table definitions but serve different parts of the MySQL server. Objects in one cache have no dependence on the existence objects in the other. For more information, see Section 14.4, “Dictionary Object Cache”.
table_encryption_privilege_checkCommand-Line Format --table-encryption-privilege-check[={OFF|ON}]Introduced 8.0.16 System Variable table_encryption_privilege_checkScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFControls the
TABLE_ENCRYPTION_ADMINprivilege check that occurs when creating or altering a schema or general tablespace with encryption that differs from thedefault_table_encryptionsetting, or when creating or altering a table with an encryption setting that differs from the default schema encryption. The check is disabled by default.Setting
table_encryption_privilege_checkat runtime requires theSUPERprivilege.table_encryption_privilege_checksupportsSET PERSISTandSET PERSIST_ONLYsyntax. See Section 5.1.9.3, “Persisted System Variables”.For more information, see Defining an Encryption Default for Schemas and General Tablespaces.
-
Command-Line Format --table-open-cache=#System Variable table_open_cacheScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 4000Minimum Value 1Maximum Value 524288The number of open tables for all threads. Increasing this value increases the number of file descriptors that mysqld requires. You can check whether you need to increase the table cache by checking the
Opened_tablesstatus variable. See Section 5.1.10, “Server Status Variables”. If the value ofOpened_tablesis large and you do not useFLUSH TABLESoften (which just forces all tables to be closed and reopened), then you should increase the value of thetable_open_cachevariable. For more information about the table cache, see Section 8.4.3.1, “How MySQL Opens and Closes Tables”. -
Command-Line Format --table-open-cache-instances=#System Variable table_open_cache_instancesScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 16Minimum Value 1Maximum Value 64The number of open tables cache instances. To improve scalability by reducing contention among sessions, the open tables cache can be partitioned into several smaller cache instances of size
table_open_cache/table_open_cache_instances. A session needs to lock only one instance to access it for DML statements. This segments cache access among instances, permitting higher performance for operations that use the cache when there are many sessions accessing tables. (DDL statements still require a lock on the entire cache, but such statements are much less frequent than DML statements.)A value of 8 or 16 is recommended on systems that routinely use 16 or more cores.
-
Command-Line Format --tablespace-definition-cache=#System Variable tablespace_definition_cacheScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 256Minimum Value 256Maximum Value 524288Defines a limit for the number of tablespace definition objects, both used and unused, that can be kept in the dictionary object cache.
Unused tablespace definition objects are only kept in the dictionary object cache when the number in use is less than the capacity defined by
tablespace_definition_cache.A setting of
0means that tablespace definition objects are only kept in the dictionary object cache while they are in use.For more information, see Section 14.4, “Dictionary Object Cache”.
-
Command-Line Format --temptable-max-mmap=#Introduced 8.0.23 System Variable temptable_max_mmapScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 1073741824Minimum Value 0Maximum Value 2^64-1Defines the maximum amount of memory (in bytes) the TempTable storage engine is permitted to allocate from memory-mapped temporary files before it starts storing data to
InnoDBinternal temporary tables on disk. A setting of 0 disables allocation of memory from memory-mapped temporary files. For more information, see Section 8.4.4, “Internal Temporary Table Use in MySQL”. -
Command-Line Format --temptable-max-ram=#System Variable temptable_max_ramScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 1073741824Minimum Value 2097152Maximum Value 2^64-1Defines the maximum amount of memory that can be occupied by the
TempTablestorage engine before it starts storing data on disk. The default value is 1073741824 bytes (1GiB). For more information, see Section 8.4.4, “Internal Temporary Table Use in MySQL”. -
Command-Line Format --temptable-use-mmap[={OFF|ON}]Introduced 8.0.16 System Variable temptable_use_mmapScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value ONDefines whether the TempTable storage engine allocates space for internal in-memory temporary tables as memory-mapped temporary files when the amount of memory occupied by the TempTable storage engine exceeds the limit defined by the
temptable_max_ramvariable. Whentemptable_use_mmapis disabled, the TempTable storage engine usesInnoDBon-disk internal temporary tables instead. For more information, see Section 8.4.4, “Internal Temporary Table Use in MySQL”. -
Command-Line Format --thread-cache-size=#System Variable thread_cache_sizeScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value -1(signifies autosizing; do not assign this literal value)Minimum Value 0Maximum Value 16384How many threads the server should cache for reuse. When a client disconnects, the client's threads are put in the cache if there are fewer than
thread_cache_sizethreads there. Requests for threads are satisfied by reusing threads taken from the cache if possible, and only when the cache is empty is a new thread created. This variable can be increased to improve performance if you have a lot of new connections. Normally, this does not provide a notable performance improvement if you have a good thread implementation. However, if your server sees hundreds of connections per second you should normally setthread_cache_sizehigh enough so that most new connections use cached threads. By examining the difference between theConnectionsandThreads_createdstatus variables, you can see how efficient the thread cache is. For details, see Section 5.1.10, “Server Status Variables”.The default value is based on the following formula, capped to a limit of 100:
8 + (max_connections / 100)
-
Command-Line Format --thread-handling=nameSystem Variable thread_handlingScope Global Dynamic No SET_VARHint AppliesNo Type Enumeration Default Value one-thread-per-connectionValid Values no-threadsone-thread-per-connectionloaded-dynamicallyThe thread-handling model used by the server for connection threads. The permissible values are
no-threads(the server uses a single thread to handle one connection),one-thread-per-connection(the server uses one thread to handle each client connection), andloaded-dynamically(set by the thread pool plugin when it initializes).no-threadsis useful for debugging under Linux; see Section 5.9, “Debugging MySQL”. -
Command-Line Format --thread-pool-algorithm=#System Variable thread_pool_algorithmScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 1This variable controls which algorithm the thread pool plugin uses:
A value of 0 (the default) uses a conservative low-concurrency algorithm which is most well tested and is known to produce very good results.
A value of 1 increases the concurrency and uses a more aggressive algorithm which at times has been known to perform 5–10% better on optimal thread counts, but has degrading performance as the number of connections increases. Its use should be considered as experimental and not supported.
This variable is available only if the thread pool plugin is enabled. See Section 5.6.3, “MySQL Enterprise Thread Pool”.
thread_pool_high_priority_connectionCommand-Line Format --thread-pool-high-priority-connection=#System Variable thread_pool_high_priority_connectionScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 1This variable affects queuing of new statements prior to execution. If the value is 0 (false, the default), statement queuing uses both the low-priority and high-priority queues. If the value is 1 (true), queued statements always go to the high-priority queue.
This variable is available only if the thread pool plugin is enabled. See Section 5.6.3, “MySQL Enterprise Thread Pool”.
thread_pool_max_active_query_threadsCommand-Line Format --thread-pool-max-active-query-threadsIntroduced 8.0.19 System Variable thread_pool_max_active_query_threadsScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 512The maximum permissible number of active (running) query threads per group. If the value is 0, the thread pool plugin uses up to as many threads as are available.
This variable is available only if the thread pool plugin is enabled. See Section 5.6.3, “MySQL Enterprise Thread Pool”.
thread_pool_max_unused_threadsCommand-Line Format --thread-pool-max-unused-threads=#System Variable thread_pool_max_unused_threadsScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 4096The maximum permitted number of unused threads in the thread pool. This variable makes it possible to limit the amount of memory used by sleeping threads.
A value of 0 (the default) means no limit on the number of sleeping threads. A value of
NwhereNis greater than 0 means 1 consumer thread andN−1 reserve threads. In this case, if a thread is ready to sleep but the number of sleeping threads is already at the maximum, the thread exits rather than going to sleep.A sleeping thread is either sleeping as a consumer thread or a reserve thread. The thread pool permits one thread to be the consumer thread when sleeping. If a thread goes to sleep and there is no existing consumer thread, it sleeps as a consumer thread. When a thread must be woken up, a consumer thread is selected if there is one. A reserve thread is selected only when there is no consumer thread to wake up.
This variable is available only if the thread pool plugin is enabled. See Section 5.6.3, “MySQL Enterprise Thread Pool”.
-
Command-Line Format --thread-pool-prio-kickup-timer=#System Variable thread_pool_prio_kickup_timerScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 1000Minimum Value 0Maximum Value 4294967294This variable affects statements waiting for execution in the low-priority queue. The value is the number of milliseconds before a waiting statement is moved to the high-priority queue. The default is 1000 (1 second).
This variable is available only if the thread pool plugin is enabled. See Section 5.6.3, “MySQL Enterprise Thread Pool”.
-
Command-Line Format --thread-pool-size=#System Variable thread_pool_sizeScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value 16Minimum Value 1Maximum Value (≥ 8.0.19) 512Maximum Value (≤ 8.0.18) 64The number of thread groups in the thread pool. This is the most important parameter controlling thread pool performance. It affects how many statements can execute simultaneously. If a value outside the range of permissible values is specified, the thread pool plugin does not load and the server writes a message to the error log.
This variable is available only if the thread pool plugin is enabled. See Section 5.6.3, “MySQL Enterprise Thread Pool”.
-
Command-Line Format --thread-pool-stall-limit=#System Variable thread_pool_stall_limitScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 6Minimum Value 4Maximum Value 600This variable affects executing statements. The value is the amount of time a statement has to finish after starting to execute before it becomes defined as stalled, at which point the thread pool permits the thread group to begin executing another statement. The value is measured in 10 millisecond units, so the default of 6 means 60ms. Short wait values permit threads to start more quickly. Short values are also better for avoiding deadlock situations. Long wait values are useful for workloads that include long-running statements, to avoid starting too many new statements while the current ones execute.
This variable is available only if the thread pool plugin is enabled. See Section 5.6.3, “MySQL Enterprise Thread Pool”.
-
Command-Line Format --thread-stack=#System Variable thread_stackScope Global Dynamic No SET_VARHint AppliesNo Type Integer Default Value (64-bit platforms) 286720Default Value (32-bit platforms) 221184Minimum Value 131072Maximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295Block Size 1024The stack size for each thread. The default is large enough for normal operation. If the thread stack size is too small, it limits the complexity of the SQL statements that the server can handle, the recursion depth of stored procedures, and other memory-consuming actions.
-
System Variable time_zoneScope Global, Session Dynamic Yes SET_VARHint Applies (≥ 8.0.17)Yes SET_VARHint Applies (≤ 8.0.16)No Type String Default Value SYSTEMMinimum Value (≥ 8.0.19) -14:00Minimum Value (≤ 8.0.18) -12:59Maximum Value (≥ 8.0.19) +14:00Maximum Value (≤ 8.0.18) +13:00The current time zone. This variable is used to initialize the time zone for each client that connects. By default, the initial value of this is
'SYSTEM'(which means, “use the value ofsystem_time_zone”). The value can be specified explicitly at server startup with the--default-time-zoneoption. See Section 5.1.15, “MySQL Server Time Zone Support”.NoteIf set to
SYSTEM, every MySQL function call that requires a time zone calculation makes a system library call to determine the current system time zone. This call may be protected by a global mutex, resulting in contention. -
System Variable timestampScope Session Dynamic Yes SET_VARHint AppliesYes Type Numeric Default Value UNIX_TIMESTAMP()Minimum Value 1Maximum Value 2147483647Set the time for this client. This is used to get the original timestamp if you use the binary log to restore rows.
timestamp_valueshould be a Unix epoch timestamp (a value like that returned byUNIX_TIMESTAMP(), not a value in'format) orYYYY-MM-DD hh:mm:ss'DEFAULT.Setting
timestampto a constant value causes it to retain that value until it is changed again. SettingtimestamptoDEFAULTcauses its value to be the current date and time as of the time it is accessed.timestampis aDOUBLErather thanBIGINTbecause its value includes a microseconds part. The maximum value corresponds to'2038-01-19 03:14:07'UTC, the same as for theTIMESTAMPdata type.SET timestampaffects the value returned byNOW()but not bySYSDATE(). This means that timestamp settings in the binary log have no effect on invocations ofSYSDATE(). The server can be started with the--sysdate-is-nowoption to causeSYSDATE()to be a synonym forNOW(), in which caseSET timestampaffects both functions. -
Command-Line Format --tls-ciphersuites=ciphersuite_listIntroduced 8.0.16 System Variable tls_ciphersuitesScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value NULLWhich ciphersuites the server permits for encrypted connections that use TLSv1.3. The value is a list of zero or more colon-separated ciphersuite names.
The ciphersuites that can be named for this variable depend on the SSL library used to compile MySQL. If this variable is not set, its default value is
NULL, which means that the server permits the default set of ciphersuites. If the variable is set to the empty string, no ciphersuites are enabled and encrypted connections cannot be established. For more information, see Section 6.3.2, “Encrypted Connection TLS Protocols and Ciphers”. -
Command-Line Format --tls-version=protocol_listSystem Variable tls_versionScope Global Dynamic (≥ 8.0.16) Yes Dynamic (≤ 8.0.15) No SET_VARHint AppliesNo Type String Default Value (≥ 8.0.16) TLSv1,TLSv1.1,TLSv1.2,TLSv1.3(OpenSSL 1.1.1 and higher)TLSv1,TLSv1.1,TLSv1.2(otherwise)Default Value (≤ 8.0.15) TLSv1,TLSv1.1,TLSv1.2Which protocols the server permits for encrypted connections. The value is a list of one or more comma-separated protocol names. The protocols that can be named for this variable depend on the SSL library used to compile MySQL. Permitted protocols should be chosen such as not to leave “holes” in the list. For details, see Section 6.3.2, “Encrypted Connection TLS Protocols and Ciphers”.
As of MySQL 8.0.16, this variable is dynamic and can be modified at runtime to affect the TSL context the server uses for new connections. See Server-Side Runtime Configuration and Monitoring for Encrypted Connections. Prior to MySQL 8.0.16, this variable can be set only at server startup.
-
Command-Line Format --tmp-table-size=#System Variable tmp_table_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Integer Default Value 16777216Minimum Value 1024Maximum Value 18446744073709551615The maximum size of internal in-memory temporary tables. This variable does not apply to user-created
MEMORYtables.The actual limit is the smaller of
tmp_table_sizeandmax_heap_table_size. When an in-memory temporary table exceeds the limit, MySQL automatically converts it to an on-disk temporary table.Increase the value of
tmp_table_size(andmax_heap_table_sizeif necessary) if you do many advancedGROUP BYqueries and you have lots of memory.You can compare the number of internal on-disk temporary tables created to the total number of internal temporary tables created by comparing
Created_tmp_disk_tablesandCreated_tmp_tablesvalues.See also Section 8.4.4, “Internal Temporary Table Use in MySQL”.
-
Command-Line Format --tmpdir=dir_nameSystem Variable tmpdirScope Global Dynamic No SET_VARHint AppliesNo Type Directory name The path of the directory to use for creating temporary files. It might be useful if your default
/tmpdirectory resides on a partition that is too small to hold temporary tables. This variable can be set to a list of several paths that are used in round-robin fashion. Paths should be separated by colon characters (:) on Unix and semicolon characters (;) on Windows.tmpdircan be a non-permanent location, such as a directory on a memory-based file system or a directory that is cleared when the server host restarts. If the MySQL server is acting as a replica, and you are using a non-permanent location fortmpdir, consider setting a different temporary directory for the replica using theslave_load_tmpdirvariable. For a replica, the temporary files used to replicateLOAD DATAstatements are stored in this directory, so with a permanent location they can survive machine restarts, although replication can now continue after a restart if the temporary files have been removed.For more information about the storage location of temporary files, see Section B.3.3.5, “Where MySQL Stores Temporary Files”.
-
Command-Line Format --transaction-alloc-block-size=#System Variable transaction_alloc_block_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 8192Minimum Value 1024Maximum Value 131072Block Size 1024The amount in bytes by which to increase a per-transaction memory pool which needs memory. See the description of
transaction_prealloc_size. -
Command-Line Format --transaction-isolation=nameSystem Variable transaction_isolationScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value REPEATABLE-READValid Values READ-UNCOMMITTEDREAD-COMMITTEDREPEATABLE-READSERIALIZABLEThe transaction isolation level. The default is
REPEATABLE-READ.The transaction isolation level has three scopes: global, session, and next transaction. This three-scope implementation leads to some nonstandard isolation-level assignment semantics, as described later.
To set the global transaction isolation level at startup, use the
--transaction-isolationserver option.At runtime, the isolation level can be set directly using the
SETstatement to assign a value to thetransaction_isolationsystem variable, or indirectly using theSET TRANSACTIONstatement. If you settransaction_isolationdirectly to an isolation level name that contains a space, the name should be enclosed within quotation marks, with the space replaced by a dash. For example, use thisSETstatement to set the global value:SET GLOBAL transaction_isolation = 'READ-COMMITTED';
Setting the global
transaction_isolationvalue sets the isolation level for all subsequent sessions. Existing sessions are unaffected.To set the session or next-level
transaction_isolationvalue, use theSETstatement. For most session system variables, these statements are equivalent ways to set the value:SET @@SESSION.
var_name=value; SET SESSIONvar_name=value; SETvar_name=value; SET @@var_name=value;As mentioned previously, the transaction isolation level has a next-transaction scope, in addition to the global and session scopes. To enable the next-transaction scope to be set,
SETsyntax for assigning session system variable values has nonstandard semantics fortransaction_isolation:To set the session isolation level, use any of these syntaxes:
SET @@SESSION.transaction_isolation =
value; SET SESSION transaction_isolation =value; SET transaction_isolation =value;For each of those syntaxes, these semantics apply:
Sets the isolation level for all subsequent transactions performed within the session.
Permitted within transactions, but does not affect the current ongoing transaction.
If executed between transactions, overrides any preceding statement that sets the next-transaction isolation level.
Corresponds to
SET SESSION TRANSACTION ISOLATION LEVEL(with theSESSIONkeyword).
To set the next-transaction isolation level, use this syntax:
SET @@transaction_isolation =
value;For that syntax, these semantics apply:
Sets the isolation level only for the next single transaction performed within the session.
Subsequent transactions revert to the session isolation level.
Not permitted within transactions.
Corresponds to
SET TRANSACTION ISOLATION LEVEL(without theSESSIONkeyword).
For more information about
SET TRANSACTIONand its relationship to thetransaction_isolationsystem variable, see Section 13.3.7, “SET TRANSACTION Statement”. -
Command-Line Format --transaction-prealloc-size=#System Variable transaction_prealloc_sizeScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 4096Minimum Value 1024Maximum Value 131072Block Size 1024There is a per-transaction memory pool from which various transaction-related allocations take memory. The initial size of the pool in bytes is
transaction_prealloc_size. For every allocation that cannot be satisfied from the pool because it has insufficient memory available, the pool is increased bytransaction_alloc_block_sizebytes. When the transaction ends, the pool is truncated totransaction_prealloc_sizebytes.By making
transaction_prealloc_sizesufficiently large to contain all statements within a single transaction, you can avoid manymalloc()calls. -
Command-Line Format --transaction-read-only[={OFF|ON}]System Variable transaction_read_onlyScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFThe transaction access mode. The value can be
OFF(read/write; the default) orON(read only).The transaction access mode has three scopes: global, session, and next transaction. This three-scope implementation leads to some nonstandard access-mode assignment semantics, as described later.
To set the global transaction access mode at startup, use the
--transaction-read-onlyserver option.At runtime, the access mode can be set directly using the
SETstatement to assign a value to thetransaction_read_onlysystem variable, or indirectly using theSET TRANSACTIONstatement. For example, use thisSETstatement to set the global value:SET GLOBAL transaction_read_only = ON;
Setting the global
transaction_read_onlyvalue sets the access mode for all subsequent sessions. Existing sessions are unaffected.To set the session or next-level
transaction_read_onlyvalue, use theSETstatement. For most session system variables, these statements are equivalent ways to set the value:SET @@SESSION.
var_name=value; SET SESSIONvar_name=value; SETvar_name=value; SET @@var_name=value;As mentioned previously, the transaction access mode has a next-transaction scope, in addition to the global and session scopes. To enable the next-transaction scope to be set,
SETsyntax for assigning session system variable values has nonstandard semantics fortransaction_read_only,To set the session access mode, use any of these syntaxes:
SET @@SESSION.transaction_read_only =
value; SET SESSION transaction_read_only =value; SET transaction_read_only =value;For each of those syntaxes, these semantics apply:
Sets the access mode for all subsequent transactions performed within the session.
Permitted within transactions, but does not affect the current ongoing transaction.
If executed between transactions, overrides any preceding statement that sets the next-transaction access mode.
Corresponds to
SET SESSION TRANSACTION {READ WRITE | READ ONLY}(with theSESSIONkeyword).
To set the next-transaction access mode, use this syntax:
SET @@transaction_read_only =
value;For that syntax, these semantics apply:
Sets the access mode only for the next single transaction performed within the session.
Subsequent transactions revert to the session access mode.
Not permitted within transactions.
Corresponds to
SET TRANSACTION {READ WRITE | READ ONLY}(without theSESSIONkeyword).
For more information about
SET TRANSACTIONand its relationship to thetransaction_read_onlysystem variable, see Section 13.3.7, “SET TRANSACTION Statement”. -
System Variable unique_checksScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Boolean Default Value ONIf set to 1 (the default), uniqueness checks for secondary indexes in
InnoDBtables are performed. If set to 0, storage engines are permitted to assume that duplicate keys are not present in input data. If you know for certain that your data does not contain uniqueness violations, you can set this to 0 to speed up large table imports toInnoDB.Setting this variable to 0 does not require storage engines to ignore duplicate keys. An engine is still permitted to check for them and issue duplicate-key errors if it detects them.
-
Command-Line Format --updatable-views-with-limit[={OFF|ON}]System Variable updatable_views_with_limitScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Boolean Default Value 1This variable controls whether updates to a view can be made when the view does not contain all columns of the primary key defined in the underlying table, if the update statement contains a
LIMITclause. (Such updates often are generated by GUI tools.) An update is anUPDATEorDELETEstatement. Primary key here means aPRIMARY KEY, or aUNIQUEindex in which no column can containNULL.The variable can have two values:
1orYES: Issue a warning only (not an error message). This is the default value.0orNO: Prohibit the update.
-
Introduced 8.0.13 System Variable use_secondary_engineScope Session Dynamic Yes SET_VARHint AppliesYes Type Enumeration Default Value ONValid Values OFFONFORCEDFor future use.
Whether to execute queries using a secondary engine.
For use with HeatWave. See HeatWave User Guide.
validate_password.xxxThe
validate_passwordcomponent implements a set of system variables having names of the formvalidate_password.. These variables affect password testing by that component; see Section 6.4.3.2, “Password Validation Options and Variables”.xxx-
Command-Line Format --validate-user-plugins[={OFF|ON}]System Variable validate_user_pluginsScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value ONIf this variable is enabled (the default), the server checks each user account and produces a warning if conditions are found that would make the account unusable:
The account requires an authentication plugin that is not loaded.
The account requires the
sha256_passwordorcaching_sha2_passwordauthentication plugin but the server was started with neither SSL nor RSA enabled as required by the plugin.
Enabling
validate_user_pluginsslows down server initialization andFLUSH PRIVILEGES. If you do not require the additional checking, you can disable this variable at startup to avoid the performance decrement. The version number for the server. The value might also include a suffix indicating server build or configuration information.
-debugindicates that the server was built with debugging support enabled.-
System Variable version_commentScope Global Dynamic No SET_VARHint AppliesNo Type String The CMake configuration program has a
COMPILATION_COMMENT_SERVERoption that permits a comment to be specified when building MySQL. This variable contains the value of that comment. (Prior to MySQL 8.0.14,version_commentis set by theCOMPILATION_COMMENToption.) See Section 2.9.7, “MySQL Source-Configuration Options”. -
System Variable version_compile_machineScope Global Dynamic No SET_VARHint AppliesNo Type String The type of the server binary.
-
System Variable version_compile_osScope Global Dynamic No SET_VARHint AppliesNo Type String The type of operating system on which MySQL was built.
-
System Variable version_compile_zlibScope Global Dynamic No SET_VARHint AppliesNo Type String The version of the compiled-in
zliblibrary. -
Command-Line Format --wait-timeout=#System Variable wait_timeoutScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 28800Minimum Value 1Maximum Value (Other) 31536000Maximum Value (Windows) 2147483The number of seconds the server waits for activity on a noninteractive connection before closing it.
On thread startup, the session
wait_timeoutvalue is initialized from the globalwait_timeoutvalue or from the globalinteractive_timeoutvalue, depending on the type of client (as defined by theCLIENT_INTERACTIVEconnect option tomysql_real_connect()). See alsointeractive_timeout. The number of errors, warnings, and notes that resulted from the last statement that generated messages. This variable is read only. See Section 13.7.7.42, “SHOW WARNINGS Statement”.
-
Command-Line Format --windowing-use-high-precision[={OFF|ON}]System Variable windowing_use_high_precisionScope Global, Session Dynamic Yes SET_VARHint AppliesYes Type Boolean Default Value ONWhether to compute window operations without loss of precision. See Section 8.2.1.21, “Window Function Optimization”.
The MySQL server maintains many system variables that configure
its operation. Section 5.1.8, “Server System Variables”,
describes the meaning of these variables. Each system variable has
a default value. System variables can be set at server startup
using options on the command line or in an option file. Most of
them can be changed dynamically while the server is running by
means of the
SET
statement, which enables you to modify operation of the server
without having to stop and restart it. You can also use system
variable values in expressions.
Many system variables are built in. System variables may also be installed by server plugins or components:
System variables implemented by a server plugin are exposed when the plugin is installed and have names that begin with the plugin name. For example, the
audit_logplugin implements a system variable namedaudit_log_policy.System variables implemented by a component are exposed when the component is installed and have names that begin with a component-specific prefix. For example, the
log_filter_dragneterror log filter component implements a system variable namedlog_error_filter_rules, the full name of which isdragnet.log_error_filter_rules. To refer to this variable, use the full name.
There are two scopes in which system variables exist. Global variables affect the overall operation of the server. Session variables affect its operation for individual client connections. A given system variable can have both a global and a session value. Global and session system variables are related as follows:
When the server starts, it initializes each global variable to its default value. These defaults can be changed by options specified on the command line or in an option file. (See Section 4.2.2, “Specifying Program Options”.)
The server also maintains a set of session variables for each client that connects. The client's session variables are initialized at connect time using the current values of the corresponding global variables. For example, a client's SQL mode is controlled by the session
sql_modevalue, which is initialized when the client connects to the value of the globalsql_modevalue.For some system variables, the session value is not initialized from the corresponding global value; if so, that is indicated in the variable description.
System variable values can be set globally at server startup by
using options on the command line or in an option file. At
startup, the syntax for system variables is the same as for
command options, so within variable names, dashes and underscores
may be used interchangeably. For example,
--general_log=ON and
--general-log=ON are equivalent.
When you use a startup option to set a variable that takes a
numeric value, the value can be given with a suffix of
K, M, or
G (either uppercase or lowercase) to indicate a
multiplier of 1024, 10242 or
10243; that is, units of kilobytes,
megabytes, or gigabytes, respectively. As of MySQL 8.0.14, a
suffix can also be T, P, and
E to indicate a multiplier of
10244, 10245
or 10246. Thus, the following command
starts the server with an InnoDB log file size
of 16 megabytes and a maximum packet size of one gigabyte:
mysqld --innodb-log-file-size=16M --max-allowed-packet=1G
Within an option file, those variables are set like this:
[mysqld] innodb_log_file_size=16M max_allowed_packet=1G
The lettercase of suffix letters does not matter;
16M and 16m are equivalent,
as are 1G and 1g.
To restrict the maximum value to which a system variable can be
set at runtime with the
SET
statement, specify this maximum by using an option of the form
--maximum-
at server startup. For example, to prevent the value of
var_name=valueinnodb_log_file_size from being
increased to more than 32MB at runtime, use the option
--maximum-innodb-log-file-size=32M.
Many system variables are dynamic and can be changed at runtime by
using the
SET
statement. For a list, see
Section 5.1.9.2, “Dynamic System Variables”. To change a system
variable with
SET, refer
to it by name, optionally preceded by a modifier. At runtime,
system variable names must be written using underscores, not
dashes. The following examples briefly illustrate this syntax:
Set a global system variable:
SET GLOBAL max_connections = 1000; SET @@GLOBAL.max_connections = 1000;
Persist a global system variable to the
mysqld-auto.cnffile (and set the runtime value):SET PERSIST max_connections = 1000; SET @@PERSIST.max_connections = 1000;
Persist a global system variable to the
mysqld-auto.cnffile (without setting the runtime value):SET PERSIST_ONLY back_log = 1000; SET @@PERSIST_ONLY.back_log = 1000;
Set a session system variable:
SET SESSION sql_mode = 'TRADITIONAL'; SET @@SESSION.sql_mode = 'TRADITIONAL'; SET @@sql_mode = 'TRADITIONAL';
For complete details about
SET
syntax, see Section 13.7.6.1, “SET Syntax for Variable Assignment”. For a description of
the privilege requirements for setting and persisting system
variables, see Section 5.1.9.1, “System Variable Privileges”
Suffixes for specifying a value multiplier can be used when
setting a variable at server startup, but not to set the value
with SET
at runtime. On the other hand, with
SET you
can assign a variable's value using an expression, which is not
true when you set a variable at server startup. For example, the
first of the following lines is legal at server startup, but the
second is not:
shell>mysql --max_allowed_packet=16Mshell>mysql --max_allowed_packet=16*1024*1024
Conversely, the second of the following lines is legal at runtime, but the first is not:
mysql>SET GLOBAL max_allowed_packet=16M;mysql>SET GLOBAL max_allowed_packet=16*1024*1024;
Some system variables can be enabled with the
SET
statement by setting them to ON or
1, or disabled by setting them to
OFF or 0. However, to set
such a variable on the command line or in an option file, you
must set it to 1 or 0;
setting it to ON or OFF
does not work. For example, on the command line,
--delay_key_write=1 works but
--delay_key_write=ON does not.
To display system variable names and values, use the
SHOW VARIABLES statement:
mysql> SHOW VARIABLES;
+---------------------------------+-----------------------------------+
| Variable_name | Value |
+---------------------------------+-----------------------------------+
| auto_increment_increment | 1 |
| auto_increment_offset | 1 |
| automatic_sp_privileges | ON |
| back_log | 151 |
| basedir | /home/mysql/ |
| binlog_cache_size | 32768 |
| bulk_insert_buffer_size | 8388608 |
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8mb4 |
| character_set_system | utf8 |
| character_sets_dir | /home/mysql/share/mysql/charsets/ |
| collation_connection | utf8_general_ci |
| collation_database | utf8mb4_0900_ai_ci |
| collation_server | utf8mb4_0900_ai_ci |
...
| innodb_autoextend_increment | 8 |
| innodb_buffer_pool_size | 8388608 |
| innodb_commit_concurrency | 0 |
| innodb_concurrency_tickets | 500 |
| innodb_data_file_path | ibdata1:10M:autoextend |
| innodb_data_home_dir | |
...
| version | 8.0.1-dmr-log |
| version_comment | Source distribution |
| version_compile_machine | i686 |
| version_compile_os | suse-linux |
| wait_timeout | 28800 |
+---------------------------------+-----------------------------------+
With a LIKE clause, the statement
displays only those variables that match the pattern. To obtain a
specific variable name, use a LIKE
clause as shown:
SHOW VARIABLES LIKE 'max_join_size'; SHOW SESSION VARIABLES LIKE 'max_join_size';
To get a list of variables whose name match a pattern, use the
% wildcard character in a
LIKE clause:
SHOW VARIABLES LIKE '%size%'; SHOW GLOBAL VARIABLES LIKE '%size%';
Wildcard characters can be used in any position within the pattern
to be matched. Strictly speaking, because _ is
a wildcard that matches any single character, you should escape it
as \_ to match it literally. In practice, this
is rarely necessary.
For SHOW VARIABLES, if you specify
neither GLOBAL nor SESSION,
MySQL returns SESSION values.
The reason for requiring the GLOBAL keyword
when setting GLOBAL-only variables but not when
retrieving them is to prevent problems in the future:
Were a
SESSIONvariable to be removed that has the same name as aGLOBALvariable, a client with privileges sufficient to modify global variables might accidentally change theGLOBALvariable rather than just theSESSIONvariable for its own session.Were a
SESSIONvariable to be added with the same name as aGLOBALvariable, a client that intends to change theGLOBALvariable might find only its ownSESSIONvariable changed.
A system variable can have a global value that affects server operation as a whole, a session value that affects only the current session, or both:
For dynamic system variables, the
SETstatement can be used to change their global or session runtime value (or both), to affect operation of the current server instance. (For information about dynamic variables, see Section 5.1.9.2, “Dynamic System Variables”.)For certain global system variables,
SETcan be used to persist their value to themysqld-auto.cnffile in the data directory, to affect server operation for subsequent startups. (For information about persisting system variables and themysqld-auto.cnffile, see Section 5.1.9.3, “Persisted System Variables”.)For persisted global system variables,
RESET PERSISTcan be used to remove their value frommysqld-auto.cnf, to affect server operation for subsequent startups.
This section describes the privileges required for operations that assign values to system variables at runtime. This includes operations that affect runtime values, and operations that persist values.
To set a global system variable, use a
SET
statement with the appropriate keyword. These privileges apply:
To set a global system variable runtime value, use the
SET GLOBALstatement, which requires theSYSTEM_VARIABLES_ADMINprivilege (or the deprecatedSUPERprivilege).To persist a global system variable to the
mysqld-auto.cnffile (and set the runtime value), use theSET PERSISTstatement, which requires theSYSTEM_VARIABLES_ADMINorSUPERprivilege.To persist a global system variable to the
mysqld-auto.cnffile (without setting the runtime value), use theSET PERSIST_ONLYstatement, which requires theSYSTEM_VARIABLES_ADMINandPERSIST_RO_VARIABLES_ADMINprivileges.SET PERSIST_ONLYcan be used for both dynamic and read-only system variables, but is particularly useful for persisting read-only variables, for whichSET PERSISTcannot be used.Some global system variables are persist-restricted (see Section 5.1.9.4, “Nonpersistible and Persist-Restricted System Variables”). To persist these variables, use the
SET PERSIST_ONLYstatement, which requires the privileges described previously. In addition, you must connect to the server using an encrypted connection and supply an SSL certificate with the Subject value specified by thepersist_only_admin_x509_subjectsystem variable.
To remove a persisted global system variable from the
mysqld-auto.cnf file, use the
RESET PERSIST statement. These
privileges apply:
For dynamic system variables,
RESET PERSISTrequires theSYSTEM_VARIABLES_ADMINorSUPERprivilege.For read-only system variables,
RESET PERSISTrequires theSYSTEM_VARIABLES_ADMINandPERSIST_RO_VARIABLES_ADMINprivileges.For persist-restricted variables,
RESET PERSISTdoes not require an encrypted connection to the server made using a particular SSL certificate.
If a global system variable has any exceptions to the preceding
privilege requirements, the variable description indicates those
exceptions. Examples include
default_table_encryption and
mandatory_roles, which require
additional privileges. These additional privileges apply to
operations that set the global runtime value, but not operations
that persist the value.
To set a session system variable runtime value, use the
SET
SESSION statement. In contrast to setting global
runtime values, setting session runtime values normally requires
no special privileges and can be done by any user to affect the
current session. For some system variables, setting the session
value may have effects outside the current session and thus is a
restricted operation that can be done only by users who have a
special privilege:
As of MySQL 8.0.14, the privilege required is
SESSION_VARIABLES_ADMIN.NoteAny user who has
SYSTEM_VARIABLES_ADMINorSUPEReffectively hasSESSION_VARIABLES_ADMINby implication and need not be grantedSESSION_VARIABLES_ADMINexplicitly.Prior to MySQL 8.0.14, the privilege required is
SYSTEM_VARIABLES_ADMINorSUPER.
If a session system variable is restricted, the variable
description indicates that restriction. Examples include
binlog_format and
sql_log_bin. Setting the
session value of these variables affects binary logging for the
current session, but may also have wider implications for the
integrity of server replication and backups.
SESSION_VARIABLES_ADMIN enables
administrators to minimize the privilege footprint of users who
may previously have been granted
SYSTEM_VARIABLES_ADMIN or
SUPER for the purpose of enabling
them to modify restricted session system variables. Suppose that
an administrator has created the following role to confer the
ability to set restricted session system variables:
CREATE ROLE set_session_sysvars; GRANT SYSTEM_VARIABLES_ADMIN ON *.* TO set_session_sysvars;
Any user granted the set_session_sysvars role
(and who has that role active) is able to set restricted session
system variables. However, that user is also able to set global
system variables, which may be undesirable.
By modifying the role to have
SESSION_VARIABLES_ADMIN instead
of SYSTEM_VARIABLES_ADMIN, the
role privileges can be reduced to the ability to set restricted
session system variables and nothing else. To modify the role,
use these statements:
GRANT SESSION_VARIABLES_ADMIN ON *.* TO set_session_sysvars; REVOKE SYSTEM_VARIABLES_ADMIN ON *.* FROM set_session_sysvars;
Modifying the role has an immediate effect: Any account granted
the set_session_sysvars role no longer has
SYSTEM_VARIABLES_ADMIN and is not
able to set global system variables without being granted that
ability explicitly. A similar
GRANT/REVOKE
sequence can be applied to any account that was granted
SYSTEM_VARIABLES_ADMIN directly
rather than by means of a role.
Many server system variables are dynamic and can be set at runtime. See Section 13.7.6.1, “SET Syntax for Variable Assignment”. For a description of the privilege requirements for setting system variables, see Section 5.1.9.1, “System Variable Privileges”
The following table lists all dynamic system variables
applicable within mysqld.
The table lists each variable's data type and scope. The last column indicates whether the scope for each variable is Global, Session, or both. Please see the corresponding item descriptions for details on setting and using the variables. Where appropriate, direct links to further information about the items are provided.
Variables that have a type of “string” take a
string value. Variables that have a type of
“numeric” take a numeric value. Variables that have
a type of “boolean” can be set to 0, 1,
ON or OFF. Variables that
are marked as “enumeration” normally should be set
to one of the available values for the variable, but can also be
set to the number that corresponds to the desired enumeration
value. For enumerated system variables, the first enumeration
value corresponds to 0. This differs from the
ENUM data type used for table
columns, for which the first enumeration value corresponds to 1.
Table 5.4 Dynamic System Variable Summary
The MySQL server maintains system variables that configure its
operation. A system variable can have a global value that
affects server operation as a whole, a session value that
affects the current session, or both. Many system variables are
dynamic and can be changed at runtime using the
SET
statement to affect operation of the current server instance.
SET can
also be used to persist certain global system variables to the
mysqld-auto.cnf file in the data directory,
to affect server operation for subsequent startups.
RESET PERSIST removes persisted
settings from mysqld-auto.cnf.
The following discussion describes aspects of persisting system variables:
The capability of persisting global system variables at
runtime enables server configuration that persists across
server startups. Although many system variables can be set at
startup from a my.cnf option file, or at
runtime using the
SET
statement, those methods of configuring the server either
require login access to the server host, or do not provide the
capability of persistently configuring the server at runtime
or remotely:
Modifying an option file requires direct access to that file, which requires login access to the MySQL server host. This is not always convenient.
Modifying system variables with
SET GLOBALis a runtime capability that can be done from clients run locally or from remote hosts, but the changes affect only the currently running server instance. The settings are not persistent and do not carry over to subsequent server startups.
To augment administrative capabilities for server
configuration beyond what is achievable by editing option
files or using
SET
GLOBAL, MySQL provides variants of
SET
syntax that persist system variable settings to a file named
mysqld-auto.cnf file in the data
directory. Examples:
SET PERSIST max_connections = 1000; SET @@PERSIST.max_connections = 1000; SET PERSIST_ONLY back_log = 100; SET @@PERSIST_ONLY.back_log = 100;
MySQL also provides a RESET
PERSIST statement for removing persisted system
variables from mysqld-auto.cnf.
Server configuration performed by persisting system variables has these characteristics:
Persisted settings are made at runtime.
Persisted settings are permanent. They apply across server restarts.
Persisted settings can be made from local clients or clients who connect from a remote host. This provides the convenience of remotely configuring multiple MySQL servers from a central client host.
To persist system variables, you need not have login access to the MySQL server host or file system access to option files. Ability to persist settings is controlled using the MySQL privilege system. See Section 5.1.9.1, “System Variable Privileges”.
An administrator with sufficient privileges can reconfigure a server by persisting system variables, then cause the server to use the changed settings immediately by executing a
RESTARTstatement.Persisted settings provide immediate feedback about errors. An error in a manually entered setting might not be discovered until much later.
SETstatements that persist system variables avoid the possibility of malformed settings because settings with syntax errors do not succeed and do not change server configuration.
These
SET
syntax options are available for persisting system variables:
To persist a global system variable to the
mysqld-auto.cnfoption file in the data directory, precede the variable name by thePERSISTkeyword or the@@PERSIST.qualifier:SET PERSIST max_connections = 1000; SET @@PERSIST.max_connections = 1000;
Like
SET GLOBAL,SET PERSISTsets the global variable runtime value, but also writes the variable setting to themysqld-auto.cnffile (replacing any existing variable setting if there is one).To persist a global system variable to the
mysqld-auto.cnffile without setting the global variable runtime value, precede the variable name by thePERSIST_ONLYkeyword or the@@PERSIST_ONLY.qualifier:SET PERSIST_ONLY back_log = 1000; SET @@PERSIST_ONLY.back_log = 1000;
Like
PERSIST,PERSIST_ONLYwrites the variable setting tomysqld-auto.cnf. However, unlikePERSIST,PERSIST_ONLYdoes not modify the global variable runtime value. This makesPERSIST_ONLYsuitable for configuring read-only system variables that can be set only at server startup.
For more information about
SET,
see Section 13.7.6.1, “SET Syntax for Variable Assignment”.
These RESET PERSIST syntax
options are available for removing persisted system variables:
To remove all persisted variables from
mysqld-auto.cnf, useRESET PERSISTwithout naming any system variable:RESET PERSIST;
To remove a specific persisted variable from
mysqld-auto.cnf, name it in the statement:RESET PERSIST
system_var_name;This includes plugin system variables, even if the plugin is not currently installed. If the variable is not present in the file, an error occurs.
To remove a specific persisted variable from
mysqld-auto.cnf, but produce a warning rather than an error if the variable is not present in the file, add anIF EXISTSclause to the previous syntax:RESET PERSIST IF EXISTS
system_var_name;
For more information about RESET
PERSIST, see Section 13.7.8.7, “RESET PERSIST Statement”.
Using
SET to
persist a global system variable to a value of
DEFAULT or to its literal default value
assigns the variable its default value and adds a setting for
the variable to mysqld-auto.cnf. To
remove the variable from the file, use
RESET PERSIST.
Some system variables cannot be persisted. See Section 5.1.9.4, “Nonpersistible and Persist-Restricted System Variables”.
A system variable implemented by a plugin can be persisted if
the plugin is installed when the
SET
statement is executed. Assignment of the persisted plugin
variable takes effect for subsequent server restarts if the
plugin is still installed. If the plugin is no longer
installed, the plugin variable does not exist when the server
reads the mysqld-auto.cnf file. In this
case, the server writes a warning to the error log and
continues:
currently unknown variable 'var_name'
was read from the persisted config file
The Performance Schema
persisted_variables table
provides an SQL interface to the
mysqld-auto.cnf file, enabling its
contents to be inspected at runtime using
SELECT statements. See
Section 27.12.14.1, “Performance Schema persisted_variables Table”.
The Performance Schema
variables_info table contains
information showing when and by which user each system
variable was most recently set. See
Section 27.12.14.2, “Performance Schema variables_info Table”.
RESET PERSIST affects the
contents of the
persisted_variables table because
the table contents correspond to the contents of the
mysqld-auto.cnf file. On the other hand,
because RESET PERSIST does not
change variable values, it has no effect on the contents of
the variables_info table until
the server is restarted.
The mysqld-auto.cnf file uses a
JSON format like this (reformatted slightly
for readability):
{
"Version": 1,
"mysql_server": {
"max_connections": {
"Value": "152",
"Metadata": {
"Timestamp": 1519921341372531,
"User": "root",
"Host": "localhost"
}
},
"transaction_isolation": {
"Value": "READ-COMMITTED",
"Metadata": {
"Timestamp": 1519921553880520,
"User": "root",
"Host": "localhost"
}
},
"mysql_server_static_options": {
"innodb_api_enable_mdl": {
"Value": "0",
"Metadata": {
"Timestamp": 1519922873467872,
"User": "root",
"Host": "localhost"
}
},
"log_slave_updates": {
"Value": "1",
"Metadata": {
"Timestamp": 1519925628441588,
"User": "root",
"Host": "localhost"
}
}
}
}
}
At startup, the server processes the
mysqld-auto.cnf file after all other
option files (see Section 4.2.2.2, “Using Option Files”). The server
handles the file contents as follows:
If the
persisted_globals_loadsystem variable is disabled, the server ignores themysqld-auto.cnffile.Only read-only variables persisted using
SET PERSIST_ONLYappear in the"mysql_server_static_options"section. All variables present inside this section are appended to the command line and processed with other command-line options.All remaining persisted variables are set by executing the equivalent of a
SET GLOBALstatement later, just before the server starts listening for client connections. These settings therefore do not take effect until late in the startup process, which might be unsuitable for certain system variables. It may be preferable to set such variables inmy.cnfrather than inmysqld-auto.cnf.
Management of the mysqld-auto.cnf file
should be left to the server. Manipulation of the file should
be performed only using
SET
and RESET PERSIST statements,
not manually:
Removal of the file results in a loss of all persisted settings at the next server startup. (This is permissible if your intent is to reconfigure the server without these settings.) To remove all settings in the file without removing the file itself, use this statement:
RESET PERSIST;
Manual changes to the file may result in a parse error at server startup. In this case, the server reports an error and exits. If this issue occurs, start the server with the
persisted_globals_loadsystem variable disabled or with the--no-defaultsoption. Alternatively, remove themysqld-auto.cnffile. However, as noted previously, removing this file results in a loss of all persisted settings.
SET
PERSIST and
SET
PERSIST_ONLY enable global system variables to be
persisted to the mysqld-auto.cnf option
file in the data directory (see Section 13.7.6.1, “SET Syntax for Variable Assignment”).
However, not all system variables can be persisted, or can be
persisted only under certain restrictive conditions. Here are
some reasons why a system variable might be nonpersistible or
persist-restricted:
Session system variables cannot be persisted. Session variables cannot be set at server startup, so there is no reason to persist them.
A global system variable might involve sensitive data such that it should be settable only by a user with direct access to the server host.
A global system variable might be read only (that is, set only by the server). In this case, it cannot be set by users at all, whether at server startup or at runtime.
A global system variable might be intended only for internal use.
Nonpersistible system variables cannot be persisted under any
circumstances. As of MySQL 8.0.14, persist-restricted system
variables can be persisted with
SET
PERSIST_ONLY, but only by users for which the
following conditions are satisfied:
The
persist_only_admin_x509_subjectsystem variable is set to an SSL certificate X.509 Subject value.The user connects to the server using an encrypted connection and supplies an SSL certificate with the designated Subject value.
The user has sufficient privileges to use
SET PERSIST_ONLY(see Section 5.1.9.1, “System Variable Privileges”).
For example, protocol_version
is read only and set only by the server, so it cannot be
persisted under any circumstances. On the other hand,
bind_address is
persist-restricted, so it can be set by users who satisfy the
preceding conditions.
The following system variables are nonpersistible. This list may change with ongoing development.
audit_log_current_session audit_log_filter_id caching_sha2_password_digest_rounds character_set_system core_file have_statement_timeout have_symlink hostname innodb_version keyring_hashicorp_auth_path keyring_hashicorp_ca_path keyring_hashicorp_caching keyring_hashicorp_commit_auth_path keyring_hashicorp_commit_ca_path keyring_hashicorp_commit_caching keyring_hashicorp_commit_role_id keyring_hashicorp_commit_server_url keyring_hashicorp_commit_store_path keyring_hashicorp_role_id keyring_hashicorp_secret_id keyring_hashicorp_server_url keyring_hashicorp_store_path large_files_support large_page_size license locked_in_memory log_bin log_bin_basename log_bin_index lower_case_file_system ndb_version ndb_version_string persist_only_admin_x509_subject persisted_globals_load protocol_version relay_log_basename relay_log_index server_uuid skip_external_locking system_time_zone version_comment version_compile_machine version_compile_os version_compile_zlib
Persist-restricted system variables are those that are read only
and can be set on the command line or in an option file, other
than
persist_only_admin_x509_subject
and persisted_globals_load.
This list may change with ongoing development.
audit_log_file audit_log_format auto_generate_certs basedir bind_address caching_sha2_password_auto_generate_rsa_keys caching_sha2_password_private_key_path caching_sha2_password_public_key_path character_sets_dir daemon_memcached_engine_lib_name daemon_memcached_engine_lib_path daemon_memcached_option datadir default_authentication_plugin ft_stopword_file init_file innodb_buffer_pool_load_at_startup innodb_data_file_path innodb_data_home_dir innodb_dedicated_server innodb_directories innodb_force_load_corrupted innodb_log_group_home_dir innodb_page_size innodb_read_only innodb_temp_data_file_path innodb_temp_tablespaces_dir innodb_undo_directory innodb_undo_tablespaces keyring_encrypted_file_data keyring_encrypted_file_password lc_messages_dir log_error mecab_rc_file named_pipe pid_file plugin_dir port relay_log relay_log_info_file secure_file_priv sha256_password_auto_generate_rsa_keys sha256_password_private_key_path sha256_password_public_key_path shared_memory shared_memory_base_name skip_networking slave_load_tmpdir socket ssl_ca ssl_capath ssl_cert ssl_crl ssl_crlpath ssl_key tmpdir version_tokens_session_number
To configure the server to enable persisting persist-restricted system variables, use this procedure:
Ensure that MySQL is configured to support encrypted connections. See Section 6.3.1, “Configuring MySQL to Use Encrypted Connections”.
Designate an SSL certificate X.509 Subject value that signifies the ability to persist persist-restricted system variables, and generate a certificate that has that Subject. See Section 6.3.3, “Creating SSL and RSA Certificates and Keys”.
Start the server with
persist_only_admin_x509_subjectset to the designated Subject value. For example, put these lines in your servermy.cnffile:[mysqld] persist_only_admin_x509_subject="
subject-value"The format of the Subject value is the same as used for
CREATE USER ... REQUIRE SUBJECT. See Section 13.7.1.3, “CREATE USER Statement”.You must perform this step directly on the MySQL server host because
persist_only_admin_x509_subjectitself cannot be persisted at runtime.Restart the server.
Distribute the SSL certificate that has the designated Subject value to users who are to be permitted to persist persist-restricted system variables.
Suppose that myclient-cert.pem is the SSL
certificate to be used by clients who can persist
persist-restricted system variables. Display the certificate
contents using the openssl command:
shell> openssl x509 -text -in myclient-cert.pem
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 2 (0x2)
Signature Algorithm: md5WithRSAEncryption
Issuer: C=US, ST=IL, L=Chicago, O=MyOrg, OU=CA, CN=MyCN
Validity
Not Before: Oct 18 17:03:03 2018 GMT
Not After : Oct 15 17:03:03 2028 GMT
Subject: C=US, ST=IL, L=Chicago, O=MyOrg, OU=client, CN=MyCN
...
The openssl output shows that the certificate Subject value is:
C=US, ST=IL, L=Chicago, O=MyOrg, OU=client, CN=MyCN
To specify the Subject for MySQL, use this format:
/C=US/ST=IL/L=Chicago/O=MyOrg/OU=client/CN=MyCN
Configure the server my.cnf file with the
Subject value:
[mysqld] persist_only_admin_x509_subject="/C=US/ST=IL/L=Chicago/O=MyOrg/OU=client/CN=MyCN"
Restart the server so that the new configuration takes effect.
Distribute the SSL certificate (and any other associated SSL files) to the appropriate users. Such a user then connects to the server with the certificate and any other SSL options required to establish an encrypted connection.
To use X.509, clients must specify the
--ssl-key and
--ssl-cert options to connect.
It is recommended but not required that
--ssl-ca also be specified so
that the public certificate provided by the server can be
verified. For example:
shell> mysql --ssl-key=myclient-key.pem --ssl-cert=myclient-cert.pem --ssl-ca=mycacert.pem
Assuming that the user has sufficient privileges to use
SET
PERSIST_ONLY, persist-restricted system variables can
be persisted like this:
mysql> SET PERSIST_ONLY socket = '/tmp/mysql.sock';
Query OK, 0 rows affected (0.00 sec)
If the server is not configured to enable persisting persist-restricted system variables, or the user does not satisfy the required conditions for that capability, an error occurs:
mysql> SET PERSIST_ONLY socket = '/tmp/mysql.sock';
ERROR 1238 (HY000): Variable 'socket' is a non persistent read only variable
A structured variable differs from a regular system variable in two respects:
Its value is a structure with components that specify server parameters considered to be closely related.
There might be several instances of a given type of structured variable. Each one has a different name and refers to a different resource maintained by the server.
MySQL supports one structured variable type, which specifies parameters governing the operation of key caches. A key cache structured variable has these components:
This section describes the syntax for referring to structured variables. Key cache variables are used for syntax examples, but specific details about how key caches operate are found elsewhere, in Section 8.10.2, “The MyISAM Key Cache”.
To refer to a component of a structured variable instance, you
can use a compound name in
instance_name.component_name format.
Examples:
hot_cache.key_buffer_size hot_cache.key_cache_block_size cold_cache.key_cache_block_size
For each structured system variable, an instance with the name
of default is always predefined. If you refer
to a component of a structured variable without any instance
name, the default instance is used. Thus,
default.key_buffer_size and
key_buffer_size both refer to
the same system variable.
Structured variable instances and components follow these naming rules:
For a given type of structured variable, each instance must have a name that is unique within variables of that type. However, instance names need not be unique across structured variable types. For example, each structured variable has an instance named
default, sodefaultis not unique across variable types.The names of the components of each structured variable type must be unique across all system variable names. If this were not true (that is, if two different types of structured variables could share component member names), it would not be clear which default structured variable to use for references to member names that are not qualified by an instance name.
If a structured variable instance name is not legal as an unquoted identifier, refer to it as a quoted identifier using backticks. For example,
hot-cacheis not legal, but`hot-cache`is.global,session, andlocalare not legal instance names. This avoids a conflict with notation such as@@GLOBAL.for referring to nonstructured system variables.var_name
Currently, the first two rules have no possibility of being violated because the only structured variable type is the one for key caches. These rules may assume greater significance if some other type of structured variable is created in the future.
With one exception, you can refer to structured variable components using compound names in any context where simple variable names can occur. For example, you can assign a value to a structured variable using a command-line option:
shell> mysqld --hot_cache.key_buffer_size=64K
In an option file, use this syntax:
[mysqld] hot_cache.key_buffer_size=64K
If you start the server with this option, it creates a key cache
named hot_cache with a size of 64KB in
addition to the default key cache that has a default size of
8MB.
Suppose that you start the server as follows:
shell>mysqld --key_buffer_size=256K \--extra_cache.key_buffer_size=128K \--extra_cache.key_cache_block_size=2048
In this case, the server sets the size of the default key cache
to 256KB. (You could also have written
--default.key_buffer_size=256K.) In addition,
the server creates a second key cache named
extra_cache that has a size of 128KB, with
the size of block buffers for caching table index blocks set to
2048 bytes.
The following example starts the server with three different key caches having sizes in a 3:1:1 ratio:
shell>mysqld --key_buffer_size=6M \--hot_cache.key_buffer_size=2M \--cold_cache.key_buffer_size=2M
Structured variable values may be set and retrieved at runtime
as well. For example, to set a key cache named
hot_cache to a size of 10MB, use either of
these statements:
mysql>SET GLOBAL hot_cache.key_buffer_size = 10*1024*1024;mysql>SET @@GLOBAL.hot_cache.key_buffer_size = 10*1024*1024;
To retrieve the cache size, do this:
mysql> SELECT @@GLOBAL.hot_cache.key_buffer_size;
However, the following statement does not work. The variable is
not interpreted as a compound name, but as a simple string for a
LIKE pattern-matching operation:
mysql> SHOW GLOBAL VARIABLES LIKE 'hot_cache.key_buffer_size';
This is the exception to being able to use structured variable names anywhere a simple variable name may occur.
The MySQL server maintains many status variables that provide
information about its operation. You can view these variables and
their values by using the SHOW [GLOBAL | SESSION]
STATUS statement (see Section 13.7.7.37, “SHOW STATUS Statement”).
The optional GLOBAL keyword aggregates the
values over all connections, and SESSION shows
the values for the current connection.
mysql> SHOW GLOBAL STATUS;
+-----------------------------------+------------+
| Variable_name | Value |
+-----------------------------------+------------+
| Aborted_clients | 0 |
| Aborted_connects | 0 |
| Bytes_received | 155372598 |
| Bytes_sent | 1176560426 |
...
| Connections | 30023 |
| Created_tmp_disk_tables | 0 |
| Created_tmp_files | 3 |
| Created_tmp_tables | 2 |
...
| Threads_created | 217 |
| Threads_running | 88 |
| Uptime | 1389872 |
+-----------------------------------+------------+
Many status variables are reset to 0 by the
FLUSH STATUS statement.
This section provides a description of each status variable. For a status variable summary, see Section 5.1.6, “Server Status Variable Reference”. For information about status variables specific to NDB Cluster, see Section 23.3.3.9.3, “NDB Cluster Status Variables”.
The status variables have the following meanings.
The number of connections that were aborted because the client died without closing the connection properly. See Section B.3.2.9, “Communication Errors and Aborted Connections”.
The number of failed attempts to connect to the MySQL server. See Section B.3.2.9, “Communication Errors and Aborted Connections”.
For additional connection-related information, check the
Connection_errors_status variables and thexxxhost_cachetable.Authentication_ldap_sasl_supported_methodsThe
authentication_ldap_saslplugin that implements SASL LDAP authentication supports multiple authentication methods, but depending on host system configuration, they might not all be available. TheAuthentication_ldap_sasl_supported_methodsvariable provides discoverability for the supported methods. Its value is a string consisting of supported method names separated by spaces. Example:"SCRAM-SHA 1 SCRAM-SHA-256 GSSAPI"This variable was added in MySQL 8.0.21.
The number of transactions that used the temporary binary log cache but that exceeded the value of
binlog_cache_sizeand used a temporary file to store statements from the transaction.The number of nontransactional statements that caused the binary log transaction cache to be written to disk is tracked separately in the
Binlog_stmt_cache_disk_usestatus variable.The number of cached privilege objects. Each object is the privilege combination of a user and its active roles.
The number of transactions that used the binary log cache.
The number of nontransaction statements that used the binary log statement cache but that exceeded the value of
binlog_stmt_cache_sizeand used a temporary file to store those statements.The number of nontransactional statements that used the binary log statement cache.
The number of bytes received from all clients.
The number of bytes sent to all clients.
Caching_sha2_password_rsa_public_keyThe public key used by the
caching_sha2_passwordauthentication plugin for RSA key pair-based password exchange. The value is nonempty only if the server successfully initializes the private and public keys in the files named by thecaching_sha2_password_private_key_pathandcaching_sha2_password_public_key_pathsystem variables. The value ofCaching_sha2_password_rsa_public_keycomes from the latter file.The
Com_statement counter variables indicate the number of times eachxxxxxxstatement has been executed. There is one status variable for each type of statement. For example,Com_deleteandCom_updatecountDELETEandUPDATEstatements, respectively.Com_delete_multiandCom_update_multiare similar but apply toDELETEandUPDATEstatements that use multiple-table syntax.All
Com_stmt_variables are increased even if a prepared statement argument is unknown or an error occurred during execution. In other words, their values correspond to the number of requests issued, not to the number of requests successfully completed. For example, because status variables are initialized for each server startup and do not persist across restarts, thexxxCom_restartandCom_shutdownvariables that trackRESTARTandSHUTDOWNstatements normally have a value of zero, but can be nonzero ifRESTARTorSHUTDOWNstatements were executed but failed.The
Com_stmt_status variables are as follows:xxxCom_stmt_prepareCom_stmt_executeCom_stmt_fetchCom_stmt_send_long_dataCom_stmt_resetCom_stmt_close
Those variables stand for prepared statement commands. Their names refer to the
COM_command set used in the network layer. In other words, their values increase whenever prepared statement API calls such as mysql_stmt_prepare(), mysql_stmt_execute(), and so forth are executed. However,xxxCom_stmt_prepare,Com_stmt_executeandCom_stmt_closealso increase forPREPARE,EXECUTE, orDEALLOCATE PREPARE, respectively. Additionally, the values of the older statement counter variablesCom_prepare_sql,Com_execute_sql, andCom_dealloc_sqlincrease for thePREPARE,EXECUTE, andDEALLOCATE PREPAREstatements.Com_stmt_fetchstands for the total number of network round-trips issued when fetching from cursors.Com_stmt_reprepareindicates the number of times statements were automatically reprepared by the server, for example, after metadata changes to tables or views referred to by the statement. A reprepare operation incrementsCom_stmt_reprepare, and alsoCom_stmt_prepare.Com_explain_otherindicates the number ofEXPLAIN FOR CONNECTIONstatements executed. See Section 8.8.4, “Obtaining Execution Plan Information for a Named Connection”.Com_change_repl_filterindicates the number ofCHANGE REPLICATION FILTERstatements executed.Whether the client connection uses compression in the client/server protocol.
As of MySQL 8.0.18, this status variable is deprecated; expect it to be removed in a future version of MySQL. See Configuring Legacy Connection Compression.
The name of the compression algorithm in use for the current connection to the server. The value can be any algorithm permitted in the value of the
protocol_compression_algorithmssystem variable. For example, the value isuncompressedif the connection does not use compression, orzlibif the connection uses thezlibalgorithm.For more information, see Section 4.2.8, “Connection Compression Control”.
This variable was added in MySQL 8.0.18.
The compression level in use for the current connection to the server. The value is 6 for
zlibconnections (the defaultzlibalgorithm compression level), 1 to 22 forzstdconnections, and 0 foruncompressedconnections.For more information, see Section 4.2.8, “Connection Compression Control”.
This variable was added in MySQL 8.0.18.
These variables provide information about errors that occur during the client connection process. They are global only and represent error counts aggregated across connections from all hosts. These variables track errors not accounted for by the host cache (see Section 5.1.12.3, “DNS Lookups and the Host Cache”), such as errors that are not associated with TCP connections, occur very early in the connection process (even before an IP address is known), or are not specific to any particular IP address (such as out-of-memory conditions).
The number of errors that occurred during calls to
accept()on the listening port.The number of connections refused due to internal errors in the server, such as failure to start a new thread or an out-of-memory condition.
Connection_errors_max_connectionsThe number of connections refused because the server
max_connectionslimit was reached.Connection_errors_peer_addressThe number of errors that occurred while searching for connecting client IP addresses.
The number of errors that occurred during calls to
select()orpoll()on the listening port. (Failure of this operation does not necessarily means a client connection was rejected.)The number of connections refused by the
libwraplibrary.
The number of connection attempts (successful or not) to the MySQL server.
The number of internal on-disk temporary tables created by the server while executing statements.
You can compare the number of internal on-disk temporary tables created to the total number of internal temporary tables created by comparing
Created_tmp_disk_tablesandCreated_tmp_tablesvalues.NoteDue to a known limitation,
Created_tmp_disk_tablesdoes not count on-disk temporary tables created in memory-mapped files. By default, the TempTable storage engine overflow mechanism creates internal temporary tables in memory-mapped files. This behavior is controlled by thetemptable_use_mmapvariable, which is enabled by default.See also Section 8.4.4, “Internal Temporary Table Use in MySQL”.
How many temporary files mysqld has created.
The number of internal temporary tables created by the server while executing statements.
You can compare the number of internal on-disk temporary tables created to the total number of internal temporary tables created by comparing
Created_tmp_disk_tablesandCreated_tmp_tablesvalues.See also Section 8.4.4, “Internal Temporary Table Use in MySQL”.
Each invocation of the
SHOW STATUSstatement uses an internal temporary table and increments the globalCreated_tmp_tablesvalue.The active
ssl_cavalue in the SSL context that the server uses for new connections. This context value may differ from the currentssl_casystem variable value if the system variable has been changed butALTER INSTANCE RELOAD TLShas not subsequently been executed to reconfigure the SSL context from the context-related system variable values and update the corresponding status variables. (This potential difference in values applies to each corresponding pair of context-related system and status variables. See Server-Side Runtime Configuration and Monitoring for Encrypted Connections.)This variable was added in MySQL 8.0.16.
As of MySQL 8.0.21, the
Current_tls_status variable values are also available through the Performance Schemaxxxtls_channel_statustable. See Section 27.12.19.8, “The tls_channel_status Table”.The active
ssl_capathvalue in the TSL context that the server uses for new connections. For notes about the relationship between this status variable and its corresponding system variable, see the description ofCurrent_tls_ca.This variable was added in MySQL 8.0.16.
The active
ssl_certvalue in the TSL context that the server uses for new connections. For notes about the relationship between this status variable and its corresponding system variable, see the description ofCurrent_tls_ca.This variable was added in MySQL 8.0.16.
The active
ssl_ciphervalue in the TSL context that the server uses for new connections. For notes about the relationship between this status variable and its corresponding system variable, see the description ofCurrent_tls_ca.This variable was added in MySQL 8.0.16.
The active
tls_ciphersuitesvalue in the TSL context that the server uses for new connections. For notes about the relationship between this status variable and its corresponding system variable, see the description ofCurrent_tls_ca.This variable was added in MySQL 8.0.16.
The active
ssl_crlvalue in the TSL context that the server uses for new connections. For notes about the relationship between this status variable and its corresponding system variable, see the description ofCurrent_tls_ca.This variable was added in MySQL 8.0.16.
The active
ssl_crlpathvalue in the TSL context that the server uses for new connections. For notes about the relationship between this status variable and its corresponding system variable, see the description ofCurrent_tls_ca.This variable was added in MySQL 8.0.16.
The active
ssl_keyvalue in the TSL context that the server uses for new connections. For notes about the relationship between this status variable and its corresponding system variable, see the description ofCurrent_tls_ca.This variable was added in MySQL 8.0.16.
The active
tls_versionvalue in the TSL context that the server uses for new connections. For notes about the relationship between this status variable and its corresponding system variable, see the description ofCurrent_tls_ca.This variable was added in MySQL 8.0.16.
This status variable is deprecated (because
DELAYEDinserts are not supported); expect it to be removed in a future release.This status variable is deprecated (because
DELAYEDinserts are not supported); expect it to be removed in a future release.This status variable is deprecated (because
DELAYEDinserts are not supported); expect it to be removed in a future release.The result of the most recent assignment to the
dragnet.log_error_filter_rulessystem variable, empty if no such assignment has occurred.This variable was added in MySQL 8.0.12.
The number of bytes currently used in the Performance Schema
error_logtable. It is possible for the value to decrease, for example, if a new event cannot fit until discarding an old event, but the new event is smaller than the old one.This variable was added in MySQL 8.0.22.
The number of events currently present in the Performance Schema
error_logtable. As withError_log_buffered_bytes, it is possible for the value to decrease.This variable was added in MySQL 8.0.22.
The number of events discarded from the Performance Schema
error_logtable to make room for new events.This variable was added in MySQL 8.0.22.
The time of the last write to the Performance Schema
error_logtable.This variable was added in MySQL 8.0.22.
The number of times the server flushes tables, whether because a user executed a
FLUSH TABLESstatement or due to internal server operation. It is also incremented by receipt of aCOM_REFRESHpacket. This is in contrast toCom_flush, which indicates how manyFLUSHstatements have been executed, whetherFLUSH TABLES,FLUSH LOGS, and so forth.group_replication_primary_memberShows the primary member's UUID when the group is operating in single-primary mode. If the group is operating in multi-primary mode, shows an empty string.
The
group_replication_primary_memberstatus variable is deprecated and is scheduled to be removed in a future version.The number of internal
COMMITstatements.The number of times that rows have been deleted from tables.
The server increments this variable for each call to its
external_lock()function, which generally occurs at the beginning and end of access to a table instance. There might be differences among storage engines. This variable can be used, for example, to discover for a statement that accesses a partitioned table how many partitions were pruned before locking occurred: Check how much the counter increased for the statement, subtract 2 (2 calls for the table itself), then divide by 2 to get the number of partitions locked.The number of times the server uses a storage engine's own Multi-Range Read implementation for table access.
A counter for the prepare phase of two-phase commit operations.
The number of times the first entry in an index was read. If this value is high, it suggests that the server is doing a lot of full index scans (for example,
SELECT col1 FROM foo, assuming thatcol1is indexed).The number of requests to read a row based on a key. If this value is high, it is a good indication that your tables are properly indexed for your queries.
The number of requests to read the last key in an index. With
ORDER BY, the server issues a first-key request followed by several next-key requests, whereas withORDER BY DESC, the server issues a last-key request followed by several previous-key requests.The number of requests to read the next row in key order. This value is incremented if you are querying an index column with a range constraint or if you are doing an index scan.
The number of requests to read the previous row in key order. This read method is mainly used to optimize
ORDER BY ... DESC.The number of requests to read a row based on a fixed position. This value is high if you are doing a lot of queries that require sorting of the result. You probably have a lot of queries that require MySQL to scan entire tables or you have joins that do not use keys properly.
The number of requests to read the next row in the data file. This value is high if you are doing a lot of table scans. Generally this suggests that your tables are not properly indexed or that your queries are not written to take advantage of the indexes you have.
The number of requests for a storage engine to perform a rollback operation.
The number of requests for a storage engine to place a savepoint.
The number of requests for a storage engine to roll back to a savepoint.
The number of requests to update a row in a table.
The number of requests to insert a row in a table.
Innodb_buffer_pool_dump_statusThe progress of an operation to record the pages held in the
InnoDBbuffer pool, triggered by the setting ofinnodb_buffer_pool_dump_at_shutdownorinnodb_buffer_pool_dump_now.For related information and examples, see Section 15.8.3.6, “Saving and Restoring the Buffer Pool State”.
Innodb_buffer_pool_load_statusThe progress of an operation to warm up the
InnoDBbuffer pool by reading in a set of pages corresponding to an earlier point in time, triggered by the setting ofinnodb_buffer_pool_load_at_startuporinnodb_buffer_pool_load_now. If the operation introduces too much overhead, you can cancel it by settinginnodb_buffer_pool_load_abort.For related information and examples, see Section 15.8.3.6, “Saving and Restoring the Buffer Pool State”.
The total number of bytes in the
InnoDBbuffer pool containing data. The number includes both dirty and clean pages. For more accurate memory usage calculations than withInnodb_buffer_pool_pages_data, when compressed tables cause the buffer pool to hold pages of different sizes.The number of pages in the
InnoDBbuffer pool containing data. The number includes both dirty and clean pages. When using compressed tables, the reportedInnodb_buffer_pool_pages_datavalue may be larger thanInnodb_buffer_pool_pages_total(Bug #59550).Innodb_buffer_pool_bytes_dirtyThe total current number of bytes held in dirty pages in the
InnoDBbuffer pool. For more accurate memory usage calculations than withInnodb_buffer_pool_pages_dirty, when compressed tables cause the buffer pool to hold pages of different sizes.Innodb_buffer_pool_pages_dirtyThe current number of dirty pages in the
InnoDBbuffer pool.Innodb_buffer_pool_pages_flushedThe number of requests to flush pages from the
InnoDBbuffer pool.The number of free pages in the
InnoDBbuffer pool.Innodb_buffer_pool_pages_latchedThe number of latched pages in the
InnoDBbuffer pool. These are pages currently being read or written, or that cannot be flushed or removed for some other reason. Calculation of this variable is expensive, so it is available only when theUNIV_DEBUGsystem is defined at server build time.The number of pages in the
InnoDBbuffer pool that are busy because they have been allocated for administrative overhead, such as row locks or the adaptive hash index. This value can also be calculated asInnodb_buffer_pool_pages_total−Innodb_buffer_pool_pages_free−Innodb_buffer_pool_pages_data. When using compressed tables,Innodb_buffer_pool_pages_miscmay report an out-of-bounds value (Bug #59550).Innodb_buffer_pool_pages_totalThe total size of the
InnoDBbuffer pool, in pages. When using compressed tables, the reportedInnodb_buffer_pool_pages_datavalue may be larger thanInnodb_buffer_pool_pages_total(Bug #59550)The number of pages read into the
InnoDBbuffer pool by the read-ahead background thread.Innodb_buffer_pool_read_ahead_evictedThe number of pages read into the
InnoDBbuffer pool by the read-ahead background thread that were subsequently evicted without having been accessed by queries.Innodb_buffer_pool_read_ahead_rndThe number of “random” read-aheads initiated by
InnoDB. This happens when a query scans a large portion of a table but in random order.Innodb_buffer_pool_read_requestsThe number of logical read requests.
The number of logical reads that
InnoDBcould not satisfy from the buffer pool, and had to read directly from disk.Innodb_buffer_pool_resize_statusThe status of an operation to resize the
InnoDBbuffer pool dynamically, triggered by setting theinnodb_buffer_pool_sizeparameter dynamically. Theinnodb_buffer_pool_sizeparameter is dynamic, which allows you to resize the buffer pool without restarting the server. See Configuring InnoDB Buffer Pool Size Online for related information.Normally, writes to the
InnoDBbuffer pool happen in the background. WhenInnoDBneeds to read or create a page and no clean pages are available,InnoDBflushes some dirty pages first and waits for that operation to finish. This counter counts instances of these waits. Ifinnodb_buffer_pool_sizehas been set properly, this value should be small.Innodb_buffer_pool_write_requestsThe number of writes done to the
InnoDBbuffer pool.The number of
fsync()operations so far. The frequency offsync()calls is influenced by the setting of theinnodb_flush_methodconfiguration option.The current number of pending
fsync()operations. The frequency offsync()calls is influenced by the setting of theinnodb_flush_methodconfiguration option.The current number of pending reads.
The current number of pending writes.
The amount of data read since the server was started (in bytes).
The total number of data reads (OS file reads).
The total number of data writes.
The amount of data written so far, in bytes.
The number of pages that have been written to the doublewrite buffer. See Section 15.11.1, “InnoDB Disk I/O”.
The number of doublewrite operations that have been performed. See Section 15.11.1, “InnoDB Disk I/O”.
Indicates whether the server was built with atomic instructions.
The number of times that the log buffer was too small and a wait was required for it to be flushed before continuing.
The number of write requests for the
InnoDBredo log.The number of physical writes to the
InnoDBredo log file.The number of files
InnoDBcurrently holds open.The number of
fsync()writes done to theInnoDBredo log files.The number of pending
fsync()operations for theInnoDBredo log files.The number of pending writes to the
InnoDBredo log files.The number of bytes written to the
InnoDBredo log files.InnoDBpage size (default 16KB). Many values are counted in pages; the page size enables them to be easily converted to bytes.The number of pages created by operations on
InnoDBtables.The number of pages read from the
InnoDBbuffer pool by operations onInnoDBtables.The number of pages written by operations on
InnoDBtables.Whether redo logging is enabled or disabled. Introduced in MySQL 8.0.21.
The number of row locks currently being waited for by operations on
InnoDBtables.The total time spent in acquiring row locks for
InnoDBtables, in milliseconds.The average time to acquire a row lock for
InnoDBtables, in milliseconds.The maximum time to acquire a row lock for
InnoDBtables, in milliseconds.The number of times operations on
InnoDBtables had to wait for a row lock.The number of rows deleted from
InnoDBtables.The number of rows inserted into
InnoDBtables.The number of rows read from
InnoDBtables.The number of rows updated in
InnoDBtables.The number of rows deleted from
InnoDBtables belonging to system-created schemas.The number of rows inserted into
InnoDBtables belonging to system-created schemas.The number of rows read from
InnoDBtables belonging to system-created schemas.Innodb_truncated_status_writesThe number of times output from the
SHOW ENGINE INNODB STATUSstatement has been truncated.Innodb_undo_tablespaces_activeThe number of active undo tablespaces. Includes both implicit (
InnoDB-created) and explicit (user-created) undo tablespaces. For information about undo tablespaces, see Section 15.6.3.4, “Undo Tablespaces”.Innodb_undo_tablespaces_explicitThe number of user-created undo tablespaces. For information about undo tablespaces, see Section 15.6.3.4, “Undo Tablespaces”.
Innodb_undo_tablespaces_implicitThe number of undo tablespaces created by
InnoDB. Two default undo tablespaces are created byInnoDBwhen the MySQL instance is initialized. For information about undo tablespaces, see Section 15.6.3.4, “Undo Tablespaces”.The total number of undo tablespaces. Includes both implicit (
InnoDB-created) and explicit (user-created) undo tablespaces, active and inactive. For information about undo tablespaces, see Section 15.6.3.4, “Undo Tablespaces”.The number of key blocks in the
MyISAMkey cache that have changed but have not yet been flushed to disk.The number of unused blocks in the
MyISAMkey cache. You can use this value to determine how much of the key cache is in use; see the discussion ofkey_buffer_sizein Section 5.1.8, “Server System Variables”.The number of used blocks in the
MyISAMkey cache. This value is a high-water mark that indicates the maximum number of blocks that have ever been in use at one time.The number of requests to read a key block from the
MyISAMkey cache.The number of physical reads of a key block from disk into the
MyISAMkey cache. IfKey_readsis large, then yourkey_buffer_sizevalue is probably too small. The cache miss rate can be calculated asKey_reads/Key_read_requests.The number of requests to write a key block to the
MyISAMkey cache.The number of physical writes of a key block from the
MyISAMkey cache to disk.The total cost of the last compiled query as computed by the query optimizer. This is useful for comparing the cost of different query plans for the same query. The default value of 0 means that no query has been compiled yet. The default value is 0.
Last_query_costhas session scope.In MySQL 8.0.16 and later, this variable shows the cost of queries that have multiple query blocks, summing the cost estimates of each query block, estimating how many times non-cacheable subqueries are executed, and multiplying the cost of those query blocks by the number of subquery executions. (Bug #92766, Bug #28786951) Prior to MySQL 8.0.16,
Last_query_costwas computed accurately only for simple, “flat” queries, but not for complex queries such as those containing subqueries orUNION. (For the latter, the value was set to 0.)The number of iterations the query optimizer made in execution plan construction for the previous query.
Last_query_costhas session scope.The number of attempts to connect to locked user accounts. For information about account locking and unlocking, see Section 6.2.19, “Account Locking”.
The number of
SELECTstatements for which the execution timeout was exceeded.The number of
SELECTstatements for which a nonzero execution timeout was set. This includes statements that include a nonzeroMAX_EXECUTION_TIMEoptimizer hint, and statements that include no such hint but execute while the timeout indicated by themax_execution_timesystem variable is nonzero.The number of
SELECTstatements for which the attempt to set an execution timeout failed.The maximum number of connections that have been in use simultaneously since the server started.
The time at which
Max_used_connectionsreached its current value.This status variable is deprecated (because
DELAYEDinserts are not supported); expect it to be removed in a future release.The character set currently used by the MeCab full-text parser plugin. For related information, see Section 12.10.9, “MeCab Full-Text Parser Plugin”.
Ongoing_anonymous_transaction_countShows the number of ongoing transactions which have been marked as anonymous. This can be used to ensure that no further transactions are waiting to be processed.
Ongoing_anonymous_gtid_violating_transaction_countThis status variable is only available in debug builds. Shows the number of ongoing transactions which use
gtid_next=ANONYMOUSand that violate GTID consistency.Ongoing_automatic_gtid_violating_transaction_countThis status variable is only available in debug builds. Shows the number of ongoing transactions which use
gtid_next=AUTOMATICand that violate GTID consistency.The number of files that are open. This count includes regular files opened by the server. It does not include other types of files such as sockets or pipes. Also, the count does not include files that storage engines open using their own internal functions rather than asking the server level to do so.
The number of streams that are open (used mainly for logging).
The number of cached table definitions.
The number of tables that are open.
The number of files that have been opened with
my_open()(amysyslibrary function). Parts of the server that open files without using this function do not increment the count.The number of table definitions that have been cached.
The number of tables that have been opened. If
Opened_tablesis big, yourtable_open_cachevalue is probably too small.Performance_schema_xxxPerformance Schema status variables are listed in Section 27.16, “Performance Schema Status Variables”. These variables provide information about instrumentation that could not be loaded or created due to memory constraints.
The current number of prepared statements. (The maximum number of statements is given by the
max_prepared_stmt_countsystem variable.)The number of statements executed by the server. This variable includes statements executed within stored programs, unlike the
Questionsvariable. It does not countCOM_PINGorCOM_STATISTICScommands.The discussion at the beginning of this section indicates how to relate this statement-counting status variable to other such variables.
The number of statements executed by the server. This includes only statements sent to the server by clients and not statements executed within stored programs, unlike the
Queriesvariable. This variable does not countCOM_PING,COM_STATISTICS,COM_STMT_PREPARE,COM_STMT_CLOSE, orCOM_STMT_RESETcommands.The discussion at the beginning of this section indicates how to relate this statement-counting status variable to other such variables.
The number of semisynchronous replicas.
This variable is available only if the source-side semisynchronous replication plugin is installed.
Rpl_semi_sync_master_net_avg_wait_timeThe average time in microseconds the source waited for a replica reply. This variable is always
0, and is deprecated; expect it to be removed in a future version.This variable is available only if the source-side semisynchronous replication plugin is installed.
Rpl_semi_sync_master_net_wait_timeThe total time in microseconds the source waited for replica replies. This variable is always
0, and is deprecated; expect it to be removed in a future version.This variable is available only if the source-side semisynchronous replication plugin is installed.
Rpl_semi_sync_master_net_waitsThe total number of times the source waited for replica replies.
This variable is available only if the source-side semisynchronous replication plugin is installed.
The number of times the source turned off semisynchronous replication.
This variable is available only if the source-side semisynchronous replication plugin is installed.
The number of commits that were not acknowledged successfully by a replica.
This variable is available only if the source-side semisynchronous replication plugin is installed.
Whether semisynchronous replication currently is operational on the source. The value is
ONif the plugin has been enabled and a commit acknowledgment has occurred. It isOFFif the plugin is not enabled or the source has fallen back to asynchronous replication due to commit acknowledgment timeout.This variable is available only if the source-side semisynchronous replication plugin is installed.
Rpl_semi_sync_master_timefunc_failuresThe number of times the source failed when calling time functions such as
gettimeofday().This variable is available only if the source-side semisynchronous replication plugin is installed.
Rpl_semi_sync_master_tx_avg_wait_timeThe average time in microseconds the source waited for each transaction.
This variable is available only if the source-side semisynchronous replication plugin is installed.
Rpl_semi_sync_master_tx_wait_timeThe total time in microseconds the source waited for transactions.
This variable is available only if the source-side semisynchronous replication plugin is installed.
The total number of times the source waited for transactions.
This variable is available only if the source-side semisynchronous replication plugin is installed.
Rpl_semi_sync_master_wait_pos_backtraverseThe total number of times the source waited for an event with binary coordinates lower than events waited for previously. This can occur when the order in which transactions start waiting for a reply is different from the order in which their binary log events are written.
This variable is available only if the source-side semisynchronous replication plugin is installed.
Rpl_semi_sync_master_wait_sessionsThe number of sessions currently waiting for replica replies.
This variable is available only if the source-side semisynchronous replication plugin is installed.
The number of commits that were acknowledged successfully by a replica.
This variable is available only if the source-side semisynchronous replication plugin is installed.
Whether semisynchronous replication currently is operational on the replica. This is
ONif the plugin has been enabled and the replication I/O thread is running,OFFotherwise.This variable is available only if the replica-side semisynchronous replication plugin is installed.
The value of this variable is the public key used by the
sha256_passwordauthentication plugin for RSA key pair-based password exchange. The value is nonempty only if the server successfully initializes the private and public keys in the files named by thesha256_password_private_key_pathandsha256_password_public_key_pathsystem variables. The value ofRsa_public_keycomes from the latter file.For information about
sha256_password, see Section 6.4.1.3, “SHA-256 Pluggable Authentication”.Secondary_engine_execution_countThe number of queries offloaded to a secondary engine. This variable was added in MySQL 8.0.13.
For use with HeatWave. See HeatWave User Guide.
The number of joins that perform table scans because they do not use indexes. If this value is not 0, you should carefully check the indexes of your tables.
The number of joins that used a range search on a reference table.
The number of joins that used ranges on the first table. This is normally not a critical issue even if the value is quite large.
The number of joins without keys that check for key usage after each row. If this is not 0, you should carefully check the indexes of your tables.
The number of joins that did a full scan of the first table.
The number of temporary tables that the replication SQL thread currently has open. If the value is greater than zero, it is not safe to shut down the replica; see Section 17.5.1.31, “Replication and Temporary Tables”. This variable reports the total count of open temporary tables for all replication channels.
Slave_rows_last_search_algorithm_usedThe search algorithm that was most recently used by this replica to locate rows for row-based replication. The result shows whether the replica used indexes, a table scan, or hashing as the search algorithm for the last transaction executed on any channel.
The method used depends on the setting for the
slave_rows_search_algorithmssystem variable, and the keys that are available on the relevant table.This variable is available only for debug builds of MySQL.
The number of threads that have taken more than
slow_launch_timeseconds to create.The number of queries that have taken more than
long_query_timeseconds. This counter increments regardless of whether the slow query log is enabled. For information about that log, see Section 5.4.5, “The Slow Query Log”.The number of merge passes that the sort algorithm has had to do. If this value is large, you should consider increasing the value of the
sort_buffer_sizesystem variable.The number of sorts that were done using ranges.
The number of sorted rows.
The number of sorts that were done by scanning the table.
The number of negotiates needed to establish the connection.
The number of accepted SSL connections.
The number of callback cache hits.
The current encryption cipher (empty for unencrypted connections).
The list of possible SSL ciphers (empty for non-SSL connections). If MySQL supports TLSv1.3, the value includes the possible TLSv1.3 ciphersuites. See Section 6.3.2, “Encrypted Connection TLS Protocols and Ciphers”.
The number of SSL connection attempts to an SSL-enabled replication source server.
The number of negotiates needed to establish the connection to an SSL-enabled replication source server.
The SSL context verification depth (how many certificates in the chain are tested).
The SSL context verification mode.
The default SSL timeout.
The number of successful SSL connections to the server.
The number of successful replica connections to an SSL-enabled replication source server.
The last date for which the SSL certificate is valid. To check SSL certificate expiration information, use this statement:
mysql>
SHOW STATUS LIKE 'Ssl_server_not%';+-----------------------+--------------------------+ | Variable_name | Value | +-----------------------+--------------------------+ | Ssl_server_not_after | Apr 28 14:16:39 2025 GMT | | Ssl_server_not_before | May 1 14:16:39 2015 GMT | +-----------------------+--------------------------+The first date for which the SSL certificate is valid.
The number of SSL session cache hits.
The number of SSL session cache misses.
The SSL session cache mode.
The number of SSL session cache overflows.
The SSL session cache size.
The number of SSL session cache timeouts.
How many SSL connections were reused from the cache.
Ssl_used_session_cache_entriesHow many SSL session cache entries were used.
The verification depth for replication SSL connections.
The verification mode used by the server for a connection that uses SSL. The value is a bitmask; bits are defined in the
openssl/ssl.hheader file:# define SSL_VERIFY_NONE 0x00 # define SSL_VERIFY_PEER 0x01 # define SSL_VERIFY_FAIL_IF_NO_PEER_CERT 0x02 # define SSL_VERIFY_CLIENT_ONCE 0x04
SSL_VERIFY_PEERindicates that the server asks for a client certificate. If the client supplies one, the server performs verification and proceeds only if verification is successful.SSL_VERIFY_CLIENT_ONCEindicates that a request for the client certificate is performed only in the initial handshake.The SSL protocol version of the connection (for example, TLSv1). If the connection is not encrypted, the value is empty.
The number of times that a request for a table lock could be granted immediately.
The number of times that a request for a table lock could not be granted immediately and a wait was needed. If this is high and you have performance problems, you should first optimize your queries, and then either split your table or tables or use replication.
The number of hits for open tables cache lookups.
The number of misses for open tables cache lookups.
The number of overflows for the open tables cache. This is the number of times, after a table is opened or closed, a cache instance has an unused entry and the size of the instance is larger than
table_open_cache/table_open_cache_instances.For the memory-mapped implementation of the log that is used by mysqld when it acts as the transaction coordinator for recovery of internal XA transactions, this variable indicates the largest number of pages used for the log since the server started. If the product of
Tc_log_max_pages_usedandTc_log_page_sizeis always significantly less than the log size, the size is larger than necessary and can be reduced. (The size is set by the--log-tc-sizeoption. This variable is unused: It is unneeded for binary log-based recovery, and the memory-mapped recovery log method is not used unless the number of storage engines that are capable of two-phase commit and that support XA transactions is greater than one. (InnoDBis the only applicable engine.)The page size used for the memory-mapped implementation of the XA recovery log. The default value is determined using
getpagesize(). This variable is unused for the same reasons as described forTc_log_max_pages_used.For the memory-mapped implementation of the recovery log, this variable increments each time the server was not able to commit a transaction and had to wait for a free page in the log. If this value is large, you might want to increase the log size (with the
--log-tc-sizeoption). For binary log-based recovery, this variable increments each time the binary log cannot be closed because there are two-phase commits in progress. (The close operation waits until all such transactions are finished.)The number of threads in the thread cache.
The number of currently open connections.
The number of threads created to handle connections. If
Threads_createdis big, you may want to increase thethread_cache_sizevalue. The cache miss rate can be calculated asThreads_created/Connections.The number of threads that are not sleeping.
The number of seconds that the server has been up.
The number of seconds since the most recent
FLUSH STATUSstatement.
The MySQL server can operate in different SQL modes, and can apply
these modes differently for different clients, depending on the
value of the sql_mode system
variable. DBAs can set the global SQL mode to match site server
operating requirements, and each application can set its session
SQL mode to its own requirements.
Modes affect the SQL syntax MySQL supports and the data validation checks it performs. This makes it easier to use MySQL in different environments and to use MySQL together with other database servers.
For answers to questions often asked about server SQL modes in MySQL, see Section A.3, “MySQL 8.0 FAQ: Server SQL Mode”.
When working with InnoDB tables, consider also
the innodb_strict_mode system
variable. It enables additional error checks for
InnoDB tables.
The default SQL mode in MySQL 8.0 includes these
modes: ONLY_FULL_GROUP_BY,
STRICT_TRANS_TABLES,
NO_ZERO_IN_DATE,
NO_ZERO_DATE,
ERROR_FOR_DIVISION_BY_ZERO,
and NO_ENGINE_SUBSTITUTION.
To set the SQL mode at server startup, use the
--sql-mode="
option on the command line, or
modes"sql-mode="
in an option file such as modes"my.cnf (Unix
operating systems) or my.ini (Windows).
modes is a list of different modes
separated by commas. To clear the SQL mode explicitly, set it to
an empty string using
--sql-mode="" on the command
line, or sql-mode="" in an option
file.
MySQL installation programs may configure the SQL mode during the installation process.
If the SQL mode differs from the default or from what you expect, check for a setting in an option file that the server reads at startup.
To change the SQL mode at runtime, set the global or session
sql_mode system variable using
a SET
statement:
SET GLOBAL sql_mode = 'modes'; SET SESSION sql_mode = 'modes';
Setting the GLOBAL variable requires the
SYSTEM_VARIABLES_ADMIN privilege
(or the deprecated SUPER
privilege) and affects the operation of all clients that connect
from that time on. Setting the SESSION
variable affects only the current client. Each client can change
its session sql_mode value at
any time.
To determine the current global or session
sql_mode setting, select its
value:
SELECT @@GLOBAL.sql_mode; SELECT @@SESSION.sql_mode;
SQL mode and user-defined partitioning. Changing the server SQL mode after creating and inserting data into partitioned tables can cause major changes in the behavior of such tables, and could lead to loss or corruption of data. It is strongly recommended that you never change the SQL mode once you have created tables employing user-defined partitioning.
When replicating partitioned tables, differing SQL modes on the source and replica can also lead to problems. For best results, you should always use the same server SQL mode on the source and replica.
For more information, see Section 24.6, “Restrictions and Limitations on Partitioning”.
The most important sql_mode
values are probably these:
This mode changes syntax and behavior to conform more closely to standard SQL. It is one of the special combination modes listed at the end of this section.
If a value could not be inserted as given into a transactional table, abort the statement. For a nontransactional table, abort the statement if the value occurs in a single-row statement or the first row of a multiple-row statement. More details are given later in this section.
Make MySQL behave like a “traditional” SQL database system. A simple description of this mode is “give an error instead of a warning” when inserting an incorrect value into a column. It is one of the special combination modes listed at the end of this section.
NoteWith
TRADITIONALmode enabled, anINSERTorUPDATEaborts as soon as an error occurs. If you are using a nontransactional storage engine, this may not be what you want because data changes made prior to the error may not be rolled back, resulting in a “partially done” update.
When this manual refers to “strict mode,” it means
a mode with either or both
STRICT_TRANS_TABLES or
STRICT_ALL_TABLES enabled.
The following list describes all supported SQL modes:
Do not perform full checking of dates. Check only that the month is in the range from 1 to 12 and the day is in the range from 1 to 31. This may be useful for Web applications that obtain year, month, and day in three different fields and store exactly what the user inserted, without date validation. This mode applies to
DATEandDATETIMEcolumns. It does not applyTIMESTAMPcolumns, which always require a valid date.With
ALLOW_INVALID_DATESdisabled, the server requires that month and day values be legal, and not merely in the range 1 to 12 and 1 to 31, respectively. With strict mode disabled, invalid dates such as'2004-04-31'are converted to'0000-00-00'and a warning is generated. With strict mode enabled, invalid dates generate an error. To permit such dates, enableALLOW_INVALID_DATES.Treat
"as an identifier quote character (like the`quote character) and not as a string quote character. You can still use`to quote identifiers with this mode enabled. WithANSI_QUOTESenabled, you cannot use double quotation marks to quote literal strings because they are interpreted as identifiers.The
ERROR_FOR_DIVISION_BY_ZEROmode affects handling of division by zero, which includesMOD(. For data-change operations (N,0)INSERT,UPDATE), its effect also depends on whether strict SQL mode is enabled.If this mode is not enabled, division by zero inserts
NULLand produces no warning.If this mode is enabled, division by zero inserts
NULLand produces a warning.If this mode and strict mode are enabled, division by zero produces an error, unless
IGNOREis given as well. ForINSERT IGNOREandUPDATE IGNORE, division by zero insertsNULLand produces a warning.
For
SELECT, division by zero returnsNULL. EnablingERROR_FOR_DIVISION_BY_ZEROcauses a warning to be produced as well, regardless of whether strict mode is enabled.ERROR_FOR_DIVISION_BY_ZEROis deprecated.ERROR_FOR_DIVISION_BY_ZEROis not part of strict mode, but should be used in conjunction with strict mode and is enabled by default. A warning occurs ifERROR_FOR_DIVISION_BY_ZEROis enabled without also enabling strict mode or vice versa.Because
ERROR_FOR_DIVISION_BY_ZEROis deprecated, you should expect it to be removed in a future MySQL release as a separate mode name and its effect included in the effects of strict SQL mode.The precedence of the
NOToperator is such that expressions such asNOT a BETWEEN b AND care parsed asNOT (a BETWEEN b AND c). In some older versions of MySQL, the expression was parsed as(NOT a) BETWEEN b AND c. The old higher-precedence behavior can be obtained by enabling theHIGH_NOT_PRECEDENCESQL mode.mysql>
SET sql_mode = '';mysql>SELECT NOT 1 BETWEEN -5 AND 5;-> 0 mysql>SET sql_mode = 'HIGH_NOT_PRECEDENCE';mysql>SELECT NOT 1 BETWEEN -5 AND 5;-> 1Permit spaces between a function name and the
(character. This causes built-in function names to be treated as reserved words. As a result, identifiers that are the same as function names must be quoted as described in Section 9.2, “Schema Object Names”. For example, because there is aCOUNT()function, the use ofcountas a table name in the following statement causes an error:mysql>
CREATE TABLE count (i INT);ERROR 1064 (42000): You have an error in your SQL syntaxThe table name should be quoted:
mysql>
CREATE TABLE `count` (i INT);Query OK, 0 rows affected (0.00 sec)The
IGNORE_SPACESQL mode applies to built-in functions, not to user-defined functions or stored functions. It is always permissible to have spaces after a UDF or stored function name, regardless of whetherIGNORE_SPACEis enabled.For further discussion of
IGNORE_SPACE, see Section 9.2.5, “Function Name Parsing and Resolution”.NO_AUTO_VALUE_ON_ZEROaffects handling ofAUTO_INCREMENTcolumns. Normally, you generate the next sequence number for the column by inserting eitherNULLor0into it.NO_AUTO_VALUE_ON_ZEROsuppresses this behavior for0so that onlyNULLgenerates the next sequence number.This mode can be useful if
0has been stored in a table'sAUTO_INCREMENTcolumn. (Storing0is not a recommended practice, by the way.) For example, if you dump the table with mysqldump and then reload it, MySQL normally generates new sequence numbers when it encounters the0values, resulting in a table with contents different from the one that was dumped. EnablingNO_AUTO_VALUE_ON_ZERObefore reloading the dump file solves this problem. For this reason, mysqldump automatically includes in its output a statement that enablesNO_AUTO_VALUE_ON_ZERO.Disable the use of the backslash character (
\) as an escape character within strings and identifiers. With this mode enabled, backslash becomes an ordinary character like any other.When creating a table, ignore all
INDEX DIRECTORYandDATA DIRECTORYdirectives. This option is useful on replica servers.Control automatic substitution of the default storage engine when a statement such as
CREATE TABLEorALTER TABLEspecifies a storage engine that is disabled or not compiled in.By default,
NO_ENGINE_SUBSTITUTIONis enabled.Because storage engines can be pluggable at runtime, unavailable engines are treated the same way:
With
NO_ENGINE_SUBSTITUTIONdisabled, forCREATE TABLEthe default engine is used and a warning occurs if the desired engine is unavailable. ForALTER TABLE, a warning occurs and the table is not altered.With
NO_ENGINE_SUBSTITUTIONenabled, an error occurs and the table is not created or altered if the desired engine is unavailable.Subtraction between integer values, where one is of type
UNSIGNED, produces an unsigned result by default. If the result would otherwise have been negative, an error results:mysql>
SET sql_mode = '';Query OK, 0 rows affected (0.00 sec) mysql>SELECT CAST(0 AS UNSIGNED) - 1;ERROR 1690 (22003): BIGINT UNSIGNED value is out of range in '(cast(0 as unsigned) - 1)'If the
NO_UNSIGNED_SUBTRACTIONSQL mode is enabled, the result is negative:mysql>
SET sql_mode = 'NO_UNSIGNED_SUBTRACTION';mysql>SELECT CAST(0 AS UNSIGNED) - 1;+-------------------------+ | CAST(0 AS UNSIGNED) - 1 | +-------------------------+ | -1 | +-------------------------+If the result of such an operation is used to update an
UNSIGNEDinteger column, the result is clipped to the maximum value for the column type, or clipped to 0 ifNO_UNSIGNED_SUBTRACTIONis enabled. With strict SQL mode enabled, an error occurs and the column remains unchanged.When
NO_UNSIGNED_SUBTRACTIONis enabled, the subtraction result is signed, even if any operand is unsigned. For example, compare the type of columnc2in tablet1with that of columnc2in tablet2:mysql>
SET sql_mode='';mysql>CREATE TABLE test (c1 BIGINT UNSIGNED NOT NULL);mysql>CREATE TABLE t1 SELECT c1 - 1 AS c2 FROM test;mysql>DESCRIBE t1;+-------+---------------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------------------+------+-----+---------+-------+ | c2 | bigint(21) unsigned | NO | | 0 | | +-------+---------------------+------+-----+---------+-------+ mysql>SET sql_mode='NO_UNSIGNED_SUBTRACTION';mysql>CREATE TABLE t2 SELECT c1 - 1 AS c2 FROM test;mysql>DESCRIBE t2;+-------+------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+------------+------+-----+---------+-------+ | c2 | bigint(21) | NO | | 0 | | +-------+------------+------+-----+---------+-------+This means that
BIGINT UNSIGNEDis not 100% usable in all contexts. See Section 12.11, “Cast Functions and Operators”.The
NO_ZERO_DATEmode affects whether the server permits'0000-00-00'as a valid date. Its effect also depends on whether strict SQL mode is enabled.If this mode is not enabled,
'0000-00-00'is permitted and inserts produce no warning.If this mode is enabled,
'0000-00-00'is permitted and inserts produce a warning.If this mode and strict mode are enabled,
'0000-00-00'is not permitted and inserts produce an error, unlessIGNOREis given as well. ForINSERT IGNOREandUPDATE IGNORE,'0000-00-00'is permitted and inserts produce a warning.
NO_ZERO_DATEis deprecated.NO_ZERO_DATEis not part of strict mode, but should be used in conjunction with strict mode and is enabled by default. A warning occurs ifNO_ZERO_DATEis enabled without also enabling strict mode or vice versa.Because
NO_ZERO_DATEis deprecated, you should expect it to be removed in a future MySQL release as a separate mode name and its effect included in the effects of strict SQL mode.The
NO_ZERO_IN_DATEmode affects whether the server permits dates in which the year part is nonzero but the month or day part is 0. (This mode affects dates such as'2010-00-01'or'2010-01-00', but not'0000-00-00'. To control whether the server permits'0000-00-00', use theNO_ZERO_DATEmode.) The effect ofNO_ZERO_IN_DATEalso depends on whether strict SQL mode is enabled.If this mode is not enabled, dates with zero parts are permitted and inserts produce no warning.
If this mode is enabled, dates with zero parts are inserted as
'0000-00-00'and produce a warning.If this mode and strict mode are enabled, dates with zero parts are not permitted and inserts produce an error, unless
IGNOREis given as well. ForINSERT IGNOREandUPDATE IGNORE, dates with zero parts are inserted as'0000-00-00'and produce a warning.
NO_ZERO_IN_DATEis deprecated.NO_ZERO_IN_DATEis not part of strict mode, but should be used in conjunction with strict mode and is enabled by default. A warning occurs ifNO_ZERO_IN_DATEis enabled without also enabling strict mode or vice versa.Because
NO_ZERO_IN_DATEis deprecated, you should expect it to be removed in a future MySQL release as a separate mode name and its effect included in the effects of strict SQL mode.Reject queries for which the select list,
HAVINGcondition, orORDER BYlist refer to nonaggregated columns that are neither named in theGROUP BYclause nor are functionally dependent on (uniquely determined by)GROUP BYcolumns.A MySQL extension to standard SQL permits references in the
HAVINGclause to aliased expressions in the select list. TheHAVINGclause can refer to aliases regardless of whetherONLY_FULL_GROUP_BYis enabled.For additional discussion and examples, see Section 12.20.3, “MySQL Handling of GROUP BY”.
By default, trailing spaces are trimmed from
CHARcolumn values on retrieval. IfPAD_CHAR_TO_FULL_LENGTHis enabled, trimming does not occur and retrievedCHARvalues are padded to their full length. This mode does not apply toVARCHARcolumns, for which trailing spaces are retained on retrieval.NoteAs of MySQL 8.0.13,
PAD_CHAR_TO_FULL_LENGTHis deprecated. Expect it to be removed in a future version of MySQL.mysql>
CREATE TABLE t1 (c1 CHAR(10));Query OK, 0 rows affected (0.37 sec) mysql>INSERT INTO t1 (c1) VALUES('xy');Query OK, 1 row affected (0.01 sec) mysql>SET sql_mode = '';Query OK, 0 rows affected (0.00 sec) mysql>SELECT c1, CHAR_LENGTH(c1) FROM t1;+------+-----------------+ | c1 | CHAR_LENGTH(c1) | +------+-----------------+ | xy | 2 | +------+-----------------+ 1 row in set (0.00 sec) mysql>SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH';Query OK, 0 rows affected (0.00 sec) mysql>SELECT c1, CHAR_LENGTH(c1) FROM t1;+------------+-----------------+ | c1 | CHAR_LENGTH(c1) | +------------+-----------------+ | xy | 10 | +------------+-----------------+ 1 row in set (0.00 sec)Treat
||as a string concatenation operator (same asCONCAT()) rather than as a synonym forOR.Treat
REALas a synonym forFLOAT. By default, MySQL treatsREALas a synonym forDOUBLE.Enable strict SQL mode for all storage engines. Invalid data values are rejected. For details, see Strict SQL Mode.
Enable strict SQL mode for transactional storage engines, and when possible for nontransactional storage engines. For details, see Strict SQL Mode.
Control whether rounding or truncation occurs when inserting a
TIME,DATE, orTIMESTAMPvalue with a fractional seconds part into a column having the same type but fewer fractional digits. The default behavior is to use rounding. If this mode is enabled, truncation occurs instead. The following sequence of statements illustrates the difference:CREATE TABLE t (id INT, tval TIME(1)); SET sql_mode=''; INSERT INTO t (id, tval) VALUES(1, 1.55); SET sql_mode='TIME_TRUNCATE_FRACTIONAL'; INSERT INTO t (id, tval) VALUES(2, 1.55);
The resulting table contents look like this, where the first value has been subject to rounding and the second to truncation:
mysql>
SELECT id, tval FROM t ORDER BY id;+------+------------+ | id | tval | +------+------------+ | 1 | 00:00:01.6 | | 2 | 00:00:01.5 | +------+------------+See also Section 11.2.6, “Fractional Seconds in Time Values”.
The following special modes are provided as shorthand for combinations of mode values from the preceding list.
Equivalent to
REAL_AS_FLOAT,PIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE, andONLY_FULL_GROUP_BY.ANSImode also causes the server to return an error for queries where a set functionSwith an outer referenceS(outer_ref)SELECT * FROM t1 WHERE t1.a IN (SELECT MAX(t1.b) FROM t2 WHERE ...);
Here,
MAX(t1.b)cannot aggregated in the outer query because it appears in theWHEREclause of that query. Standard SQL requires an error in this situation. IfANSImode is not enabled, the server treatsS(outer_ref)S(const)TRADITIONALis equivalent toSTRICT_TRANS_TABLES,STRICT_ALL_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO, andNO_ENGINE_SUBSTITUTION.
Strict mode controls how MySQL handles invalid or missing values
in data-change statements such as
INSERT or
UPDATE. A value can be invalid
for several reasons. For example, it might have the wrong data
type for the column, or it might be out of range. A value is
missing when a new row to be inserted does not contain a value
for a non-NULL column that has no explicit
DEFAULT clause in its definition. (For a
NULL column, NULL is
inserted if the value is missing.) Strict mode also affects DDL
statements such as CREATE TABLE.
If strict mode is not in effect, MySQL inserts adjusted values
for invalid or missing values and produces warnings (see
Section 13.7.7.42, “SHOW WARNINGS Statement”). In strict mode, you can
produce this behavior by using
INSERT IGNORE
or UPDATE
IGNORE.
For statements such as SELECT
that do not change data, invalid values generate a warning in
strict mode, not an error.
Strict mode produces an error for attempts to create a key that exceeds the maximum key length. When strict mode is not enabled, this results in a warning and truncation of the key to the maximum key length.
Strict mode does not affect whether foreign key constraints are
checked. foreign_key_checks can
be used for that. (See
Section 5.1.8, “Server System Variables”.)
Strict SQL mode is in effect if either
STRICT_ALL_TABLES or
STRICT_TRANS_TABLES is
enabled, although the effects of these modes differ somewhat:
For transactional tables, an error occurs for invalid or missing values in a data-change statement when either
STRICT_ALL_TABLESorSTRICT_TRANS_TABLESis enabled. The statement is aborted and rolled back.For nontransactional tables, the behavior is the same for either mode if the bad value occurs in the first row to be inserted or updated: The statement is aborted and the table remains unchanged. If the statement inserts or modifies multiple rows and the bad value occurs in the second or later row, the result depends on which strict mode is enabled:
For
STRICT_ALL_TABLES, MySQL returns an error and ignores the rest of the rows. However, because the earlier rows have been inserted or updated, the result is a partial update. To avoid this, use single-row statements, which can be aborted without changing the table.For
STRICT_TRANS_TABLES, MySQL converts an invalid value to the closest valid value for the column and inserts the adjusted value. If a value is missing, MySQL inserts the implicit default value for the column data type. In either case, MySQL generates a warning rather than an error and continues processing the statement. Implicit defaults are described in Section 11.6, “Data Type Default Values”.
Strict mode affects handling of division by zero, zero dates, and zeros in dates as follows:
Strict mode affects handling of division by zero, which includes
MOD(:N,0)For data-change operations (
INSERT,UPDATE):If strict mode is not enabled, division by zero inserts
NULLand produces no warning.If strict mode is enabled, division by zero produces an error, unless
IGNOREis given as well. ForINSERT IGNOREandUPDATE IGNORE, division by zero insertsNULLand produces a warning.
For
SELECT, division by zero returnsNULL. Enabling strict mode causes a warning to be produced as well.Strict mode affects whether the server permits
'0000-00-00'as a valid date:If strict mode is not enabled,
'0000-00-00'is permitted and inserts produce no warning.If strict mode is enabled,
'0000-00-00'is not permitted and inserts produce an error, unlessIGNOREis given as well. ForINSERT IGNOREandUPDATE IGNORE,'0000-00-00'is permitted and inserts produce a warning.
Strict mode affects whether the server permits dates in which the year part is nonzero but the month or day part is 0 (dates such as
'2010-00-01'or'2010-01-00'):If strict mode is not enabled, dates with zero parts are permitted and inserts produce no warning.
If strict mode is enabled, dates with zero parts are not permitted and inserts produce an error, unless
IGNOREis given as well. ForINSERT IGNOREandUPDATE IGNORE, dates with zero parts are inserted as'0000-00-00'(which is considered valid withIGNORE) and produce a warning.
For more information about strict mode with respect to
IGNORE, see
Comparison of the IGNORE Keyword and Strict SQL Mode.
Strict mode affects handling of division by zero, zero dates,
and zeros in dates in conjunction with the
ERROR_FOR_DIVISION_BY_ZERO,
NO_ZERO_DATE, and
NO_ZERO_IN_DATE modes.
This section compares the effect on statement execution of the
IGNORE keyword (which downgrades errors to
warnings) and strict SQL mode (which upgrades warnings to
errors). It describes which statements they affect, and which
errors they apply to.
The following table presents a summary comparison of statement
behavior when the default is to produce an error versus a
warning. An example of when the default is to produce an error
is inserting a NULL into a NOT
NULL column. An example of when the default is to
produce a warning is inserting a value of the wrong data type
into a column (such as inserting the string
'abc' into an integer column).
| Operational Mode | When Statement Default is Error | When Statement Default is Warning |
|---|---|---|
Without IGNORE or strict SQL mode |
Error | Warning |
With IGNORE |
Warning | Warning (same as without IGNORE or strict SQL mode) |
| With strict SQL mode | Error (same as without IGNORE or strict SQL mode) |
Error |
With IGNORE and strict SQL mode |
Warning | Warning |
One conclusion to draw from the table is that when the
IGNORE keyword and strict SQL mode are both
in effect, IGNORE takes precedence. This
means that, although IGNORE and strict SQL
mode can be considered to have opposite effects on error
handling, they do not cancel when used together.
The Effect of IGNORE on Statement Execution
Several statements in MySQL support an optional
IGNORE keyword. This keyword causes the
server to downgrade certain types of errors and generate
warnings instead. For a multiple-row statement,
IGNORE causes the statement to skip to the
next row instead of aborting. (For nonignorable errors, an error
occurs regardless of the IGNORE keyword.)
Example: If the table t has a primary key
column i, attempting to insert the same value
of i into multiple rows normally produces a
duplicate-key error:
mysql> INSERT INTO t (i) VALUES(1),(1);
ERROR 1062 (23000): Duplicate entry '1' for key 't.PRIMARY'
With IGNORE, the row containing the duplicate
key still is not inserted, but a warning occurs instead of an
error:
mysql>INSERT IGNORE INTO t (i) VALUES(1),(1);Query OK, 1 row affected, 1 warning (0.01 sec) Records: 2 Duplicates: 1 Warnings: 1 mysql>SHOW WARNINGS;+---------+------+-----------------------------------------+ | Level | Code | Message | +---------+------+-----------------------------------------+ | Warning | 1062 | Duplicate entry '1' for key 't.PRIMARY' | +---------+------+-----------------------------------------+ 1 row in set (0.00 sec)
These statements support the IGNORE keyword:
CREATE TABLE ... SELECT:IGNOREdoes not apply to theCREATE TABLEorSELECTparts of the statement but to inserts into the table of rows produced by theSELECT. Rows that duplicate an existing row on a unique key value are discarded.DELETE:IGNOREcauses MySQL to ignore errors during the process of deleting rows.INSERT: WithIGNORE, rows that duplicate an existing row on a unique key value are discarded. Rows set to values that would cause data conversion errors are set to the closest valid values instead.For partitioned tables where no partition matching a given value is found,
IGNOREcauses the insert operation to fail silently for rows containing the unmatched value.LOAD DATA,LOAD XML: WithIGNORE, rows that duplicate an existing row on a unique key value are discarded.UPDATE: WithIGNORE, rows for which duplicate-key conflicts occur on a unique key value are not updated. Rows updated to values that would cause data conversion errors are updated to the closest valid values instead.
The IGNORE keyword applies to the following
ignorable errors:
ER_BAD_NULL_ERRORER_DUP_ENTRYER_DUP_ENTRY_WITH_KEY_NAMEER_DUP_KEYER_NO_PARTITION_FOR_GIVEN_VALUEER_NO_PARTITION_FOR_GIVEN_VALUE_SILENTER_NO_REFERENCED_ROW_2ER_ROW_DOES_NOT_MATCH_GIVEN_PARTITION_SETER_ROW_IS_REFERENCED_2ER_SUBQUERY_NO_1_ROWER_VIEW_CHECK_FAILED
The Effect of Strict SQL Mode on Statement Execution
The MySQL server can operate in different SQL modes, and can
apply these modes differently for different clients, depending
on the value of the sql_mode
system variable. In “strict” SQL mode, the server
upgrades certain warnings to errors.
For example, in non-strict SQL mode, inserting the string
'abc' into an integer column results in
conversion of the value to 0 and a warning:
mysql>SET sql_mode = '';Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO t (i) VALUES('abc');Query OK, 1 row affected, 1 warning (0.01 sec) mysql>SHOW WARNINGS;+---------+------+--------------------------------------------------------+ | Level | Code | Message | +---------+------+--------------------------------------------------------+ | Warning | 1366 | Incorrect integer value: 'abc' for column 'i' at row 1 | +---------+------+--------------------------------------------------------+ 1 row in set (0.00 sec)
In strict SQL mode, the invalid value is rejected with an error:
mysql>SET sql_mode = 'STRICT_ALL_TABLES';Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO t (i) VALUES('abc');ERROR 1366 (HY000): Incorrect integer value: 'abc' for column 'i' at row 1
For more information about possible settings of the
sql_mode system variable, see
Section 5.1.11, “Server SQL Modes”.
Strict SQL mode applies to the following statements under conditions for which some value might be out of range or an invalid row is inserted into or deleted from a table:
Within stored programs, individual statements of the types just listed execute in strict SQL mode if the program was defined while strict mode was in effect.
Strict SQL mode applies to the following errors, which represent
a class of errors in which an input value is either invalid or
missing. A value is invalid if it has the wrong data type for
the column or might be out of range. A value is missing if a new
row to be inserted does not contain a value for a NOT
NULL column that has no explicit
DEFAULT clause in its definition.
ER_BAD_NULL_ERRORER_CUT_VALUE_GROUP_CONCATER_DATA_TOO_LONGER_DATETIME_FUNCTION_OVERFLOWER_DIVISION_BY_ZEROER_INVALID_ARGUMENT_FOR_LOGARITHMER_NO_DEFAULT_FOR_FIELDER_NO_DEFAULT_FOR_VIEW_FIELDER_TOO_LONG_KEYER_TRUNCATED_WRONG_VALUEER_TRUNCATED_WRONG_VALUE_FOR_FIELDER_WARN_DATA_OUT_OF_RANGEER_WARN_NULL_TO_NOTNULLER_WARN_TOO_FEW_RECORDSER_WRONG_ARGUMENTSER_WRONG_VALUE_FOR_TYPEWARN_DATA_TRUNCATED
Because continued MySQL development defines new errors, there may be errors not in the preceding list to which strict SQL mode applies.
This section describes how MySQL Server manages connections. This includes a description of the available connection interfaces, how the server uses connection handler threads, details about the administrative connection interface, and management of DNS lookups.
This section describes aspects of how the MySQL server manages client connections.
The server is capable of listening for client connections on multiple network interfaces. Connection manager threads handle client connection requests on the network interfaces that the server listens to:
On all platforms, one manager thread handles TCP/IP connection requests.
On Unix, the same manager thread also handles Unix socket file connection requests.
On Windows, one manager thread handles shared-memory connection requests, and another handles named-pipe connection requests.
On all platforms, an additional network interface may be enabled to accept administrative TCP/IP connection requests. This interface can use the manager thread that handles “ordinary” TCP/IP requests, or a separate thread.
The server does not create threads to handle interfaces that it does not listen to. For example, a Windows server that does not have support for named-pipe connections enabled does not create a thread to handle them.
Individual server plugins or components may implement their own connection interface:
X Plugin enables MySQL Server to communicate with clients using X Protocol. See Section 20.5, “X Plugin”.
Connection manager threads associate each client connection with a thread dedicated to it that handles authentication and request processing for that connection. Manager threads create a new thread when necessary but try to avoid doing so by consulting the thread cache first to see whether it contains a thread that can be used for the connection. When a connection ends, its thread is returned to the thread cache if the cache is not full.
In this connection thread model, there are as many threads as there are clients currently connected, which has some disadvantages when server workload must scale to handle large numbers of connections. For example, thread creation and disposal becomes expensive. Also, each thread requires server and kernel resources, such as stack space. To accommodate a large number of simultaneous connections, the stack size per thread must be kept small, leading to a situation where it is either too small or the server consumes large amounts of memory. Exhaustion of other resources can occur as well, and scheduling overhead can become significant.
MySQL Enterprise Edition includes a thread pool plugin that provides an alternative thread-handling model designed to reduce overhead and improve performance. It implements a thread pool that increases server performance by efficiently managing statement execution threads for large numbers of client connections. See Section 5.6.3, “MySQL Enterprise Thread Pool”.
To control and monitor how the server manages threads that handle client connections, several system and status variables are relevant. (See Section 5.1.8, “Server System Variables”, and Section 5.1.10, “Server Status Variables”.)
The
thread_cache_sizesystem variable determines the thread cache size. By default, the server autosizes the value at startup, but it can be set explicitly to override this default. A value of 0 disables caching, which causes a thread to be set up for each new connection and disposed of when the connection terminates. To enableNinactive connection threads to be cached, setthread_cache_sizetoNat server startup or at runtime. A connection thread becomes inactive when the client connection with which it was associated terminates.To monitor the number of threads in the cache and how many threads have been created because a thread could not be taken from the cache, check the
Threads_cachedandThreads_createdstatus variables.When the thread stack is too small, this limits the complexity of the SQL statements the server can handle, the recursion depth of stored procedures, and other memory-consuming actions. To set a stack size of
Nbytes for each thread, start the server withthread_stackset toN.
To control the maximum number of clients the server permits to
connect simultaneously, set the
max_connections system
variable at server startup or at runtime. It may be necessary
to increase max_connections
if more clients attempt to connect simultaneously then the
server is configured to handle (see
Section B.3.2.5, “Too many connections”). If the server refuses
a connection because the
max_connections limit is
reached, it increments the
Connection_errors_max_connections
status variable.
mysqld actually permits
max_connections
+ 1 client connections. The extra connection is reserved for
use by accounts that have the
CONNECTION_ADMIN privilege (or
the deprecated SUPER
privilege). By granting the privilege to administrators and
not to normal users (who should not need it), an administrator
can connect to the server and use SHOW
PROCESSLIST to diagnose problems even if the maximum
number of unprivileged clients are connected. See
Section 13.7.7.29, “SHOW PROCESSLIST Statement”.
As of MySQL 8.0.14, the server also permits administrative connections on an administrative network interface, which you can set up using a dedicated IP address and port. See Section 5.1.12.2, “Administrative Connection Management”.
The Group Replication plugin interacts with MySQL Server using
internal sessions to perform SQL API operations. In releases
to MySQL 8.0.18, these sessions count towards the client
connections limit specified by the
max_connections server system
variable. In those releases, if the server has reached the
max_connections limit when
Group Replication is started or attempts to perform an
operation, the operation is unsuccessful and Group Replication
or the server itself might stop. From MySQL 8.0.19, Group
Replication's internal sessions are handled separately from
client connections, so they do not count towards the
max_connections limit and are
not refused if the server has reached this limit.
The maximum number of client connections MySQL supports (that
is, the maximum value to which
max_connections can be set)
depends on several factors:
The quality of the thread library on a given platform.
The amount of RAM available.
The amount of RAM is used for each connection.
The workload from each connection.
The desired response time.
The number of file descriptors available.
Linux or Solaris should be able to support at least 500 to 1000 simultaneous connections routinely and as many as 10,000 connections if you have many gigabytes of RAM available and the workload from each is low or the response time target undemanding.
Increasing the
max_connections value
increases the number of file descriptors that
mysqld requires. If the required number of
descriptors are not available, the server reduces the value of
max_connections. For comments
on file descriptor limits, see Section 8.4.3.1, “How MySQL Opens and Closes Tables”.
Increasing the
open_files_limit system
variable may be necessary, which may also require raising the
operating system limit on how many file descriptors can be
used by MySQL. Consult your operating system documentation to
determine whether it is possible to increase the limit and how
to do so. See also Section B.3.2.16, “File Not Found and Similar Errors”.
As mentioned in
Connection Volume Management, to
allow for the need to perform administrative operations even
when max_connections
connections are already established on the interfaces used for
ordinary connections, the MySQL server permits a single
administrative connection to users who have the
CONNECTION_ADMIN privilege (or
the deprecated SUPER privilege).
Additionally, as of MySQL 8.0.14, the server permits dedicating a TCP/IP port for administrative connections, as described in the following sections.
The administrative connection interface has these characteristics:
The server enables the interface only if the
admin_addresssystem variable is set at startup to indicate the IP address for it. Ifadmin_addressis not set, the server maintains no administrative interface.The
admin_portsystem variable specifies the interface TCP/IP port number (default 33062).There is no limit on the number of administrative connections.
Connections are permitted only for users who have the
SERVICE_CONNECTION_ADMINprivilege.The
create_admin_listener_threadsystem variable enables DBAs to choose at startup whether the administrative interface has its own separate thread. The default isOFF; that is, the manager thread for ordinary connections on the main interface also handles connections for the administrative interface.
These lines in the server my.cnf file
enable the administrative interface on the loopback interface
and configure it to use port number 33064 (that is, a port
different from the default):
[mysqld] admin_address=127.0.0.1 admin_port=33064
MySQL client programs connect to either the main or administrative interface by specifying appropriate connection parameters. If the server running on the local host is using the default TCP/IP port numbers of 3306 and 33062 for the main and administrative interfaces, these commands connect to those interfaces:
mysql --protocol=TCP --port=3306 mysql --protocol=TCP --port=33062
Prior to MySQL 8.0.21, the administrative interface supports encrypted connections using the connection-encryption configuration that applies to the main interface. As of MySQL 8.0.21, the administrative interface has its own configuration parameters for encrypted connections. These correspond to the main interface parameters but enable independent configuration of encrypted connections for the administrative interface:
The
--admin-ssloption is like the--ssloption, but it enables or disables encrypted connections for the administrative interface rather than the main interface.The
admin_tls_andxxxadmin_ssl_system variables are like thexxxtls_andxxxssl_system variables, but they configure the TLS context for the administrative interface rather than the main interface.xxx
For general information about configuring connection-encryption support, see Section 6.3.1, “Configuring MySQL to Use Encrypted Connections”. That discussion is written for the main connection interface, but the parameter names are similar for the administrative connection interface. The following remarks provide information specific to the administrative interface.
TLS configuration for the administrative interface follows these rules:
If
--admin-sslis enabled (the default), the administrative interface supports encrypted connections. For connections on the interface, the applicable TLS context depends on whether any nondefault administrative TLS parameter is configured:If all administrative TLS parameters have their default values, the administrative interface uses the same TLS context as the main interface.
If any administrative TLS parameter has a nondefault value, the administrative interface uses the TLS context defined by its own parameters. (This is the case if any
admin_tls_orxxxadmin_ssl_system variable is set to a value different from its default.) If a valid TLS context cannot be created from those parameters, the administrative interface falls back to the main interface TLS context.xxx
If
--admin-sslis disabled, encrypted connections to the administrative interface are disabled. (This is true even if administrative TLS parameters have nondefault values because disabling--admin-ssltakes precedence.)
Examples:
This configuration in the server
my.cnffile enables the administrative interface, but does not set any of the TLS parameters specific to that interface:[mysqld] admin_address=127.0.0.1
As a result, the administrative interface supports encrypted connections (because encryption is supported by default when the administrative interface is enabled), but uses the main interface TLS context. When clients connect to the administrative interface, they should use the same certificate and key files as for ordinary connections on the main interface. For example (enter the command on a single line):
mysql --protocol=TCP --port=33062 --ssl-ca=ca.pem --ssl-cert=client-cert.pem --ssl-key=client-key.pemThis server configuration enables the administrative interface and sets the TLS certificate and key file parameters specific to that interface:
[mysqld] admin_address=127.0.0.1 admin_ssl_ca=admin-ca.pem admin_ssl_cert=admin-server-cert.pem admin_ssl_key=admin-server-key.pem
As a result, the administrative interface supports encrypted connections using its own TLS context. When clients connect to the administrative interface, they should use certificate and key files specific to that interface. For example (enter the command on a single line):
mysql --protocol=TCP --port=33062 --ssl-ca=admin-ca.pem --ssl-cert=admin-client-cert.pem --ssl-key=admin-client-key.pemThis server configuration enables the administrative interface but disables encrypted connections for it:
[mysqld] admin-ssl=OFF admin_address=127.0.0.1
In this case, if the configuration were to also set administrative TLS parameters such as
admin_ssl_ca, those parameter settings would have no effect becauseadmin-ssl=OFFtakes precedence.
The MySQL server maintains an in-memory host cache that contains
information about clients: IP address, host name, and error
information. The Performance Schema
host_cache table exposes the
contents of the host cache so that it can be examined using
SELECT statements. This may help
you diagnose the causes of connection problems. See
Section 27.12.19.2, “The host_cache Table”.
The following sections discuss how the host cache works, as well as other topics such as how to configure and monitor the cache.
The server uses the host cache only for non-localhost TCP
connections. It does not use the cache for TCP connections
established using a loopback interface address (for example,
127.0.0.1 or ::1), or
for connections established using a Unix socket file, named
pipe, or shared memory.
The server uses the host cache for several purposes:
By caching the results of IP-to-host name lookups, the server avoids doing a Domain Name System (DNS) lookup for each client connection. Instead, for a given host, it needs to perform a lookup only for the first connection from that host.
The cache contains information about errors that occur during the client connection process. Some errors are considered “blocking.” If too many of these occur successively from a given host without a successful connection, the server blocks further connections from that host. The
max_connect_errorssystem variable determines the permitted number of successive errors before blocking occurs.
For each applicable new client connection, the server uses the client IP address to check whether the client host name is in the host cache. If so, the server refuses or continues to process the connection request depending on whether or not the host is blocked. If the host is not in the cache, the server attempts to resolve the host name. First, it resolves the IP address to a host name and resolves that host name back to an IP address. Then it compares the result to the original IP address to ensure that they are the same. The server stores information about the result of this operation in the host cache. If the cache is full, the least recently used entry is discarded.
The server performs host name resolution using the
gethostbyaddr() and
gethostbyname() system calls.
The server handles entries in the host cache like this:
When the first TCP client connection reaches the server from a given IP address, a new cache entry is created to record the client IP, host name, and client lookup validation flag. Initially, the host name is set to
NULLand the flag is false. This entry is also used for subsequent client TCP connections from the same originating IP.If the validation flag for the client IP entry is false, the server attempts an IP-to-host name-to-IP DNS resolution. If that is successful, the host name is updated with the resolved host name and the validation flag is set to true. If resolution is unsuccessful, the action taken depends on whether the error is permanent or transient. For permanent failures, the host name remains
NULLand the validation flag is set to true. For transient failures, the host name and validation flag remain unchanged. (In this case, another DNS resolution attempt occurs the next time a client connects from this IP.)If an error occurs while processing an incoming client connection from a given IP address, the server updates the corresponding error counters in the entry for that IP. For a description of the errors recorded, see Section 27.12.19.2, “The host_cache Table”.
To unblock blocked hosts, flush the host cache; see Dealing with Blocked Hosts.
It is possible for a blocked host to become unblocked even without flushing the host cache if activity from other hosts occurs:
If the cache is full when a connection arrives from a client IP not in the cache, the server discards the least recently used cache entry to make room for the new entry.
If the discarded entry is for a blocked host, that host becomes unblocked.
Some connection errors are not associated with TCP
connections, occur very early in the connection process (even
before an IP address is known), or are not specific to any
particular IP address (such as out-of-memory conditions). For
information about these errors, check the
Connection_errors_
status variables (see
Section 5.1.10, “Server Status Variables”).
xxx
The host cache is enabled by default. The
host_cache_size system
variable controls its size, as well as the size of the
Performance Schema host_cache
table that exposes the cache contents. The cache size can be
set at server startup and changed at runtime. For example, to
set the size to 100 at startup, put these lines in the server
my.cnf file:
[mysqld] host_cache_size=200
To change the size to 300 at runtime, do this:
SET GLOBAL host_cache_size=300;
Setting host_cache_size to 0, either at
server startup or at runtime, disables the host cache. With
the cache disabled, the server performs a DNS lookup every
time a client connects.
Changing the cache size at runtime causes an implicit host
cache flushing operation that clears the host cache, truncates
the host_cache table, and
unblocks any blocked hosts; see
Flushing the Host Cache.
Using the --skip-host-cache
option is similar to setting the
host_cache_size system
variable to 0, but
host_cache_size is more
flexible because it can also be used to resize, enable, and
disable the host cache at runtime, not just at server startup.
Starting the server with
--skip-host-cache does not
prevent runtime changes to the value of
host_cache_size, but such
changes have no effect and the cache is not re-enabled even if
host_cache_size is set larger
than 0.
To disable DNS host name lookups, start the server with the
skip_name_resolve system
variable enabled. In this case, the server uses only IP
addresses and not host names to match connecting hosts to rows
in the MySQL grant tables. Only accounts specified in those
tables using IP addresses can be used. (A client may not be
able to connect if no account exists that specifies the client
IP address.)
If you have a very slow DNS and many hosts, you might be able
to improve performance either by enabling
skip_name_resolve to disable
DNS lookups, or by increasing the value of
host_cache_size to make the
host cache larger.
To disallow TCP/IP connections entirely, start the server with
the skip_networking system
variable enabled.
To adjust the permitted number of successive connection errors
before host blocking occurs, set the
max_connect_errors system
variable. For example, to set the value at startup put these
lines in the server my.cnf file:
[mysqld] max_connect_errors=10000
To change the value at runtime, do this:
SET GLOBAL max_connect_errors=10000;
The Performance Schema host_cache
table exposes the contents of the host cache. This table can
be examined using SELECT
statements, which may help you diagnose the causes of
connection problems. For information about this table, see
Section 27.12.19.2, “The host_cache Table”.
Flushing the host cache might be advisable or desirable under these conditions:
Some of your client hosts change IP address.
The error message
Host 'occurs for connections from legitimate hosts. (See Dealing with Blocked Hosts.)host_name' is blocked
Flushing the host cache has these effects:
It clears the in-memory host cache.
It removes all rows from the Performance Schema
host_cachetable that exposes the cache contents.It unblocks any blocked hosts. This enables further connection attempts from those hosts.
To flush the host cache, use any of these methods:
Change the value of the
host_cache_sizesystem variable. This requires theSYSTEM_VARIABLES_ADMINprivilege (or the deprecatedSUPERprivilege).Execute a
TRUNCATE TABLEstatement that truncates the Performance Schemahost_cachetable. This requires theDROPprivilege for the table.Execute a
FLUSH HOSTSstatement. This requires theRELOADprivilege.Execute a mysqladmin flush-hosts command. This requires the
DROPprivilege for the Performance Schemahost_cachetable or theRELOADprivilege.
The server uses the host cache to track errors that occur during the client connection process. If the following error occurs, it means that mysqld has received many connection requests from the given host that were interrupted in the middle:
Host 'host_name' is blocked because of many connection errors.
Unblock with 'mysqladmin flush-hosts'
The value of the
max_connect_errors system
variable determines how many successive interrupted connection
requests the server permits before blocking a host. After
max_connect_errors failed
requests without a successful connection, the server assumes
that something is wrong (for example, that someone is trying
to break in), and blocks the host from further connection
requests.
To unblock blocked hosts, flush the host cache; see Flushing the Host Cache.
Alternatively, to avoid having the error message occur, set
max_connect_errors as
described in Configuring the Host Cache. The
default value of
max_connect_errors is 100.
Increasing max_connect_errors
to a large value makes it less likely that a host reaches the
threshold and becomes blocked. However, if the Host
'
error message occurs, first verify that there is nothing wrong
with TCP/IP connections from the blocked hosts. It does no
good to increase the value of
host_name' is blockedmax_connect_errors if there
are network problems.
Support for IPv6 in MySQL includes these capabilities:
MySQL Server can accept TCP/IP connections from clients connecting over IPv6. For example, this command connects over IPv6 to the MySQL server on the local host:
shell>
mysql -h ::1To use this capability, two things must be true:
Your system must be configured to support IPv6. See Section 5.1.13.1, “Verifying System Support for IPv6”.
The default MySQL server configuration permits IPv6 connections in addition to IPv4 connections. To change the default configuration, start the server with the
bind_addresssystem variable set to an appropriate value. See Section 5.1.8, “Server System Variables”.
MySQL account names permit IPv6 addresses to enable DBAs to specify privileges for clients that connect to the server over IPv6. See Section 6.2.4, “Specifying Account Names”. IPv6 addresses can be specified in account names in statements such as
CREATE USER,GRANT, andREVOKE. For example:mysql>
CREATE USER 'bill'@'::1' IDENTIFIED BY 'secret';mysql>GRANT SELECT ON mydb.* TO 'bill'@'::1';IPv6 functions enable conversion between string and internal format IPv6 address formats, and checking whether values represent valid IPv6 addresses. For example,
INET6_ATON()andINET6_NTOA()are similar toINET_ATON()andINET_NTOA(), but handle IPv6 addresses in addition to IPv4 addresses. See Section 12.24, “Miscellaneous Functions”.From MySQL 8.0.14, Group Replication group members can use IPv6 addresses for communications within the group. A group can contain a mix of members using IPv6 and members using IPv4. See Section 18.4.5, “Support For IPv6 And For Mixed IPv6 And IPv4 Groups”.
The following sections describe how to set up MySQL so that clients can connect to the server over IPv6.
Before MySQL Server can accept IPv6 connections, the operating system on your server host must support IPv6. As a simple test to determine whether that is true, try this command:
shell> ping6 ::1
16 bytes from ::1, icmp_seq=0 hlim=64 time=0.171 ms
16 bytes from ::1, icmp_seq=1 hlim=64 time=0.077 ms
...
To produce a description of your system's network interfaces, invoke ifconfig -a and look for IPv6 addresses in the output.
If your host does not support IPv6, consult your system documentation for instructions on enabling it. It might be that you need only reconfigure an existing network interface to add an IPv6 address. Or a more extensive change might be needed, such as rebuilding the kernel with IPv6 options enabled.
These links may be helpful in setting up IPv6 on various platforms:
The MySQL server listens on one or more network sockets for TCP/IP connections. Each socket is bound to one address, but it is possible for an address to map onto multiple network interfaces.
Set the bind_address system
variable at server startup to specify the TCP/IP connections
that a server instance accepts. As of MySQL 8.0.13, you can
specify multiple values for this option, including any
combination of IPv6 addresses, IPv4 addresses, and host names
that resolve to IPv6 or IPv4 addresses. Alternatively, you can
specify one of the wildcard address formats that permit
listening on multiple network interfaces. A value of *, which is
the default, or a value of ::, permit both
IPv4 and IPv6 connections on all server host IPv4 and IPv6
interfaces. For more information, see the
bind_address description in
Section 5.1.8, “Server System Variables”.
The following procedure shows how to configure MySQL to permit
IPv6 connections by clients that connect to the local server
using the ::1 local host address. The
instructions given here assume that your system supports IPv6.
Start the MySQL server with an appropriate
bind_addresssetting to permit it to accept IPv6 connections. For example, put the following lines in the server option file and restart the server:[mysqld] bind_address = *
Specifying * (or
::) as the value forbind_addresspermits both IPv4 and IPv6 connections on all server host IPv4 and IPv6 interfaces. If you want to bind the server to a specific list of addresses, you can do this as of MySQL 8.0.13 by specifying a comma-separated list of values forbind_address. This example specifies the local host addresses for both IPv4 and IPv6:[mysqld] bind_address = 127.0.0.1,::1
For more information, see the
bind_addressdescription in Section 5.1.8, “Server System Variables”.As an administrator, connect to the server and create an account for a local user who can connect from the
::1local IPv6 host address:mysql>
CREATE USER 'ipv6user'@'::1' IDENTIFIED BY 'ipv6pass';For the permitted syntax of IPv6 addresses in account names, see Section 6.2.4, “Specifying Account Names”. In addition to the
CREATE USERstatement, you can issueGRANTstatements that give specific privileges to the account, although that is not necessary for the remaining steps in this procedure.Invoke the mysql client to connect to the server using the new account:
shell>
mysql -h ::1 -u ipv6user -pipv6passTry some simple statements that show connection information:
mysql>
STATUS... Connection: ::1 via TCP/IP ... mysql>SELECT CURRENT_USER(), @@bind_address;+----------------+----------------+ | CURRENT_USER() | @@bind_address | +----------------+----------------+ | ipv6user@::1 | :: | +----------------+----------------+
The following procedure shows how to configure MySQL to permit IPv6 connections by remote clients. It is similar to the preceding procedure for local clients, but the server and client hosts are distinct and each has its own nonlocal IPv6 address. The example uses these addresses:
Server host: 2001:db8:0:f101::1 Client host: 2001:db8:0:f101::2
These addresses are chosen from the nonroutable address range recommended by IANA for documentation purposes and suffice for testing on your local network. To accept IPv6 connections from clients outside the local network, the server host must have a public address. If your network provider assigns you an IPv6 address, you can use that. Otherwise, another way to obtain an address is to use an IPv6 broker; see Section 5.1.13.5, “Obtaining an IPv6 Address from a Broker”.
Start the MySQL server with an appropriate
bind_addresssetting to permit it to accept IPv6 connections. For example, put the following lines in the server option file and restart the server:[mysqld] bind_address = *
Specifying * (or
::) as the value forbind_addresspermits both IPv4 and IPv6 connections on all server host IPv4 and IPv6 interfaces. If you want to bind the server to a specific list of addresses, you can do this as of MySQL 8.0.13 by specifying a comma-separated list of values forbind_address. This example specifies an IPv4 address as well as the required server host IPv6 address:[mysqld] bind_address = 198.51.100.20,2001:db8:0:f101::1
For more information, see the
bind_addressdescription in Section 5.1.8, “Server System Variables”.On the server host (
2001:db8:0:f101::1), create an account for a user who can connect from the client host (2001:db8:0:f101::2):mysql>
CREATE USER 'remoteipv6user'@'2001:db8:0:f101::2' IDENTIFIED BY 'remoteipv6pass';On the client host (
2001:db8:0:f101::2), invoke the mysql client to connect to the server using the new account:shell>
mysql -h 2001:db8:0:f101::1 -u remoteipv6user -premoteipv6passTry some simple statements that show connection information:
mysql>
STATUS... Connection: 2001:db8:0:f101::1 via TCP/IP ... mysql>SELECT CURRENT_USER(), @@bind_address;+-----------------------------------+----------------+ | CURRENT_USER() | @@bind_address | +-----------------------------------+----------------+ | remoteipv6user@2001:db8:0:f101::2 | :: | +-----------------------------------+----------------+
If you do not have a public IPv6 address that enables your system to communicate over IPv6 outside your local network, you can obtain one from an IPv6 broker. The Wikipedia IPv6 Tunnel Broker page lists several brokers and their features, such as whether they provide static addresses and the supported routing protocols.
After configuring your server host to use a broker-supplied IPv6
address, start the MySQL server with an appropriate
bind_address setting to permit
the server to accept IPv6 connections. You can specify * (or
::) as the
bind_address value, or bind the
server to the specific IPv6 address provided by the broker. For
more information, see the
bind_address description in
Section 5.1.8, “Server System Variables”.
Note that if the broker allocates dynamic addresses, the address provided for your system might change the next time you connect to the broker. If so, any accounts you create that name the original address become invalid. To bind to a specific address but avoid this change-of-address problem, you might be able to arrange with the broker for a static IPv6 address.
The following example shows how to use Freenet6 as the broker and the gogoc IPv6 client package on Gentoo Linux.
Create an account at Freenet6 by visiting this URL and signing up:
http://gogonet.gogo6.com
After creating the account, go to this URL, sign in, and create a user ID and password for the IPv6 broker:
http://gogonet.gogo6.com/page/freenet6-registration
As
root, install gogoc:shell>
emerge gogocEdit
/etc/gogoc/gogoc.confto set theuseridandpasswordvalues. For example:userid=gogouser passwd=gogopass
Start gogoc:
shell>
/etc/init.d/gogoc startTo start gogoc each time your system boots, execute this command:
shell>
rc-update add gogoc defaultUse ping6 to try to ping a host:
shell>
ping6 ipv6.google.comTo see your IPv6 address:
shell>
ifconfig tun
A network namespace is a logical copy of the network stack from the host system. Network namespaces are useful for setting up containers or virtual environments. Each namespace has its own IP addresses, network interfaces, routing tables, and so forth. The default or global namespace is the one in which the host system physical interfaces exist.
Namespace-specific address spaces can lead to problems when MySQL
connections cross namespaces. For example, the network address
space for a MySQL instance running in a container or virtual
network may differ from the address space of the host machine.
This can produce phenomena such as a client connection from an
address in one namespace appearing to the MySQL server to be
coming from a different address, even for client and server
running on the same machine. Suppose that both processes run on a
host with IP address 203.0.113.10 but use
different namespaces. A connection may produce a result like this:
shell>mysql --user=admin --host=203.0.113.10 --protocol=tcpmysql>SELECT USER();+--------------------+ | USER() | +--------------------+ | admin@198.51.100.2 | +--------------------+
In this case, the expected USER()
value is admin@203.0.113.10. Such behavior can
make it difficult to assign account permissions properly if the
address from which an connection originates is not what it
appears.
To address this issue, MySQL enables specifying the network namespace to use for TCP/IP connections, so that both endpoints of connections use an agreed-upon common address space.
MySQL 8.0.22 and higher supports network namespaces on platforms that implement them. Support within MySQL applies to:
The following sections describe how to use network namespaces in MySQL:
Prior to using network namespace support in MySQL, these host system prerequisites must be satisifed:
The host operating system must support network namespaces. (For example, Linux.)
Any network namespace to be used by MySQL must first be created on the host system.
Host name resolution must be configured by the system administrator to support network namespaces.
NoteA known limitation is that, within MySQL, host name resolution does not work for names specified in network namespace-specific host files. For example, if the address for a host name in the
rednamespace is specified in the/etc/netns/red/hostsfile, binding to the name fails on both the server and client sides. The workaround is to use the IP address rather than the host name.The system administrator must enable the
CAP_SYS_ADMINoperating system privilege for the MySQL binaries that support network namespaces (mysqld, mysql, mysqlxtest).ImportantEnabling
CAP_SYS_ADMINis a security sensitive operation because it enables a process to perform other privileged actions in addition to setting namespaces. For a description of its effects, see https://man7.org/linux/man-pages/man7/capabilities.7.html.Because
CAP_SYS_ADMINmust be enabled explicitly by the system administrator, MySQL binaries by default do not have network namespace support enabled. The system administrator should evaluate the security implications of running MySQL processes withCAP_SYS_ADMINbefore enabling it.
The instructions in the following example set up network
namespaces named red and
blue. The names you choose may differ, as may
the network addresses and interfaces on your host system.
Invoke the commands shown here either as the
root operating system user or by prefixing
each command with sudo. For example, to
invoke the ip or setcap
command if you are not root, use
sudo ip or sudo setcap.
To configure network namespaces, use the ip command. For some operations, the ip command must execute within a particular namespace (which must already exist). In such cases, begin the command like this:
ip netns exec namespace_name
For example, this command executes within the
red namespace to bring up the loopback
interface:
ip netns exec red ip link set lo up
To add namespaces named red and
blue, each with its own virtual Ethernet
device used as a link between namespaces and its own loopback
interface:
ip netns add red ip link add veth-red type veth peer name vpeer-red ip link set vpeer-red netns red ip addr add 192.0.2.1/24 dev veth-red ip link set veth-red up ip netns exec red ip addr add 192.0.2.2/24 dev vpeer-red ip netns exec red ip link set vpeer-red up ip netns exec red ip link set lo up ip netns add blue ip link add veth-blue type veth peer name vpeer-blue ip link set vpeer-blue netns blue ip addr add 198.51.100.1/24 dev veth-blue ip link set veth-blue up ip netns exec blue ip addr add 198.51.100.2/24 dev vpeer-blue ip netns exec blue ip link set vpeer-blue up ip netns exec blue ip link set lo up # if you want to enable inter-subnet routing... sysctl net.ipv4.ip_forward=1 ip netns exec red ip route add default via 192.0.2.1 ip netns exec blue ip route add default via 198.51.100.1
A diagram of the links between namespaces looks like this:
red global blue
192.0.2.2 <=> 192.0.2.1
(vpeer-red) (veth-red)
198.51.100.1 <=> 198.51.100.2
(veth-blue) (vpeer-blue)
To check which namespaces and links exist:
ip netns list ip link list
To see the routing tables for the global and named namespaces:
ip route show ip netns exec red ip route show ip netns exec blue ip route show
To remove the red and blue
links and namespaces:
ip link del veth-red ip link del veth-blue ip netns del red ip netns del blue sysctl net.ipv4.ip_forward=0
So that the MySQL binaries that include network namespace
support can actually use namespaces, you must grant them the
CAP_SYS_ADMIN capability. The following
setcap commands assume that you have changed
location to the directory containing your MySQL binaries (adjust
the pathname for your system as necessary):
cd /usr/local/mysql/bin
To grant CAP_SYS_ADMIN capability to the
appropriate binaries:
setcap cap_sys_admin+ep ./mysqld setcap cap_sys_admin+ep ./mysql setcap cap_sys_admin+ep ./mysqlxtest
To check CAP_SYS_ADMIN capability:
shell> getcap ./mysqld ./mysql ./mysqlxtest
./mysqld = cap_sys_admin+ep
./mysql = cap_sys_admin+ep
./mysqlxtest = cap_sys_admin+ep
To remove CAP_SYS_ADMIN capability:
setcap -r ./mysqld setcap -r ./mysql setcap -r ./mysqlxtest
If you reinstall binaries to which you have previously applied
setcap, you must use
setcap again. For example, if you perform
an in-place MySQL upgrade, failure to grant the
CAP_SYS_ADMIN capability again results in
namespace-related failures. The server fails with this error
for attempts to bind to an address with a named namespace:
[ERROR] [MY-013408] [Server] setns() failed with error 'Operation not permitted'
A client invoked with the
--network-namespace option fails
like this:
ERROR: Network namespace error: Operation not permitted
Assuming that the preceding host system prerequisites have been satisfied, MySQL enables configuring the server-side namespace for the listening (inbound) side of connections and the client-side namespace for the outbound side of connections.
On the server side, the
bind_address,
admin_address, and
mysqlx_bind_address system
variables have extended syntax for specifying the network
namespace to use for a given IP address or host name on which to
listen for incoming connections. To specify a namespace for an
address, add a slash and the namespace name. For example, a
server my.cnf file might contain these
lines:
[mysqld] bind_address = 127.0.1.1,192.0.2.2/red,198.51.100.2/blue admin_address = 102.0.2.2/red mysqlx_bind_address = 102.0.2.2/red
These rules apply:
A network namespace can be specified for an IP address or a host name.
A network namespace cannot be specified for a wildcard IP address.
For a given address, the network namespace is optional. If given, it must be specified as a
/suffix immediately following the address.nsAn address with no
/suffix uses the host system global namespace. The global namespace is therefore the default.nsAn address with a
/suffix uses the namespace namednsns.The host system must support network namespaces and each named namespace must previously have been set up. Naming a nonexistent namespace produces an error.
bind_addressand (as of MySQL 8.0.21)mysqlx_bind_addressaccept a list of multiple comma-separated addresses, the variable value can specify addresses in the global namespace, in named namespaces, or a mix.
If an error occurs during server startup for attempts to use a namespace, the server does not start. If errors occur for X Plugin during plugin initialization such that it is unable to bind to any address, the plugin fails its initialization sequence and the server does not load it.
On the client side, a network namespace can be specified in these contexts:
For the mysql client and the mysqlxtest test suite client, use the
--network-namespaceoption. For example:mysql --host=192.0.2.2 --network-namespace=red
If the
--network-namespaceoption is omitted, the connection uses the default (global) namespace.For replication connections from replica servers to source servers, use the
CHANGE MASTER TOstatement and specify theNETWORK_NAMESPACEoption. For example:CHANGE MASTER TO MASTER_HOST = '192.0.2.2', NETWORK_NAMESPACE = 'red';
If the
NETWORK_NAMESPACEoption is omitted, replication connections use the default (global) namespace.
The following example sets up a MySQL server that listens for
connections in the global, red, and
blue namespaces, and shows how to configure
accounts that connect from the red and
blue namespaces. It is assumed that the
red and blue namespaces
have already been created as shown in
Host System Prerequisites.
Configure the server to listen on addresses in multiple namespaces. Put these lines in the server
my.cnffile and start the server:[mysqld] bind_address = 127.0.1.1,192.0.2.2/red,198.51.100.2/blue
The value tells the server to listen on the loopback address
127.0.0.1in the global namespace, the address192.0.2.2in therednamespace, and the address198.51.100.2in thebluenamespace.Connect to the server in the global namespace and create accounts that have permission to connect from an address in the address space of each named namespace:
shell>
mysql -u root -h 127.0.0.1 -pEnter password:root_passwordmysql>CREATE USER 'red_user'@'192.0.2.2'IDENTIFIED BY 'mysql>red_user_password';CREATE USER 'blue_user'@'198.51.100.2'IDENTIFIED BY 'blue_user_password';Verify that you can connect to the server in each named namespace:
shell>
mysql -u red_user -h 192.0.2.2 --network-namespace=red -pEnter password:red_user_passwordmysql>SELECT USER();+--------------------+ | USER() | +--------------------+ | red_user@192.0.2.2 | +--------------------+shell>
mysql -u blue_user -h 198.51.100.2 --network-namespace=blue -pEnter password:blue_user_passwordmysql>SELECT USER();+------------------------+ | USER() | +------------------------+ | blue_user@198.51.100.2 | +------------------------+NoteYou might see different results from
USER(), which can return a value that includes a host name rather than an IP address if your DNS is configured to be able to resolve the address to the corresponding host name and the server is not run with theskip_name_resolvesystem variable enabled.You might also try invoking mysql without the
--network-namespaceoption to see whether the connection attempt succeeds, and, if so, how theUSER()value is affected.
For replication monitoring purposes, these information sources have a column that displays the applicable network namespace for connections:
The Performance Schema
replication_connection_configurationtable. See Section 27.12.11.1, “The replication_connection_configuration Table”.The replica server connection metadata repository. See Section 17.2.4.2, “Replication Metadata Repositories”.
The
SHOW REPLICA | SLAVE STATUSstatement. See Section 13.7.7.35, “SHOW REPLICA | SLAVE STATUS Statement”.
This section describes the time zone settings maintained by MySQL, how to load the system tables required for named time support, how to stay current with time zone changes, and how to enable leap-second support.
Beginning with MySQL 8.0.19, time zone offsets are also supported for inserted datetime values; see Section 11.2.2, “The DATE, DATETIME, and TIMESTAMP Types”, for more information.
For information about time zone settings in replication setups, see Section 17.5.1.14, “Replication and System Functions” and Section 17.5.1.33, “Replication and Time Zones”.
MySQL Server maintains several time zone settings:
The system time zone. When the server starts, it attempts to determine the time zone of the host machine automatically and uses it to set the
system_time_zonesystem variable. The value does not change thereafter.To explicitly specify the system time zone for MySQL Server at startup, set the
TZenvironment variable before you start mysqld. If you start the server using mysqld_safe, its--timezoneoption provides another way to set the system time zone. The permissible values forTZand--timezoneare system dependent. Consult your operating system documentation to see what values are acceptable.The server current time zone. The global
time_zonesystem variable indicates the time zone the server currently is operating in. The initialtime_zonevalue is'SYSTEM', which indicates that the server time zone is the same as the system time zone.NoteIf set to
SYSTEM, every MySQL function call that requires a time zone calculation makes a system library call to determine the current system time zone. This call may be protected by a global mutex, resulting in contention.The initial global server time zone value can be specified explicitly at startup with the
--default-time-zoneoption on the command line, or you can use the following line in an option file:default-time-zone='
timezone'If you have the
SYSTEM_VARIABLES_ADMINprivilege (or the deprecatedSUPERprivilege), you can set the global server time zone value at runtime with this statement:SET GLOBAL time_zone =
timezone;Per-session time zones. Each client that connects has its own session time zone setting, given by the session
time_zonevariable. Initially, the session variable takes its value from the globaltime_zonevariable, but the client can change its own time zone with this statement:SET time_zone =
timezone;
The session time zone setting affects display and storage of
time values that are zone-sensitive. This includes the values
displayed by functions such as
NOW() or
CURTIME(), and values stored in
and retrieved from TIMESTAMP
columns. Values for TIMESTAMP
columns are converted from the session time zone to UTC for
storage, and from UTC to the session time zone for retrieval.
The session time zone setting does not affect values displayed
by functions such as
UTC_TIMESTAMP() or values in
DATE,
TIME, or
DATETIME columns. Nor are values
in those data types stored in UTC; the time zone applies for
them only when converting from
TIMESTAMP values. If you want
locale-specific arithmetic for
DATE,
TIME, or
DATETIME values, convert them to
UTC, perform the arithmetic, and then convert back.
The current global and session time zone values can be retrieved like this:
SELECT @@GLOBAL.time_zone, @@SESSION.time_zone;
timezone values can be given in
several formats, none of which are case-sensitive:
As the value
'SYSTEM', indicating that the server time zone is the same as the system time zone.As a string indicating an offset from UTC of the form
[, prefixed with aH]H:MM+or-, such as'+10:00','-6:00', or'+05:30'. A leading zero can optionally be used for hours values less than 10; MySQL prepends a leading zero when storing and retriving the value in such cases. MySQL converts'-00:00'or'-0:00'to'+00:00'.Prior to MySQL 8.0.19, this value had to be in the range
'-12:59'to'+13:00', inclusive; beginning with MySQL 8.0.19, the permitted range is'-14:00'to'+14:00', inclusive.As a named time zone, such as
'Europe/Helsinki','US/Eastern','MET', or'UTC'.
Several tables in the mysql system schema
exist to store time zone information (see
Section 5.3, “The mysql System Schema”). The MySQL installation
procedure creates the time zone tables, but does not load them.
To do so manually, use the following instructions.
Loading the time zone information is not necessarily a one-time operation because the information changes occasionally. When such changes occur, applications that use the old rules become out of date and you may find it necessary to reload the time zone tables to keep the information used by your MySQL server current. See Staying Current with Time Zone Changes.
If your system has its own
zoneinfo database (the set
of files describing time zones), use the
mysql_tzinfo_to_sql program to load the time
zone tables. Examples of such systems are Linux, macOS, FreeBSD,
and Solaris. One likely location for these files is the
/usr/share/zoneinfo directory. If your
system has no zoneinfo database, you can use a downloadable
package, as described later in this section.
To load the time zone tables from the command line, pass the zoneinfo directory path name to mysql_tzinfo_to_sql and send the output into the mysql program. For example:
mysql_tzinfo_to_sql /usr/share/zoneinfo | mysql -u root -p mysql
The mysql command shown here assumes that you
connect to the server using an account such as
root that has privileges for modifying tables
in the mysql system schema. Adjust the
connection parameters as required.
mysql_tzinfo_to_sql reads your system's time zone files and generates SQL statements from them. mysql processes those statements to load the time zone tables.
mysql_tzinfo_to_sql also can be used to load a single time zone file or generate leap second information:
To load a single time zone file
tz_filethat corresponds to a time zone nametz_name, invoke mysql_tzinfo_to_sql like this:mysql_tzinfo_to_sql
tz_filetz_name| mysql -u root -p mysqlWith this approach, you must execute a separate command to load the time zone file for each named zone that the server needs to know about.
If your time zone must account for leap seconds, initialize leap second information like this, where
tz_fileis the name of your time zone file:mysql_tzinfo_to_sql --leap
tz_file| mysql -u root -p mysql
After running mysql_tzinfo_to_sql, restart the server so that it does not continue to use any previously cached time zone data.
If your system has no zoneinfo database (for example, Windows), you can use a package containing SQL statements that is available for download at the MySQL Developer Zone:
https://dev.mysql.com/downloads/timezones.html
Do not use a downloadable time zone package if your system has a zoneinfo database. Use the mysql_tzinfo_to_sql utility instead. Otherwise, you may cause a difference in datetime handling between MySQL and other applications on your system.
To use an SQL-statement time zone package that you have downloaded, unpack it, then load the unpacked file contents into the time zone tables:
mysql -u root -p mysql < file_name
Then restart the server.
Do not use a downloadable time zone
package that contains MyISAM tables. That
is intended for older MySQL versions. MySQL now uses
InnoDB for the time zone tables. Trying to
replace them with MyISAM tables causes
problems.
When time zone rules change, applications that use the old rules become out of date. To stay current, it is necessary to make sure that your system uses current time zone information is used. For MySQL, there are multiple factors to consider in staying current:
The operating system time affects the value that the MySQL server uses for times if its time zone is set to
SYSTEM. Make sure that your operating system is using the latest time zone information. For most operating systems, the latest update or service pack prepares your system for the time changes. Check the website for your operating system vendor for an update that addresses the time changes.If you replace the system's
/etc/localtimetime zone file with a version that uses rules differing from those in effect at mysqld startup, restart mysqld so that it uses the updated rules. Otherwise, mysqld might not notice when the system changes its time.If you use named time zones with MySQL, make sure that the time zone tables in the
mysqldatabase are up to date:If your system has its own zoneinfo database, reload the MySQL time zone tables whenever the zoneinfo database is updated.
For systems that do not have their own zoneinfo database, check the MySQL Developer Zone for updates. When a new update is available, download it and use it to replace the content of your current time zone tables.
For instructions for both methods, see Populating the Time Zone Tables. mysqld caches time zone information that it looks up, so after updating the time zone tables, restart mysqld to make sure that it does not continue to serve outdated time zone data.
If you are uncertain whether named time zones are available, for use either as the server's time zone setting or by clients that set their own time zone, check whether your time zone tables are empty. The following query determines whether the table that contains time zone names has any rows:
mysql> SELECT COUNT(*) FROM mysql.time_zone_name;
+----------+
| COUNT(*) |
+----------+
| 0 |
+----------+
A count of zero indicates that the table is empty. In this case, no applications currently are using named time zones, and you need not update the tables (unless you want to enable named time zone support). A count greater than zero indicates that the table is not empty and that its contents are available to be used for named time zone support. In this case, be sure to reload your time zone tables so that applications that use named time zones can obtain correct query results.
To check whether your MySQL installation is updated properly for a change in Daylight Saving Time rules, use a test like the one following. The example uses values that are appropriate for the 2007 DST 1-hour change that occurs in the United States on March 11 at 2 a.m.
The test uses this query:
SELECT
CONVERT_TZ('2007-03-11 2:00:00','US/Eastern','US/Central') AS time1,
CONVERT_TZ('2007-03-11 3:00:00','US/Eastern','US/Central') AS time2;
The two time values indicate the times at which the DST change occurs, and the use of named time zones requires that the time zone tables be used. The desired result is that both queries return the same result (the input time, converted to the equivalent value in the 'US/Central' time zone).
Before updating the time zone tables, you see an incorrect result like this:
+---------------------+---------------------+ | time1 | time2 | +---------------------+---------------------+ | 2007-03-11 01:00:00 | 2007-03-11 02:00:00 | +---------------------+---------------------+
After updating the tables, you should see the correct result:
+---------------------+---------------------+ | time1 | time2 | +---------------------+---------------------+ | 2007-03-11 01:00:00 | 2007-03-11 01:00:00 | +---------------------+---------------------+
Leap second values are returned with a time part that ends with
:59:59. This means that a function such as
NOW() can return the same value
for two or three consecutive seconds during the leap second. It
remains true that literal temporal values having a time part
that ends with :59:60 or
:59:61 are considered invalid.
If it is necessary to search for
TIMESTAMP values one second
before the leap second, anomalous results may be obtained if you
use a comparison with ' values. The following example
demonstrates this. It changes the session time zone to UTC so
there is no difference between internal
YYYY-MM-DD
hh:mm:ss'TIMESTAMP values (which are in
UTC) and displayed values (which have time zone correction
applied).
mysql>CREATE TABLE t1 (a INT,ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (ts));Query OK, 0 rows affected (0.01 sec) mysql>-- change to UTCmysql>SET time_zone = '+00:00';Query OK, 0 rows affected (0.00 sec) mysql>-- Simulate NOW() = '2008-12-31 23:59:59'mysql>SET timestamp = 1230767999;Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO t1 (a) VALUES (1);Query OK, 1 row affected (0.00 sec) mysql>-- Simulate NOW() = '2008-12-31 23:59:60'mysql>SET timestamp = 1230768000;Query OK, 0 rows affected (0.00 sec) mysql>INSERT INTO t1 (a) VALUES (2);Query OK, 1 row affected (0.00 sec) mysql>-- values differ internally but display the samemysql>SELECT a, ts, UNIX_TIMESTAMP(ts) FROM t1;+------+---------------------+--------------------+ | a | ts | UNIX_TIMESTAMP(ts) | +------+---------------------+--------------------+ | 1 | 2008-12-31 23:59:59 | 1230767999 | | 2 | 2008-12-31 23:59:59 | 1230768000 | +------+---------------------+--------------------+ 2 rows in set (0.00 sec) mysql>-- only the non-leap value matchesmysql>SELECT * FROM t1 WHERE ts = '2008-12-31 23:59:59';+------+---------------------+ | a | ts | +------+---------------------+ | 1 | 2008-12-31 23:59:59 | +------+---------------------+ 1 row in set (0.00 sec) mysql>-- the leap value with seconds=60 is invalidmysql>SELECT * FROM t1 WHERE ts = '2008-12-31 23:59:60';Empty set, 2 warnings (0.00 sec)
To work around this, you can use a comparison based on the UTC value actually stored in the column, which has the leap second correction applied:
mysql>-- selecting using UNIX_TIMESTAMP value return leap valuemysql>SELECT * FROM t1 WHERE UNIX_TIMESTAMP(ts) = 1230768000;+------+---------------------+ | a | ts | +------+---------------------+ | 2 | 2008-12-31 23:59:59 | +------+---------------------+ 1 row in set (0.00 sec)
MySQL supports creation and management of resource groups, and permits assigning threads running within the server to particular groups so that threads execute according to the resources available to the group. Group attributes enable control over its resources, to enable or restrict resource consumption by threads in the group. DBAs can modify these attributes as appropriate for different workloads.
Currently, CPU time is a manageable resource, represented by the concept of “virtual CPU” as a term that includes CPU cores, hyperthreads, hardware threads, and so forth. The server determines at startup how many virtual CPUs are available, and database administrators with appropriate privileges can associate these CPUs with resource groups and assign threads to groups.
For example, to manage execution of batch jobs that need not
execute with high priority, a DBA can create a
Batch resource group, and adjust its priority
up or down depending on how busy the server is. (Perhaps batch
jobs assigned to the group should run at lower priority during the
day and at higher priority during the night.) The DBA can also
adjust the set of CPUs available to the group. Groups can be
enabled or disabled to control whether threads are assignable to
them.
The following sections describe aspects of resource group use in MySQL:
On some platforms or MySQL server configurations, resource groups are unavailable or have limitations. In particular, Linux systems might require a manual step for some installation methods. For details, see Resource Group Restrictions.
These capabilities provide the SQL interface for resource group management in MySQL:
SQL statements enable creating, altering, and dropping resource groups, and enable assigning threads to resource groups. An optimizer hint enables assigning individual statements to resource groups.
Resource group privileges provide control over which users can perform resource group operations.
The
INFORMATION_SCHEMA.RESOURCE_GROUPStable exposes information about resource group definitions and the Performance Schemathreadstable shows the resource group assignment for each thread.Status variables provide execution counts for each management SQL statement.
Resource groups have attributes that define the group. All attributes can be set at group creation time. Some attributes are fixed at creation time; others can be modified any time thereafter.
These attributes are defined at resource group creation time and cannot be modified:
Each group has a name. Resource group names are identifiers like table and column names, and need not be quoted in SQL statements unless they contain special characters or are reserved words. Group names are not case-sensitive and may be up to 64 characters long.
Each group has a type, which is either
SYSTEMorUSER. The resource group type affects the range of priority values assignable to the group, as described later. This attribute together with the differences in permitted priorities enables system threads to be identified so as to protect them from contention for CPU resources against user threads.System and user threads correspond to background and foreground threads as listed in the Performance Schema
threadstable.
These attributes are defined at resource group creation time and can be modified any time thereafter:
The CPU affinity is the set of virtual CPUs the resource group can use. An affinity can be any nonempty subset of the available CPUs. If a group has no affinity, it can use all available CPUs.
The thread priority is the execution priority for threads assigned to the resource group. Priority values range from -20 (highest priority) to 19 (lowest priority). The default priority is 0, for both system and user groups.
System groups are permitted a higher priority than user groups, ensuring that user threads never have a higher priority than system threads:
For system resource groups, the permitted priority range is -20 to 0.
For user resource groups, the permitted priority range is 0 to 19.
Each group can be enabled or disabled, affording administrators control over thread assignment. Threads can be assigned only to enabled groups.
By default, there is one system group and one user group, named
SYS_default and
USR_default, respectively. These default
groups cannot be dropped and their attributes cannot be
modified. Each default group has no CPU affinity and priority 0.
Newly created system and user threads are assigned to the
SYS_default and
USR_default groups, respectively.
For user-defined resource groups, all attributes are assigned at group creation time. After a group has been created, its attributes can be modified, with the exception of the name and type attributes.
To create and manage user-defined resource groups, use these SQL statements:
CREATE RESOURCE GROUPcreates a new group. See Section 13.7.2.2, “CREATE RESOURCE GROUP Statement”.ALTER RESOURCE GROUPmodifies an existing group. See Section 13.7.2.1, “ALTER RESOURCE GROUP Statement”.DROP RESOURCE GROUPdrops an existing group. See Section 13.7.2.3, “DROP RESOURCE GROUP Statement”.
Those statements require the
RESOURCE_GROUP_ADMIN privilege.
To manage resource group assignments, use these capabilities:
SET RESOURCE GROUPassigns threads to a group. See Section 13.7.2.4, “SET RESOURCE GROUP Statement”.The
RESOURCE_GROUPoptimizer hint assigns individual statements to a group. See Section 8.9.3, “Optimizer Hints”.
Those operations require the
RESOURCE_GROUP_ADMIN or
RESOURCE_GROUP_USER privilege.
Resource group definitions are stored in the
resource_groups data dictionary table so that
groups persist across server restarts. Because
resource_groups is part of the data
dictionary, it is not directly accessible by users. Resource
group information is available using the
INFORMATION_SCHEMA.RESOURCE_GROUPS
table, which is implemented as a view on the data dictionary
table. See
Section 26.26, “The INFORMATION_SCHEMA RESOURCE_GROUPS Table”.
Initially, the RESOURCE_GROUPS
table has these rows describing the default groups:
mysql> SELECT * FROM INFORMATION_SCHEMA.RESOURCE_GROUPS\G
*************************** 1. row ***************************
RESOURCE_GROUP_NAME: USR_default
RESOURCE_GROUP_TYPE: USER
RESOURCE_GROUP_ENABLED: 1
VCPU_IDS: 0-3
THREAD_PRIORITY: 0
*************************** 2. row ***************************
RESOURCE_GROUP_NAME: SYS_default
RESOURCE_GROUP_TYPE: SYSTEM
RESOURCE_GROUP_ENABLED: 1
VCPU_IDS: 0-3
THREAD_PRIORITY: 0
The THREAD_PRIORITY values are 0, indicating
the default priority. The VCPU_IDS values
show a range comprising all available CPUs. For the default
groups, the displayed value varies depending on the system on
which the MySQL server runs.
Earlier discussion mentioned a scenario involving a resource
group named Batch to manage execution of
batch jobs that need not execute with high priority. To create
such a group, use a statement similar to this:
CREATE RESOURCE GROUP Batch TYPE = USER VCPU = 2-3 -- assumes a system with at least 4 CPUs THREAD_PRIORITY = 10;
To verify that the resource group was created as expected, check
the RESOURCE_GROUPS table:
mysql>SELECT * FROM INFORMATION_SCHEMA.RESOURCE_GROUPSWHERE RESOURCE_GROUP_NAME = 'Batch'\G*************************** 1. row *************************** RESOURCE_GROUP_NAME: Batch RESOURCE_GROUP_TYPE: USER RESOURCE_GROUP_ENABLED: 1 VCPU_IDS: 2-3 THREAD_PRIORITY: 10
If the THREAD_PRIORITY value is 0 rather than
10, check whether your platform or system configuration limits
the resource group capability; see
Resource Group Restrictions.
To assign a thread to the Batch group, do
this:
SET RESOURCE GROUP Batch FOR thread_id;
Thereafter, statements in the named thread execute with
Batch group resources.
If a session's own current thread should be in the
Batch group, execute this statement within
the session:
SET RESOURCE GROUP Batch;
Thereafter, statements in the session execute with
Batch group resources.
To execute a single statement using the Batch
group, use the RESOURCE_GROUP
optimizer hint:
INSERT /*+ RESOURCE_GROUP(Batch) */ INTO t2 VALUES(2);
Threads assigned to the Batch group execute
with its resources, which can be modified as desired:
For times when the system is highly loaded, decrease the number of CPUs assigned to the group, lower its priority, or (as shown) both:
ALTER RESOURCE GROUP Batch VCPU = 3 THREAD_PRIORITY = 19;
For times when the system is lightly loaded, increase the number of CPUs assigned to the group, raise its priority, or (as shown) both:
ALTER RESOURCE GROUP Batch VCPU = 0-3 THREAD_PRIORITY = 0;
Resource group management is local to the server on which it
occurs. Resource group SQL statements and modifications to the
resource_groups data dictionary table are not
written to the binary log and are not replicated.
On some platforms or MySQL server configurations, resource groups are unavailable or have limitations:
Resource groups are unavailable if the thread pool plugin is installed.
Resource groups are unavailable on macOS, which provides no API for binding CPUs to a thread.
On FreeBSD and Solaris, resource group thread priorities are ignored. (Effectively, all threads run at priority 0.) Attempts to change priorities result in a warning:
mysql>
ALTER RESOURCE GROUP abc THREAD_PRIORITY = 10;Query OK, 0 rows affected, 1 warning (0.18 sec) mysql>SHOW WARNINGS;+---------+------+-------------------------------------------------------------+ | Level | Code | Message | +---------+------+-------------------------------------------------------------+ | Warning | 4560 | Attribute thread_priority is ignored (using default value). | +---------+------+-------------------------------------------------------------+On Linux, resource groups thread priorities are ignored unless the
CAP_SYS_NICEcapability is set. GrantingCAP_SYS_NICEcapability to a process enables a range of privileges; consult http://man7.org/linux/man-pages/man7/capabilities.7.html for the full list. Please be careful when enabling this capability.On Linux platforms using systemd and kernel support for Ambient Capabilities (Linux 4.3 or newer), the recommended way to enable
CAP_SYS_NICEcapability is to modify the MySQL service file and leave the mysqld binary unmodified. To adjust the service file for MySQL, use this procedure:Run the appropriate command for your platform:
Oracle Linux, Red Hat, and Fedora systems:
shell>
sudo systemctl edit mysqldSUSE, Ubuntu, and Debian systems:
shell>
sudo systemctl edit mysql
Using an editor, add the following text to the service file:
[Service] AmbientCapabilities=CAP_SYS_NICE
Restart the MySQL service.
If you cannot enable the
CAP_SYS_NICEcapability as just described, it can be set manually using the setcap command, specifying the path name to the mysqld executable (this requires sudo access). You can check the capabilities using getcap. For example:shell>
sudo setcap cap_sys_nice+epshell>/path/to/mysqldgetcap/path/to/mysqld/path/to/mysqld= cap_sys_nice+epAs a safety measure, restrict execution of the mysqld binary to the
rootuser and users withmysqlgroup membership:shell>
sudo chown root:mysqlshell>/path/to/mysqldsudo chmod 0750/path/to/mysqldImportantIf manual use of setcap is required, it must be performed after each reinstall.
On Windows, threads run at one of five thread priority levels. The resource group thread priority range of -20 to 19 maps onto those levels as indicated in the following table.
Table 5.5 Resource Group Thread Priority on Windows
Priority Range Windows Priority Level -20 to -10 THREAD_PRIORITY_HIGHEST-9 to -1 THREAD_PRIORITY_ABOVE_NORMAL0 THREAD_PRIORITY_NORMAL1 to 10 THREAD_PRIORITY_BELOW_NORMAL11 to 19 THREAD_PRIORITY_LOWEST
MySQL Server supports a HELP
statement that returns information from the MySQL Reference Manual
(see Section 13.8.3, “HELP Statement”). This information is stored in
several tables in the mysql schema (see
Section 5.3, “The mysql System Schema”). Proper operation of the
HELP statement requires that these
help tables be initialized.
For a new installation of MySQL using a binary or source distribution on Unix, help-table content initialization occurs when you initialize the data directory (see Section 2.10.1, “Initializing the Data Directory”). For an RPM distribution on Linux or binary distribution on Windows, content initialization occurs as part of the MySQL installation process.
For a MySQL upgrade using a binary distribution, help-table
content is upgraded automatically by the server as of MySQL
8.0.16. Prior to MySQL 8.0.16, the content is not upgraded
automatically, but you can upgrade it manually. Locate the
fill_help_tables.sql file in the
share or share/mysql
directory. Change location into that directory and process the
file with the mysql client as follows:
mysql -u root -p mysql < fill_help_tables.sql
The command shown here assumes that you connect to the server
using an account such as root that has
privileges for modifying tables in the mysql
schema. Adjust the connection parameters as required.
Prior to MySQL 8.0.16, if you are working with Git and a MySQL
development source tree, the source tree contains only a
“stub” version of
fill_help_tables.sql. To obtain a non-stub
copy, use one from a source or binary distribution.
Each MySQL series has its own series-specific reference manual, so help-table content is series specific as well. This has implications for replication because help-table content should match the MySQL series. If you load MySQL 8.0 help content into a MySQL 8.0 replication server, it does not make sense to replicate that content to a replica server from a different MySQL series and for which that content is not appropriate. For this reason, as you upgrade individual servers in a replication scenario, you should upgrade each server's help tables, using the instructions given earlier. (Manual help-content upgrade is necessary only for replication servers from versions lower than 8.0.16. As mentioned in the preceding instructions, content upgrades occur automatically as of MySQL 8.0.16.)
The MySQL server implements several session state trackers. A client can enable these trackers to receive notification of changes to its session state.
One use for the tracker mechanism is to provide a means for MySQL connectors and client applications to determine whether any session context is available to permit session migration from one server to another. (To change sessions in a load-balanced environment, it is necessary to detect whether there is session state to take into consideration when deciding whether a switch can be made.)
Another use for the tracker mechanism is to permit applications to know when transactions can be moved from one session to another. Transaction state tracking enables this, which is useful for applications that may wish to move transactions from a busy server to one that is less loaded. For example, a load-balancing connector managing a client connection pool could move transactions between available sessions in the pool.
However, session switching cannot be done at arbitrary times. If a session is in the middle of a transaction for which reads or writes have been done, switching to a different session implies a transaction rollback on the original session. A session switch must be done only when a transaction does not yet have any reads or writes performed within it.
Examples of when transactions might reasonably be switched:
Immediately after
START TRANSACTIONAfter
COMMIT AND CHAIN
In addition to knowing transaction state, it is useful to know transaction characteristics, so as to use the same characteristics if the transaction is moved to a different session. The following characteristics are relevant for this purpose:
READ ONLY READ WRITE ISOLATION LEVEL WITH CONSISTENT SNAPSHOT
To support the preceding session-switching activities, notification is available for these types of client session state information:
Changes to these attributes of client session state:
The default schema (database).
Session-specific values for system variables.
User-defined variables.
Temporary tables.
Prepared statements.
The
session_track_state_changesystem variable controls this tracker.Changes to the default schema name. The
session_track_schemasystem variable controls this tracker.Changes to the session values of system variables. The
session_track_system_variablessystem variable controls this tracker.Available GTIDs. The
session_track_gtidssystem variable controls this tracker.Information about transaction state and characteristics. The
session_track_transaction_infosystem variable controls this tracker.
For descriptions of the tracker-related system variables, see Section 5.1.8, “Server System Variables”. Those system variables permit control over which change notifications occur, but do not provide a way to access notification information. Notification occurs in the MySQL client/server protocol, which includes tracker information in OK packets so that session state changes can be detected. To enable client applications to extract state-change information from OK packets returned by the server, the MySQL C API provides a pair of functions:
mysql_session_track_get_first()fetches the first part of the state-change information received from the server. See mysql_session_track_get_first().mysql_session_track_get_next()fetches any remaining state-change information received from the server. Following a successful call tomysql_session_track_get_first(), call this function repeatedly as long as it returns success. See mysql_session_track_get_next().
The mysqltest program has
disable_session_track_info and
enable_session_track_info commands that control
whether session tracker notifications occur. You can use these
commands to see from the command line what notifications SQL
statements produce. Suppose that a file
testscript contains the following
mysqltest script:
DROP TABLE IF EXISTS test.t1; CREATE TABLE test.t1 (i INT, f FLOAT); --enable_session_track_info SET @@SESSION.session_track_schema=ON; SET @@SESSION.session_track_system_variables='*'; SET @@SESSION.session_track_state_change=ON; USE information_schema; SET NAMES 'utf8mb4'; SET @@SESSION.session_track_transaction_info='CHARACTERISTICS'; SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; SET TRANSACTION READ WRITE; START TRANSACTION; SELECT 1; INSERT INTO test.t1 () VALUES(); INSERT INTO test.t1 () VALUES(1, RAND()); COMMIT;
Run the script as follows to see the information provided by the
enabled trackers. For a description of the
Tracker: information displayed by
mysqltest for the various trackers, see
mysql_session_track_get_first().
shell> mysqltest < testscript
DROP TABLE IF EXISTS test.t1;
CREATE TABLE test.t1 (i INT, f FLOAT);
SET @@SESSION.session_track_schema=ON;
SET @@SESSION.session_track_system_variables='*';
-- Tracker : SESSION_TRACK_SYSTEM_VARIABLES
-- session_track_system_variables
-- *
SET @@SESSION.session_track_state_change=ON;
-- Tracker : SESSION_TRACK_SYSTEM_VARIABLES
-- session_track_state_change
-- ON
USE information_schema;
-- Tracker : SESSION_TRACK_SCHEMA
-- information_schema
-- Tracker : SESSION_TRACK_STATE_CHANGE
-- 1
SET NAMES 'utf8mb4';
-- Tracker : SESSION_TRACK_SYSTEM_VARIABLES
-- character_set_client
-- utf8mb4
-- character_set_connection
-- utf8mb4
-- character_set_results
-- utf8mb4
-- Tracker : SESSION_TRACK_STATE_CHANGE
-- 1
SET @@SESSION.session_track_transaction_info='CHARACTERISTICS';
-- Tracker : SESSION_TRACK_SYSTEM_VARIABLES
-- session_track_transaction_info
-- CHARACTERISTICS
-- Tracker : SESSION_TRACK_STATE_CHANGE
-- 1
-- Tracker : SESSION_TRACK_TRANSACTION_CHARACTERISTICS
--
-- Tracker : SESSION_TRACK_TRANSACTION_STATE
-- ________
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Tracker : SESSION_TRACK_TRANSACTION_CHARACTERISTICS
-- SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SET TRANSACTION READ WRITE;
-- Tracker : SESSION_TRACK_TRANSACTION_CHARACTERISTICS
-- SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; SET TRANSACTION READ WRITE;
START TRANSACTION;
-- Tracker : SESSION_TRACK_TRANSACTION_CHARACTERISTICS
-- SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; START TRANSACTION READ WRITE;
-- Tracker : SESSION_TRACK_TRANSACTION_STATE
-- T_______
SELECT 1;
1
1
-- Tracker : SESSION_TRACK_TRANSACTION_STATE
-- T_____S_
INSERT INTO test.t1 () VALUES();
-- Tracker : SESSION_TRACK_TRANSACTION_STATE
-- T___W_S_
INSERT INTO test.t1 () VALUES(1, RAND());
-- Tracker : SESSION_TRACK_TRANSACTION_STATE
-- T___WsS_
COMMIT;
-- Tracker : SESSION_TRACK_TRANSACTION_CHARACTERISTICS
--
-- Tracker : SESSION_TRACK_TRANSACTION_STATE
-- ________
ok
Preceding the START
TRANSACTION statement, two SET
TRANSACTION statements execute that set the isolation
level and access mode characteristics for the next transaction.
The SESSION_TRACK_TRANSACTION_CHARACTERISTICS
value indicates those next-transaction values that have been set.
Following the COMMIT statement that
ends the transaction, the
SESSION_TRACK_TRANSACTION_CHARACTERISTICS value
is reported as empty. This indicates that the next-transaction
characteristics that were set preceding the start of the
transaction have been reset, and that the session defaults apply.
To track changes to those session defaults, track the session
values of the
transaction_isolation and
transaction_read_only system
variables.
The server shutdown process takes place as follows:
The shutdown process is initiated.
This can occur initiated several ways. For example, a user with the
SHUTDOWNprivilege can execute a mysqladmin shutdown command. mysqladmin can be used on any platform supported by MySQL. Other operating system-specific shutdown initiation methods are possible as well: The server shuts down on Unix when it receives aSIGTERMsignal. A server running as a service on Windows shuts down when the services manager tells it to.The server creates a shutdown thread if necessary.
Depending on how shutdown was initiated, the server might create a thread to handle the shutdown process. If shutdown was requested by a client, a shutdown thread is created. If shutdown is the result of receiving a
SIGTERMsignal, the signal thread might handle shutdown itself, or it might create a separate thread to do so. If the server tries to create a shutdown thread and cannot (for example, if memory is exhausted), it issues a diagnostic message that appears in the error log:Error: Can't create thread to kill server
The server stops accepting new connections.
To prevent new activity from being initiated during shutdown, the server stops accepting new client connections by closing the handlers for the network interfaces to which it normally listens for connections: the TCP/IP port, the Unix socket file, the Windows named pipe, and shared memory on Windows.
The server terminates current activity.
For each thread associated with a client connection, the server breaks the connection to the client and marks the thread as killed. Threads die when they notice that they are so marked. Threads for idle connections die quickly. Threads that currently are processing statements check their state periodically and take longer to die. For additional information about thread termination, see Section 13.7.8.4, “KILL Statement”, in particular for the instructions about killed
REPAIR TABLEorOPTIMIZE TABLEoperations onMyISAMtables.For threads that have an open transaction, the transaction is rolled back. If a thread is updating a nontransactional table, an operation such as a multiple-row
UPDATEorINSERTmay leave the table partially updated because the operation can terminate before completion.If the server is a replication source server, it treats threads associated with currently connected replicas like other client threads. That is, each one is marked as killed and exits when it next checks its state.
If the server is a replica server, it stops the replication I/O and SQL threads, if they are active, before marking client threads as killed. The SQL thread is permitted to finish its current statement (to avoid causing replication problems), and then stops. If the SQL thread is in the middle of a transaction at this point, the server waits until the current replication event group (if any) has finished executing, or until the user issues a
KILL QUERYorKILL CONNECTIONstatement. See also Section 13.4.2.10, “STOP SLAVE | REPLICA Statement”. Since nontransactional statements cannot be rolled back, in order to guarantee crash-safe replication, only transactional tables should be used.NoteTo guarantee crash safety on the replica, you must run the replica with
--relay-log-recoveryenabled.See also Section 17.2.4, “Relay Log and Replication Metadata Repositories”).
The server shuts down or closes storage engines.
At this stage, the server flushes the table cache and closes all open tables.
Each storage engine performs any actions necessary for tables that it manages.
InnoDBflushes its buffer pool to disk (unlessinnodb_fast_shutdownis 2), writes the current LSN to the tablespace, and terminates its own internal threads.MyISAMflushes any pending index writes for a table.The server exits.
To provide information to management processes, the server returns one of the exit codes described in the following list. The phrase in parentheses indicates the action taken by systemd in response to the code, for platforms on which systemd is used to manage the server.
0 = successful termination (no restart done)
1 = unsuccessful termination (no restart done)
2 = unsuccessful termination (restart done)
Information managed by the MySQL server is stored under a directory known as the data directory. The following list briefly describes the items typically found in the data directory, with cross references for additional information:
Data directory subdirectories. Each subdirectory of the data directory is a database directory and corresponds to a database managed by the server. All MySQL installations have certain standard databases:
The
mysqldirectory corresponds to themysqlsystem schema, which contains information required by the MySQL server as it runs. This database contains data dictionary tables and system tables. See Section 5.3, “The mysql System Schema”.The
performance_schemadirectory corresponds to the Performance Schema, which provides information used to inspect the internal execution of the server at runtime. See Chapter 27, MySQL Performance Schema.The
sysdirectory corresponds to thesysschema, which provides a set of objects to help interpret Performance Schema information more easily. See Chapter 28, MySQL sys Schema.The
ndbinfodirectory corresponds to thendbinfodatabase that stores information specific to NDB Cluster (present only for installations built to include NDB Cluster). See Section 23.5.14, “ndbinfo: The NDB Cluster Information Database”.
Other subdirectories correspond to databases created by users or applications.
NoteINFORMATION_SCHEMAis a standard database, but its implementation uses no corresponding database directory.Log files written by the server. See Section 5.4, “MySQL Server Logs”.
InnoDBtablespace and log files. See Chapter 15, The InnoDB Storage Engine.Default/autogenerated SSL and RSA certificate and key files. See Section 6.3.3, “Creating SSL and RSA Certificates and Keys”.
The server process ID file (while the server is running).
The
mysqld-auto.cnffile that stores persisted global system variable settings. See Section 13.7.6.1, “SET Syntax for Variable Assignment”.
Some items in the preceding list can be relocated elsewhere by
reconfiguring the server. In addition, the
--datadir option enables the
location of the data directory itself to be changed. For a given
MySQL installation, check the server configuration to determine
whether items have been moved.
The mysql schema is the system schema. It
contains tables that store information required by the MySQL
server as it runs. A broad categorization is that the
mysql schema contains data dictionary tables
that store database object metadata, and system tables used for
other operational purposes. The following discussion further
subdivides the set of system tables into smaller categories.
The remainder of this section enumerates the tables in each
category, with cross references for additional information. Data
dictionary tables and system tables use the
InnoDB storage engine unless otherwise
indicated.
mysql system tables and data dictionary tables
reside in a single InnoDB tablespace file named
mysql.ibd in the MySQL data directory.
Previously, these tables were created in individual tablespace
files in the mysql database directory.
Data-at-rest encryption can be enabled for the
mysql system schema tablespace. For more
information, see Section 15.13, “InnoDB Data-at-Rest Encryption”.
These tables comprise the data dictionary, which contains metadata about database objects. For additional information, see Chapter 14, MySQL Data Dictionary.
The data dictionary is new in MySQL 8.0. A data dictionary-enabled server entails some general operational differences compared to previous MySQL releases. For details, see Section 14.7, “Data Dictionary Usage Differences”. Also, for upgrades to MySQL 8.0 from MySQL 5.7, the upgrade procedure differs somewhat from previous MySQL releases and requires that you verify the upgrade readiness of your installation by checking specific prerequisites. For more information, see Section 2.11, “Upgrading MySQL”, particularly Section 2.11.5, “Preparing Your Installation for Upgrade”.
catalogs: Catalog information.character_sets: Information about available character sets.check_constraints: Information aboutCHECKconstraints defined on tables. See Section 13.1.20.6, “CHECK Constraints”.collations: Information about collations for each character set.column_statistics: Histogram statistics for column values. See Section 8.9.6, “Optimizer Statistics”.column_type_elements: Information about types used by columns.columns: Information about columns in tables.dd_properties: A table that identifies data dictionary properties, such as its version. The server uses this to determine whether the data dictionary must be upgraded to a newer version.events: Information about Event Scheduler events. See Section 25.4, “Using the Event Scheduler”. If the server is started with the--skip-grant-tablesoption, the event scheduler is disabled and events registered in the table do not run. See Section 25.4.2, “Event Scheduler Configuration”.foreign_keys,foreign_key_column_usage: Information about foreign keys.index_column_usage: Information about columns used by indexes.index_partitions: Information about partitions used by indexes.index_stats: Used to store dynamic index statistics generated whenANALYZE TABLEis executed.indexes: Information about table indexes.innodb_ddl_log: Stores DDL logs for crash-safe DDL operations.parameter_type_elements: Information about stored procedure and function parameters, and about return values for stored functions.parameters: Information about stored procedures and functions. See Section 25.2, “Using Stored Routines”.resource_groups: Information about resource groups. See Section 5.1.16, “Resource Groups”.routines: Information about stored procedures and functions. See Section 25.2, “Using Stored Routines”.schemata: Information about schemata. In MySQL, a schema is a database, so this table provides information about databases.st_spatial_reference_systems: Information about available spatial reference systems for spatial data.table_partition_values: Information about values used by table partitions.table_partitions: Information about partitions used by tables.table_stats: Information about dynamic table statistics generated whenANALYZE TABLEis executed.tables: Information about tables in databases.tablespace_files: Information about files used by tablespaces.tablespaces: Information about active tablespaces.triggers: Information about triggers.view_routine_usage: Information about dependencies between views and stored functions used by them.view_table_usage: Used to track dependencies between views and their underlying tables.
Data dictionary tables are invisible. They cannot be read with
SELECT, do not appear in the
output of SHOW TABLES, are not
listed in the INFORMATION_SCHEMA.TABLES
table, and so forth. However, in most cases there are
corresponding INFORMATION_SCHEMA tables that
can be queried. Conceptually, the
INFORMATION_SCHEMA provides a view through
which MySQL exposes data dictionary metadata. For example, you
cannot select from the mysql.schemata table
directly:
mysql> SELECT * FROM mysql.schemata;
ERROR 3554 (HY000): Access to data dictionary table 'mysql.schemata' is rejected.
Instead, select that information from the corresponding
INFORMATION_SCHEMA table:
mysql> SELECT * FROM INFORMATION_SCHEMA.SCHEMATA\G
*************************** 1. row ***************************
CATALOG_NAME: def
SCHEMA_NAME: mysql
DEFAULT_CHARACTER_SET_NAME: utf8mb4
DEFAULT_COLLATION_NAME: utf8mb4_0900_ai_ci
SQL_PATH: NULL
DEFAULT_ENCRYPTION: NO
*************************** 2. row ***************************
CATALOG_NAME: def
SCHEMA_NAME: information_schema
DEFAULT_CHARACTER_SET_NAME: utf8
DEFAULT_COLLATION_NAME: utf8_general_ci
SQL_PATH: NULL
DEFAULT_ENCRYPTION: NO
...
There is no INFORMATION_SCHEMA table that
corresponds exactly to mysql.indexes, but
INFORMATION_SCHEMA.STATISTICS
contains much of the same information.
As of yet, there are no INFORMATION_SCHEMA
tables that correspond exactly to
mysql.foreign_keys,
mysql.foreign_key_column_usage. The standard
SQL way to obtain foreign key information is by using the
INFORMATION_SCHEMA
REFERENTIAL_CONSTRAINTS and
KEY_COLUMN_USAGE tables; these
tables are now implemented as views on the
foreign_keys,
foreign_key_column_usage, and other data
dictionary tables.
Some system tables from before MySQL 8.0 have been
replaced by data dictionary tables and are no longer present in
the mysql system schema:
The
eventsdata dictionary table supersedes theeventtable from before MySQL 8.0.The
parametersandroutinesdata dictionary tables together supersede theproctable from before MySQL 8.0.
These system tables contain grant information about user accounts and the privileges held by them. For additional information about the structure, contents, and purpose of the these tables, see Section 6.2.3, “Grant Tables”.
As of MySQL 8.0, the grant tables are InnoDB
(transactional) tables. Previously, these were
MyISAM (nontransactional) tables. The change
of grant-table storage engine underlies an accompanying change
in MySQL 8.0 to the behavior of account-management statements
such as CREATE USER and
GRANT. Previously, an
account-management statement that named multiple users could
succeed for some users and fail for others. The statements are
now transactional and either succeed for all named users or roll
back and have no effect if any error occurs.
If MySQL is upgraded from an older version but the grant
tables have not been upgraded from MyISAM
to InnoDB, the server considers them read
only and account-management statements produce an error. For
upgrade instructions, see Section 2.11, “Upgrading MySQL”.
user: User accounts, global privileges, and other nonprivilege columns.global_grants: Assignments of dynamic global privileges to users; see Static Versus Dynamic Privileges.db: Database-level privileges.tables_priv: Table-level privileges.columns_priv: Column-level privileges.procs_priv: Stored procedure and function privileges.proxies_priv: Proxy-user privileges.default_roles: This table lists default roles to be activated after a user connects and authenticates, or executesSET ROLE DEFAULT.role_edges: This table lists edges for role subgraphs.A given
usertable row might refer to a user account or a role. The server can distinquish whether a row represents a user account, a role, or both by consulting therole_edgestable for information about relations between authentication IDs.password_history: Information about password changes.
These system tables contain information about components, user-defined functions, and server-side plugins:
component: The registry for server components installed usingINSTALL COMPONENT. Any components listed in this table are installed by a loader service during the server startup sequence. See Section 5.5.1, “Installing and Uninstalling Components”.func: The registry for user-defined functions (UDFs) installed usingCREATE FUNCTION. During the normal startup sequence, the server loads UDFs registered in this table. If the server is started with the--skip-grant-tablesoption, UDFs registered in the table are not loaded and are unavailable. See Section 5.7.1, “Installing and Uninstalling User-Defined Functions”.NoteLike the
mysql.funcsystem table, the Performance Schemauser_defined_functionstable lists UDFs installed usingCREATE FUNCTION. Unlike themysql.functable, theuser_defined_functionstable also lists UDFs installed automatically by server components or plugins. This difference makesuser_defined_functionspreferable tomysql.funcfor checking which UDFs are installed. See Section 27.12.19.9, “The user_defined_functions Table”.plugin: The registry for server-side plugins installed usingINSTALL PLUGIN. During the normal startup sequence, the server loads plugins registered in this table. If the server is started with the--skip-grant-tablesoption, plugins registered in the table are not loaded and are unavailable. See Section 5.6.1, “Installing and Uninstalling Plugins”.
The server uses these system tables for logging:
Log tables use the CSV storage engine.
For more information, see Section 5.4, “MySQL Server Logs”.
These system tables contain server-side help information:
For more information, see Section 5.1.17, “Server-Side Help Support”.
These system tables contain time zone information:
For more information, see Section 5.1.15, “MySQL Server Time Zone Support”.
The server uses these system tables to support replication:
gtid_executed: Table for storing GTID values. See mysql.gtid_executed Table.ndb_binlog_index: Binary log information for NDB Cluster replication. This table is created only if the server is built withNDBCLUSTERsupport. See Section 23.6.4, “NDB Cluster Replication Schema and Tables”.slave_master_info,slave_relay_log_info,slave_worker_info: Used to store replication information on replica servers. See Section 17.2.4, “Relay Log and Replication Metadata Repositories”.
All of the tables just listed use the
InnoDB storage engine.
These system tables are for use by the optimizer:
innodb_index_stats,innodb_table_stats: Used forInnoDBpersistent optimizer statistics. See Section 15.8.10.1, “Configuring Persistent Optimizer Statistics Parameters”.server_cost,engine_cost: The optimizer cost model uses tables that contain cost estimate information about operations that occur during query execution.server_costcontains optimizer cost estimates for general server operations.engine_costcontains estimates for operations specific to particular storage engines. See Section 8.9.5, “The Optimizer Cost Model”.
Other system tables do not fit the preceding categories:
audit_log_filter,audit_log_user: If MySQL Enterprise Audit is installed, these tables provide persistent storage of audit log filter definitions and user accounts. See Audit Log Tables.firewall_users,firewall_whitelist: If MySQL Enterprise Firewall is installed, these tables provide persistent storage for information used by the firewall. See Section 6.4.7, “MySQL Enterprise Firewall”.servers: Used by theFEDERATEDstorage engine. See Section 16.8.2.2, “Creating a FEDERATED Table Using CREATE SERVER”.innodb_dynamic_metadata: Used by theInnoDBstorage engine to store fast-changing table metadata such as auto-increment counter values and index tree corruption flags. Replaces the data dictionary buffer table that resided in theInnoDBsystem tablespace.
MySQL Server has several logs that can help you find out what activity is taking place.
| Log Type | Information Written to Log |
|---|---|
| Error log | Problems encountered starting, running, or stopping mysqld |
| General query log | Established client connections and statements received from clients |
| Binary log | Statements that change data (also used for replication) |
| Relay log | Data changes received from a replication source server |
| Slow query log | Queries that took more than
long_query_time seconds to
execute |
| DDL log (metadata log) | Metadata operations performed by DDL statements |
By default, no logs are enabled, except the error log on Windows. (The DDL log is always created when required, and has no user-configurable options; see The DDL Log.) The following log-specific sections provide information about the server options that enable logging.
By default, the server writes files for all enabled logs in the data
directory. You can force the server to close and reopen the log
files (or in some cases switch to a new log file) by flushing the
logs. Log flushing occurs when you issue a
FLUSH LOGS statement; execute
mysqladmin with a flush-logs
or refresh argument; or execute
mysqldump with a
--flush-logs or
--master-data option. See
Section 13.7.8.3, “FLUSH Statement”, Section 4.5.2, “mysqladmin — A MySQL Server Administration Program”, and
Section 4.5.4, “mysqldump — A Database Backup Program”. In addition, the binary log is flushed
when its size reaches the value of the
max_binlog_size system variable.
You can control the general query and slow query logs during runtime. You can enable or disable logging, or change the log file name. You can tell the server to write general query and slow query entries to log tables, log files, or both. For details, see Section 5.4.1, “Selecting General Query Log and Slow Query Log Output Destinations”, Section 5.4.3, “The General Query Log”, and Section 5.4.5, “The Slow Query Log”.
The relay log is used only on replicas, to hold data changes from the replication source server that must also be made on the replica. For discussion of relay log contents and configuration, see Section 17.2.4.1, “The Relay Log”.
For information about log maintenance operations such as expiration of old log files, see Section 5.4.6, “Server Log Maintenance”.
For information about keeping logs secure, see Section 6.1.2.3, “Passwords and Logging”.
MySQL Server provides flexible control over the destination of
output written to the general query log and the slow query log, if
those logs are enabled. Possible destinations for log entries are
log files or the general_log and
slow_log tables in the mysql
system database. File output, table output, or both can be
selected.
The log_output system variable
specifies the destination for log output. Setting this variable
does not in itself enable the logs; they must be enabled
separately.
If
log_outputis not specified at startup, the default logging destination isFILE.If
log_outputis specified at startup, its value is a list one or more comma-separated words chosen fromTABLE(log to tables),FILE(log to files), orNONE(do not log to tables or files).NONE, if present, takes precedence over any other specifiers.
The general_log system variable
controls logging to the general query log for the selected log
destinations. If specified at server startup,
general_log takes an optional
argument of 1 or 0 to enable or disable the log. To specify a
file name other than the default for file logging, set the
general_log_file variable.
Similarly, the slow_query_log
variable controls logging to the slow query log for the selected
destinations and setting
slow_query_log_file specifies a
file name for file logging. If either log is enabled, the server
opens the corresponding log file and writes startup messages to
it. However, further logging of queries to the file does not
occur unless the FILE log destination is
selected.
Examples:
To write general query log entries to the log table and the log file, use
--log_output=TABLE,FILEto select both log destinations and--general_logto enable the general query log.To write general and slow query log entries only to the log tables, use
--log_output=TABLEto select tables as the log destination and--general_logand--slow_query_logto enable both logs.To write slow query log entries only to the log file, use
--log_output=FILEto select files as the log destination and--slow_query_logto enable the slow query log. In this case, because the default log destination isFILE, you could omit thelog_outputsetting.
The system variables associated with log tables and files enable runtime control over logging:
The
log_outputvariable indicates the current logging destination. It can be modified at runtime to change the destination.The
general_logandslow_query_logvariables indicate whether the general query log and slow query log are enabled (ON) or disabled (OFF). You can set these variables at runtime to control whether the logs are enabled.The
general_log_fileandslow_query_log_filevariables indicate the names of the general query log and slow query log files. You can set these variables at server startup or at runtime to change the names of the log files.To disable or enable general query logging for the current session, set the session
sql_log_offvariable toONorOFF. (This assumes that the general query log itself is enabled.)
The use of tables for log output offers the following benefits:
Log entries have a standard format. To display the current structure of the log tables, use these statements:
SHOW CREATE TABLE mysql.general_log; SHOW CREATE TABLE mysql.slow_log;
Log contents are accessible through SQL statements. This enables the use of queries that select only those log entries that satisfy specific criteria. For example, to select log contents associated with a particular client (which can be useful for identifying problematic queries from that client), it is easier to do this using a log table than a log file.
Logs are accessible remotely through any client that can connect to the server and issue queries (if the client has the appropriate log table privileges). It is not necessary to log in to the server host and directly access the file system.
The log table implementation has the following characteristics:
In general, the primary purpose of log tables is to provide an interface for users to observe the runtime execution of the server, not to interfere with its runtime execution.
CREATE TABLE,ALTER TABLE, andDROP TABLEare valid operations on a log table. ForALTER TABLEandDROP TABLE, the log table cannot be in use and must be disabled, as described later.By default, the log tables use the
CSVstorage engine that writes data in comma-separated values format. For users who have access to the.CSVfiles that contain log table data, the files are easy to import into other programs such as spreadsheets that can process CSV input.The log tables can be altered to use the
MyISAMstorage engine. You cannot useALTER TABLEto alter a log table that is in use. The log must be disabled first. No engines other thanCSVorMyISAMare legal for the log tables.Log Tables and “Too many open files” Errors. If you select
TABLEas a log destination and the log tables use theCSVstorage engine, you may find that disabling and enabling the general query log or slow query log repeatedly at runtime results in a number of open file descriptors for the.CSVfile, possibly resulting in a “Too many open files” error. To work around this issue, executeFLUSH TABLESor ensure that the value ofopen_files_limitis greater than the value oftable_open_cache_instances.To disable logging so that you can alter (or drop) a log table, you can use the following strategy. The example uses the general query log; the procedure for the slow query log is similar but uses the
slow_logtable andslow_query_logsystem variable.SET @old_log_state = @@GLOBAL.general_log; SET GLOBAL general_log = 'OFF'; ALTER TABLE mysql.general_log ENGINE = MyISAM; SET GLOBAL general_log = @old_log_state;
TRUNCATE TABLEis a valid operation on a log table. It can be used to expire log entries.RENAME TABLEis a valid operation on a log table. You can atomically rename a log table (to perform log rotation, for example) using the following strategy:USE mysql; DROP TABLE IF EXISTS general_log2; CREATE TABLE general_log2 LIKE general_log; RENAME TABLE general_log TO general_log_backup, general_log2 TO general_log;
CHECK TABLEis a valid operation on a log table.LOCK TABLEScannot be used on a log table.INSERT,DELETE, andUPDATEcannot be used on a log table. These operations are permitted only internally to the server itself.FLUSH TABLES WITH READ LOCKand the state of theread_onlysystem variable have no effect on log tables. The server can always write to the log tables.Entries written to the log tables are not written to the binary log and thus are not replicated to replicas.
To flush the log tables or log files, use
FLUSH TABLESorFLUSH LOGS, respectively.Partitioning of log tables is not permitted.
A mysqldump dump includes statements to recreate those tables so that they are not missing after reloading the dump file. Log table contents are not dumped.
- 5.4.2.1 Error Log Configuration
- 5.4.2.2 Default Error Log Destination Configuration
- 5.4.2.3 Error Event Fields
- 5.4.2.4 Types of Error Log Filtering
- 5.4.2.5 Priority-Based Error Log Filtering (log_filter_internal)
- 5.4.2.6 Rule-Based Error Log Filtering (log_filter_dragnet)
- 5.4.2.7 Error Logging in JSON Format
- 5.4.2.8 Error Logging to the System Log
- 5.4.2.9 Error Log Output Format
- 5.4.2.10 Error Log File Flushing and Renaming
This section discusses how to configure the MySQL server for logging of diagnostic messages to the error log. For information about selecting the error message character set and language, see Section 10.6, “Error Message Character Set”, and Section 10.12, “Setting the Error Message Language”.
The error log contains a record of mysqld startup and shutdown times. It also contains diagnostic messages such as errors, warnings, and notes that occur during server startup and shutdown, and while the server is running. For example, if mysqld notices that a table needs to be automatically checked or repaired, it writes a message to the error log.
Depending on error log configuration, error messages may also
populate the Performance Schema
error_log table, to provide an SQL
interface to the log and enable its contents to be queried. See
Section 27.12.19.1, “The error_log Table”.
On some operating systems, the error log contains a stack trace if mysqld exits abnormally. The trace can be used to determine where mysqld exited. See Section 5.9, “Debugging MySQL”.
If used to start mysqld,
mysqld_safe may write messages to the error
log. For example, when mysqld_safe notices
abnormal mysqld exits, it restarts
mysqld and writes a mysqld
restarted message to the error log.
The following sections discuss aspects of configuring error logging.
In MySQL 8.0, error logging uses the MySQL component architecture described at Section 5.5, “MySQL Components”. The error log subsystem consists of components that perform log event filtering and writing, as well as a system variable that configures which components to enable to achieve the desired logging result.
This section discusses how to select components for error logging. For instructions specific to log filters, see Section 5.4.2.4, “Types of Error Log Filtering”. For instructions specific to the JSON and system log sinks, see Section 5.4.2.7, “Error Logging in JSON Format”, and Section 5.4.2.8, “Error Logging to the System Log”. For additional details about all available log components, see Section 5.5.3, “Error Log Components”.
Component-based error logging offers these features:
Log events can be filtered by filter components to affect the information available for writing.
Log events are output by sink (writer) components. Multiple sink components can be enabled, to write error log output to multiple destinations.
Built-in filter and sink components combine to implement the default error log format.
A loadable sink enables logging in JSON format.
A loadable sink enables logging to the system log.
System variables control which log components to enable and how each component operates.
The log_error_services system
variable controls which log components to enable for error
logging. The variable may contain a list with 0, 1, or many
elements. In the latter case, elements may be delimited by
semicolon or (as of MySQL 8.0.12) comma, optionally followed by
space. A given setting cannot use both semicolon and comma
separators. Component order is significant because the server
executes components in the order listed.
By default, log_error_services
has this value:
mysql> SELECT @@GLOBAL.log_error_services;
+----------------------------------------+
| @@GLOBAL.log_error_services |
+----------------------------------------+
| log_filter_internal; log_sink_internal |
+----------------------------------------+
That value indicates that log events first pass through the
log_filter_internal filter component, then
through the log_sink_internal sink component,
both of which are built in. A filter modifies log events seen by
components named later in the
log_error_services value. A
sink is a destination for log events. Typically, a sink
processes log events into log messages that have a particular
format and writes these messages to its associated output, such
as a file or the system log.
The final component in the
log_error_services value
cannot be a filter. This is an error because any changes it
has on events would have no effect on output:
mysql> SET GLOBAL log_error_services = 'log_filter_internal';
ERROR 1231 (42000): Variable 'log_error_services' can't be set to the value
of 'log_filter_internal'
To correct the problem, include a sink at the end of the value:
mysql> SET GLOBAL log_error_services = 'log_filter_internal; log_sink_internal';
Query OK, 0 rows affected (0.00 sec)
The combination of log_filter_internal and
log_sink_internal implements the default
error log filtering and output behavior. The action of these
components is affected by other server options and system
variables:
The output destination is determined by the
--log-erroroption (and, on Windows,--pid-fileand--console). These determine whether to write error messages to the console or a file and, if to a file, the error log file name. See Section 5.4.2.2, “Default Error Log Destination Configuration”.The
log_error_verbosityandlog_error_suppression_listsystem variables affect which types of log eventslog_filter_internalpermits or suppresses. See Section 5.4.2.5, “Priority-Based Error Log Filtering (log_filter_internal)”.
To change the set of log components used for error logging, load
components as necessary, perform any component-specific
configuration, and modify the
log_error_services value.
Adding or removing log components is subject to these
constraints:
To add a log component to the list of enabled components:
Load the component using
INSTALL COMPONENT(unless it is built in or already loaded).If the component exposes any system variables that must be set for component initialization to succeed, assign those variables appropriate values.
Enable the component by listing it in the
log_error_servicesvalue.
For a component to be permitted in the
log_error_servicesvalue, it must be known. A component is known if it is built in, or if it is loadable and has been loaded usingINSTALL COMPONENT. Attempts to name an unknown component at server startup causelog_error_servicesto be set to its default value. Attempts to name an unknown component at runtime produce an error and thelog_error_servicesvalue remains unchanged.To disable a log component, remove it from the
log_error_servicesvalue. Then, if the component is loadable and you also want to unload it, useUNINSTALL COMPONENT.Attempts to use
UNINSTALL COMPONENTto unload a loadable component that is still named in thelog_error_servicesvalue produce an error.
For example, to use the system log sink
(log_sink_syseventlog) instead of the default
sink (log_sink_internal), first load the sink
component, then modify the
log_error_services value:
INSTALL COMPONENT 'file://component_log_sink_syseventlog'; SET GLOBAL log_error_services = 'log_filter_internal; log_sink_syseventlog';
The URN to use for loading a log component with
INSTALL COMPONENT is the
component name prefixed with
file://component_. For example, for the
log_sink_syseventlog component, the
corresponding URN is
file://component_log_sink_syseventlog.
It is possible to configure multiple log sinks, which enables
sending output to multiple destinations. To enable the system
log sink in addition to (rather than instead of) the default
sink, set the
log_error_services value like
this:
SET GLOBAL log_error_services = 'log_filter_internal; log_sink_internal; log_sink_syseventlog';
To revert to using only the default sink and unload the system log sink, execute these statements:
SET GLOBAL log_error_services = 'log_filter_internal; log_sink_internal; UNINSTALL COMPONENT 'file://component_log_sink_syseventlog';
To configure a log component to be enabled at each server startup, use this procedure:
If the component is loadable, load it at runtime using
INSTALL COMPONENT. Loading the component registers it in themysql.componentsystem table so that the server loads it automatically for subsequent startups.Set the
log_error_servicesvalue at startup to include the component name. Set the value either in the servermy.cnffile, or useSET PERSIST, which sets the value for the running MySQL instance and also saves the value to be used for subsequent server restarts; see Section 13.7.6.1, “SET Syntax for Variable Assignment”. A value set inmy.cnftakes effect at the next restart. A value set usingSET PERSISTtakes effect immediately, and for subsequent restarts.
Suppose that you want to configure, for every server startup,
use of the JSON log sink (log_sink_json) in
addition to the built-in log filter and sink
(log_filter_internal,
log_sink_internal). First load the JSON sink
if it is not loaded:
INSTALL COMPONENT 'file://component_log_sink_json';
Then set log_error_services to
take effect at server startup. You can set it in
my.cnf:
[mysqld] log_error_services='log_filter_internal; log_sink_internal; log_sink_json'
Or you can set it using
SET
PERSIST:
SET PERSIST log_error_services = 'log_filter_internal; log_sink_internal; log_sink_json';
The order of components named in
log_error_services is
significant, particularly with respect to the relative order of
filters and sinks. Consider this
log_error_services value:
log_filter_internal; log_sink_1; log_sink_2
In this case, log events pass to the built-in filter, then to the first sink, then to the second sink. Both sinks receive the filtered log events.
Compare that to this
log_error_services value:
log_sink_1; log_filter_internal; log_sink_2
In this case, log events pass to the first sink, then to the built-in filter, then to the second sink. The first sink receives unfiltered events. The second sink receives filtered events. You might configure error logging this way if you want one log that contains messages for all log events, and another log that contains messages only for a subset of log events.
If the enabled log components include a sink that provides
Performance Schema support, events written to the error log
are also written to the Performance Schema
error_log table. This enables
examining error log contents using SQL queries. Currently, the
traditional-format log_sink_internal and
JSON-format log_sink_json sinks support
this capability. See
Section 27.12.19.1, “The error_log Table”.
This section describes which server options configure the default error log destination, which can be the console or a named file. It also indicates which log sink components base their own output destination on the default destination.
In this discussion, “console” means
stderr, the standard error output. This is
your terminal or console window unless the standard error output
has been redirected to a different destination.
The server interprets options that determine the default error
log destination somewhat differently for Windows and Unix
systems. Be sure to configure the destination using the
information appropriate to your platform. After the server
interprets the default error log destination options, it sets
the log_error system variable
to indicate the default destination, which affects where several
log sink components write error messages. The following sections
address these topics.
On Windows, mysqld uses the
--log-error,
--pid-file, and
--console options to determine
whether the default error log destination is the console or a
file, and, if a file, the file name:
If
--consoleis given, the default destination is the console. (--consoletakes precedence over--log-errorif both are given, and the following items regarding--log-errordo not apply.)If
--log-erroris not given, or is given without naming a file, the default destination is a file namedhost_name.err--pid-fileoption is specified. In that case, the file name is the PID file base name with a suffix of.errin the data directory.If
--log-erroris given to name a file, the default destination is that file (with an.errsuffix added if the name has no suffix). The file location is under the data directory unless an absolute path name is given to specify a different location.
If the default error log destination is the console, the
server sets the log_error
system variable to stderr. Otherwise, the
default destination is a file and the server sets
log_error to the file name.
On Unix and Unix-like systems, mysqld uses
the --log-error option to
determine whether the default error log destination is the
console or a file, and, if a file, the file name:
If
--log-erroris not given, the default destination is the console.If
--log-erroris given without naming a file, the default destination is a file namedhost_name.errIf
--log-erroris given to name a file, the default destination is that file (with an.errsuffix added if the name has no suffix). The file location is under the data directory unless an absolute path name is given to specify a different location.If
--log-erroris given in an option file in a[mysqld],[server], or[mysqld_safe]section, on systems that use mysqld_safe to start the server, mysqld_safe finds and uses the option, and passes it to mysqld.
It is common for Yum or APT package installations to
configure an error log file location under
/var/log with an option like
log-error=/var/log/mysqld.log in a server
configuration file. Removing the path name from the option
causes the
host_name.err
If the default error log destination is the console, the
server sets the log_error
system variable to stderr. Otherwise, the
default destination is a file and the server sets
log_error to the file name.
After the server interprets the error log destination
configuration options, it sets the
log_error system variable to
indicate the default error log destination. Log sink
components may base their own output destination on the
log_error value, or determine
their destination independently of
log_error
If log_error is
stderr, the default error log destination
is the console, and log sinks that base their output
destination on the default destination also write to the
console:
log_sink_internal,log_sink_json,log_sink_test: These sinks write to the console. This is true even for sinks such aslog_sink_jsonthat can be enabled multiple times; all instances write to the console.log_sink_syseventlog: This sink writes to the system log, regardless of thelog_errorvalue.
If log_error is not
stderr, the default error log destination
is a file and log_error
indicates the file name. Log sinks that base their output
destination on the default destination base output file naming
on that file name. (A sink might use exactly that name, or it
might use some variant thereof.) Suppose that the
log_error value
file_name. Then log sinks use the
name like this:
log_sink_internal,log_sink_test: These sinks write tofile_name.log_sink_json: Successive instances of this sink named in thelog_error_servicesvalue write to files namedfile_nameplus a numbered.suffix:NN.jsonfile_name.00.jsonfile_name.01.jsonlog_sink_syseventlog: This sink writes to the system log, regardless of thelog_errorvalue.
Error events intended for the error log contain a set of fields, each of which consists of a key/value pair. An event field may be classified as core, optional, or user-defined:
A core field is set up automatically for error events. However, its presence in the event during event processing is not guaranteed because a core field, like any type of field, may be unset by a log filter. If this happens, the field cannot be found by subsequent processing within that filter and by components that execute after the filter (such as log sinks).
An optional field is normally absent but may be present for certain event types. When present, an optional field provides additional event information as appropriate and available.
A user-defined field is any field with a name that is not already defined as a core or optional field. A user-defined field does not exist until created by a log filter.
As implied by the preceding description, any given field may be absent during event processing, either because it was not present in the first place, or was discarded by a filter. For log sinks, the effect of field absence is sink specific. For example, a sink might omit the field from the log message, indicate that the field is missing, or substitute a default. When in doubt, test: use a filter that unsets the field, then check what the log sink does with it.
The following sections describe the core and optional error event fields. For individual log filter components, there may be additional filter-specific considerations for these fields, or filters may add user-defined fields not listed here. For details, see the documentation for specific filters.
These error event fields are core fields:
timeThe event timestamp, with microsecond precision.
msgThe event message string.
prioThe event priority, to indicate a system, error, warning, or note/information event. This field corresponds to severity in
syslog. The following table shows the possible priority levels.Event Type Numeric Priority System event 0 Error event 1 Warning event 2 Note/information event 3 The
priovalue is numeric. Related to it, an error event may also include an optionallabelfield representing the priority as a string. For example, an event with apriovalue of 2 may have alabelvalue of'Warning'.Filter components may include or drop error events based on priority, except that system events are mandatory and cannot be dropped.
In general, message priorities are determined as follows:
Is the situation or event actionable?
Yes: Is the situation or event ignorable?
Yes: Priority is warning.
No: Priority is error.
No: Is the situation or event mandatory?
Yes: Priority is system.
No: Priority is note/information.
err_codeThe event error code, as a number (for example,
1022).err_symbolThe event error symbol, as a string (for example,
'ER_DUP_KEY').SQL_stateThe event SQLSTATE value, as a string (for example,
'23000').subsystemThe subsystem in which the event occurred. Possible values are
InnoDB(theInnoDBstorage engine),Repl(the replication subsystem),Server(otherwise).
Optional error event fields fall into the following categories:
Additional information about the error, such as the error signaled by the operating system or the error lable:
OS_errnoThe operating system error number.
OS_errmsgThe operating system error message.
labelThe label corresponding to the
priovalue, as a string.
Identification of the client for which the event occurred:
userThe client user.
hostThe client host.
threadThe ID of the thread within mysqld responsible for producing the error event. This ID indicates which part of the server produced the event, and is consistent with general query log and slow query log messages, which include the connection thread ID.
query_idThe query ID.
Debugging information:
source_fileThe source file in which the event occurred, without any leading path.
source_lineThe line within the source file at which the event occurred.
functionThe function in which the event occurred.
componentThe component or plugin in which the event occurred.
Error log configuration normally includes one log filter component and one or more log sink components. For error log filtering, MySQL offers a choice of components:
log_filter_internal: This filter component provides error log filtering based on log event priority and error code, in combination with thelog_error_verbosityandlog_error_suppression_listsystem variables.log_filter_internalis built in and enabled by default. See Section 5.4.2.5, “Priority-Based Error Log Filtering (log_filter_internal)”.log_filter_dragnet: This filter component provides error log filtering based on user-supplied rules, in combination with thedragnet.log_error_filter_rulessystem variable. See Section 5.4.2.6, “Rule-Based Error Log Filtering (log_filter_dragnet)”.
The log_filter_internal log filter component
implements a simple form of log filtering based on error event
priority and error code. To affect how
log_filter_internal permits or suppresses
error, warning, and information events intended for the error
log, set the
log_error_verbosity and
log_error_suppression_list
system variables.
log_filter_internal is built in and enabled
by default. If this filter is disabled,
log_error_verbosity and
log_error_suppression_list have
no effect, so filtering must be performed using another filter
service instead where desired (for example, with individual
filter rules when using log_filter_dragnet).
For information about filter configuration, see
Section 5.4.2.1, “Error Log Configuration”.
Events intended for the error log have a priority of
ERROR, WARNING, or
INFORMATION. The
log_error_verbosity system
variable controls verbosity based on which priorities to
permit for messages written to the log, as shown in the
following table.
| log_error_verbosity Value | Permitted Message Priorities |
|---|---|
| 1 | ERROR |
| 2 | ERROR, WARNING |
| 3 | ERROR, WARNING,
INFORMATION |
If log_error_verbosity is 2
or greater, the server logs messages about statements that are
unsafe for statement-based logging. If the value is 3, the
server logs aborted connections and access-denied errors for
new connection attempts. See
Section B.3.2.9, “Communication Errors and Aborted Connections”.
If you use replication, a
log_error_verbosity value of
2 or greater is recommended, to obtain more information about
what is happening, such as messages about network failures and
reconnections.
If log_error_verbosity is 2
or greater on a replica, the replica prints messages to the
error log to provide information about its status, such as the
binary log and relay log coordinates where it starts its job,
when it is switching to another relay log, when it reconnects
after a disconnect, and so forth.
There is also a message priority of SYSTEM
that is not subject to verbosity filtering. System messages
about non-error situations are printed to the error log
regardless of the
log_error_verbosity value.
These messages include startup and shutdown messages, and some
significant changes to settings.
In the MySQL error log, system messages are labeled as “System”. Other log sinks might or might not follow the same convention, and in the resulting logs, system messages might be assigned the label used for the information priority level, such as “Note” or “Information”. If you apply any additional filtering or redirection for logging based on the labeling of messages, system messages do not override your filter, but are handled by it in the same way as other messages.
The
log_error_suppression_list
system variable applies to events intended for the error log
and specifies which events to suppress when they occur with a
priority of WARNING or
INFORMATION. For example, if a particular
type of warning is considered undesirable “noise”
in the error log because it occurs frequently but is not of
interest, it can be suppressed.
log_error_suppression_list
does not suppress messages with a priority of
ERROR or SYSTEM.
The
log_error_suppression_list
value may be the empty string for no suppression, or a list of
one or more comma-separated values indicating the error codes
to suppress. Error codes may be specified in symbolic or
numeric form. A numeric code may be specified with or without
the MY- prefix. Leading zeros in the
numeric part are not significant. Examples of permitted code
formats:
ER_SERVER_SHUTDOWN_COMPLETE MY-000031 000031 MY-31 31
For readability and portability, symbolic values are preferable to numeric values.
Although codes to be suppressed can be expressed in symbolic or numeric form, the numeric value of each code must be in a permitted range:
1 to 999: Global error codes that are used by the server as well as by clients.
10000 and higher: Server error codes intended to be written to the error log (not sent to clients).
In addition, each error code specified must actually be used
by MySQL. Attempts to specify a code not within a permitted
range or within a permitted range but not used by MySQL
produce an error and the
log_error_suppression_list
value remains unchanged.
For information about error code ranges and the error symbols and numbers defined within each range, see Section B.1, “Error Message Sources and Elements”, and MySQL 8.0 Error Message Reference.
The server can generate messages for a given error code at
differing priorities, so suppression of a message associated
with an error code listed in
log_error_suppression_list
depends on its priority. Suppose that the variable has a value
of 'ER_PARSER_TRACE,MY-010001,10002'. Then
log_error_suppression_list
has these effects on messages for those codes:
Messages generated with a priority of
WARNINGorINFORMATIONare suppressed.Messages generated with a priority of
ERRORorSYSTEMare not suppressed.
The effect of
log_error_verbosity combines
with that of
log_error_suppression_list.
Consider a server started with these settings:
[mysqld] log_error_verbosity=2 # error and warning messages only log_error_suppression_list='ER_PARSER_TRACE,MY-010001,10002'
In this case,
log_error_verbosity permits
messages with ERROR or
WARNING priority and discards messages with
INFORMATION priority. Of the nondiscarded
messages,
log_error_suppression_list
discards messages with WARNING priority and
any of the named error codes.
The log_error_verbosity
value of 2 shown in the example is also its default value,
so the effect of this variable on
INFORMATION messages is as just described
by default, without an explicit setting. You must set
log_error_verbosity to 3 if
you want
log_error_suppression_list
to affect messages with INFORMATION
priority.
Consider a server started with this setting:
[mysqld] log_error_verbosity=1 # error messages only
In this case,
log_error_verbosity permits
messages with ERROR priority and discards
messages with WARNING or
INFORMATION priority. Setting
log_error_suppression_list
has no effect because all error codes it might suppress are
already discarded due to the
log_error_verbosity setting.
The log_filter_dragnet log filter component
enables log filtering based on user-defined rules.
To enable the log_filter_dragnet filter,
first load the filter component, then modify the
log_error_services value. The
following example enables log_filter_dragnet
in combination with the built-in log sink:
INSTALL COMPONENT 'file://component_log_filter_dragnet'; SET GLOBAL log_error_services = 'log_filter_dragnet; log_sink_internal';
To set log_error_services to
take effect at server startup, use the instructions at
Section 5.4.2.1, “Error Log Configuration”. Those instructions
apply to other error-logging system variables as well.
With log_filter_dragnet enabled, define its
filter rules by setting the
dragnet.log_error_filter_rules
system variable. A rule set consists of zero or more rules,
where each rule is an IF statement terminated
by a period (.) character. If the variable
value is empty (zero rules), no filtering occurs.
Example 1. This rule set drops information events, and, for
other events, removes the source_line field:
SET GLOBAL dragnet.log_error_filter_rules = 'IF prio>=INFORMATION THEN drop. IF EXISTS source_line THEN unset source_line.';
The effect is similar to the filtering performed by the
log_sink_internal filter with a setting of
log_error_verbosity=2.
For readability, you might find it preferable to list the rules on separate lines. For example:
SET GLOBAL dragnet.log_error_filter_rules = ' IF prio>=INFORMATION THEN drop. IF EXISTS source_line THEN unset source_line. ';
Example 2: This rule limits information events to no more than one per 60 seconds:
SET GLOBAL dragnet.log_error_filter_rules = 'IF prio>=INFORMATION THEN throttle 1/60.';
Once you have the filtering configuration set up as you desire,
consider assigning
dragnet.log_error_filter_rules
using SET
PERSIST rather than
SET
GLOBAL to make the setting persist across server
restarts. Alternatively, add the setting to the server option
file.
To stop using the filtering language, first remove it from the set of error logging components. Usually this means using a different filter component rather than no filter component. For example:
SET GLOBAL log_error_services = 'log_filter_internal; log_sink_internal';
Again, consider using using
SET
PERSIST rather than
SET
GLOBAL to make the setting persist across server
restarts.
Then uninstall the filter log_filter_dragnet
component:
UNINSTALL COMPONENT 'file://component_log_filter_dragnet';
The following sections describe aspects of
log_filter_dragnet operation in more detail:
The following grammar defines the language for
log_filter_dragnet filter rules. Each rule
is an IF statement terminated by a period
(.) character. The language is not
case-sensitive.
rule: IFconditionTHENaction[ELSEIFconditionTHENaction] ... [ELSEaction] .condition: {fieldcomparatorvalue| [NOT] EXISTSfield|condition{AND | OR}condition}action: { drop | throttle {count|count/window_size} | setfield[:= | =]value| unset [field] }field: {core_field|optional_field|user_defined_field}core_field: { time | msg | prio | err_code | err_symbol | SQL_state | subsystem }optional_field: { OS_errno | OS_errmsg | label | user | host | thread | query_id | source_file | source_line | function | component }user_defined_field:sequence of characters in [a-zA-Z0-9_] classcomparator: {== | != | <> | >= | => | <= | =< | < | >}value: {string_literal|integer_literal|float_literal|error_symbol|priority}count:integer_literalwindow_size:integer_literalstring_literal:sequence of characters quoted as '...' or "..."integer_literal:sequence of characters in [0-9] classfloat_literal:integer_literal[.integer_literal]error_symbol:valid MySQL error symbol such as ER_ACCESS_DENIED_ERROR or ER_STARTUPpriority: { ERROR | WARNING | INFORMATION }
Simple conditions compare a field to a value or test field
existence. To construct more complex conditions, use the
AND and OR operators.
Both operators have the same precedence and evaluate left to
right.
To escape a character within a string, precede it by a
backslash (\). A backslash is required to
include backslash itself or the string-quoting character,
optional for other characters.
For convenience, log_filter_dragnet
supports symbolic names for comparisons to certain fields. For
readability and portability, symbolic values are preferable
(where applicable) to numeric values.
Event priority values 1, 2, and 3 can be specified as
ERROR,WARNING, andINFORMATION. Priority symbols are recognized only in comparisons with thepriofield. These comparisons are equivalent:IF prio == INFORMATION THEN ... IF prio == 3 THEN ...
Error codes can be specified in numeric form or as the corresponding error symbol. For example,
ER_STARTUPis the symbolic name for error1408, so these comparisons are equivalent:IF err_code == ER_STARTUP THEN ... IF err_code == 1408 THEN ...
Error symbols are recognized only in comparisons with the
err_codefield and user-defined fields.To find the error symbol corresponding to a given error code number, use one of these methods:
Check the list of server errors at Server Error Message Reference.
Use the perror command. Given an error number argument, perror displays information about the error, including its symbol.
Suppose that a rule set with error numbers looks like this:
IF err_code == 10927 OR err_code == 10914 THEN drop. IF err_code == 1131 THEN drop.
Using perror, determine the error symbols:
shell>
perror 10927 10914 1131MySQL error code MY-010927 (ER_ACCESS_DENIED_FOR_USER_ACCOUNT_LOCKED): Access denied for user '%-.48s'@'%-.64s'. Account is locked. MySQL error code MY-010914 (ER_ABORTING_USER_CONNECTION): Aborted connection %u to db: '%-.192s' user: '%-.48s' host: '%-.64s' (%-.64s). MySQL error code MY-001131 (ER_PASSWORD_ANONYMOUS_USER): You are using MySQL as an anonymous user and anonymous users are not allowed to change passwordsSubstituting error symbols for numbers, the rule set becomes:
IF err_code == ER_ACCESS_DENIED_FOR_USER_ACCOUNT_LOCKED OR err_code == ER_ABORTING_USER_CONNECTION THEN drop. IF err_code == ER_PASSWORD_ANONYMOUS_USER THEN drop.
Symbolic names can be specified as quoted strings for
comparison with string fields, but in such cases the names are
strings that have no special meaning and
log_filter_dragnet does not resolve them to
the corresponding numeric value. Also, typos may go
undetected, whereas an error occurs immediately on
SET for attempts to use an unquoted symbol
unknown to the server.
log_filter_dragnet supports these actions
in filter rules:
drop: Drop the current log event (do not log it).throttle: Apply rate limiting to reduce log verbosity for events matching particular conditions. The argument indicates a rate, in the formcountorcount/window_size. Thecountvalue indicates the permitted number of event occurrences to log per time window. Thewindow_sizevalue is the time window in seconds; if omitted, the default window is 60 seconds. Both values must be integer literals.This rule throttles plugin-shutdown messages to 5 occurrences per 60 seconds:
IF err_code == ER_PLUGIN_SHUTTING_DOWN_PLUGIN THEN throttle 5.
This rule throttles errors and warnings to 1000 occurrences per hour and information messages to 100 occurrences per hour:
IF prio <= INFORMATION THEN throttle 1000/3600 ELSE throttle 100/3600.
set: Assign a value to a field (and cause the field to exist if it did not already). In subsequent rules,EXISTStests against the field name are true, and the new value can be tested by comparison conditions.unset: Discard a field. In subsequent rules,EXISTStests against the field name are false, and comparisons of the field against any value are false.In the special case that the condition refers to exactly one field name, the field name following
unsetis optional andunsetdiscards the named field. These rules are equivalent:IF myfield == 2 THEN unset myfield. IF myfield == 2 THEN unset.
log_filter_dragnet rules support references
to core, optional, and user-defined fields in error events.
Core Field References
The log_filter_dragnet grammar at
Grammar for log_filter_dragnet Rule Language names
the core fields that filter rules recognize. For general
descriptions of these fields, see
Section 5.4.2.3, “Error Event Fields”, with which you are
assumed to be familiar. The following remarks provide
additional information only as it pertains specifically to
core field references as used within
log_filter_dragnet rules.
prioThe event priority, to indicate an error, warning, or note/information event. In comparisons, each priority can be specified as a symbolic priority name or an integer literal. Priority symbols are recognized only in comparisons with the
priofield. These comparisons are equivalent:IF prio == INFORMATION THEN ... IF prio == 3 THEN ...
The following table shows the permitted priority levels.
Event Type Priority Symbol Numeric Priority Error event ERROR1 Warning event WARNING2 Note/information event INFORMATION3 There is also a message priority of
SYSTEM, but system messages cannot be filtered and are always written to the error log.Priority values follow the principle that higher priorities have lower values, and vice versa. Priority values begin at 1 for the most severe events (errors) and increase for events with decreasing priority. For example, to discard events with priority lower than warnings, test for priority values higher than
WARNING:IF prio > WARNING THEN drop.
The following examples show the
log_filter_dragnetrules to achieve an effect similar to eachlog_error_verbosityvalue permitted by thelog_filter_internalfilter:Errors only (
log_error_verbosity=1):IF prio > ERROR THEN drop.
Errors and warnings (
log_error_verbosity=2):IF prio > WARNING THEN drop.
Errors, warnings, and notes (
log_error_verbosity=3):IF prio > INFORMATION THEN drop.
This rule can actually be omitted because there are no
priovalues greater thanINFORMATION, so effectively it drops nothing.
err_codeThe numeric event error code. In comparisons, the value to test can be specified as a symbolic error name or an integer literal. Error symbols are recognized only in comparisons with the
err_codefield and user-defined fields. These comparisons are equivalent:IF err_code == ER_ACCESS_DENIED_ERROR THEN ... IF err_code == 1045 THEN ...
err_symbolThe event error symbol, as a string (for example,
'ER_DUP_KEY').err_symbolvalues are intended more for identifying particular lines in log output than for use in filter rule comparisons becauselog_filter_dragnetdoes not resolve comparison values specified as strings to the equivalent numeric error code. (For that to occur, an error must be specified using its unquoted symbol.)
Optional Field References
The log_filter_dragnet grammar at
Grammar for log_filter_dragnet Rule Language names
the optional fields that filter rules recognize. For general
descriptions of these fields, see
Section 5.4.2.3, “Error Event Fields”, with which you are
assumed to be familiar. The following remarks provide
additional information only as it pertains specifically to
optional field references as used within
log_filter_dragnet rules.
labelThe label corresponding to the
priovalue, as a string. Filter rules can change the label for log sinks that support custom labels.labelvalues are intended more for identifying particular lines in log output than for use in filter rule comparisons becauselog_filter_dragnetdoes not resolve comparison values specified as strings to the equivalent numeric priority.source_fileThe source file in which the event occurred, without any leading path. For example, to test for the
sql/gis/distance.ccfile, write the comparison like this:IF source_file == "distance.cc" THEN ...
User-Defined Field References
Any field name in a log_filter_dragnet
filter rule not recognized as a core or optional field name is
taken to refer to a user-defined field.
This section describes how to configure error logging using the
built-in filter, log_filter_internal, and the
JSON sink, log_sink_json, to take effect
immediately and for subsequent server startups. For general
information about configuring error logging, see
Section 5.4.2.1, “Error Log Configuration”.
To enable the JSON sink, first load the sink component, then
modify the log_error_services
value:
INSTALL COMPONENT 'file://component_log_sink_json'; SET PERSIST log_error_services = 'log_filter_internal; log_sink_json';
To set log_error_services to
take effect at server startup, use the instructions at
Section 5.4.2.1, “Error Log Configuration”. Those instructions
apply to other error-logging system variables as well.
It is permitted to name log_sink_json
multiple times in the
log_error_services value. For
example, to write unfiltered events with one instance and
filtered events with another instance, you could set
log_error_services like this:
SET PERSIST log_error_services = 'log_sink_json; log_filter_internal; log_sink_json';
The JSON sink determines its output destination based on the
default error log destination, which is given by the
log_error system variable. If
log_error names a file, the
JSON sink bases output file naming on that file name, plus a
numbered
. suffix,
with NN.jsonNN starting at 00. For example,
if log_error is
file_name, successive instances of
log_sink_json named in the
log_error_services value write
to
file_name.00.jsonfile_name.01.json
If log_error is
stderr, the JSON sink writes to the console.
If log_sink_json is named multiple times in
the log_error_services value,
they all write to the console, which is likely not useful.
It is possible to have mysqld write the error
log to the system log (the Event Log on Windows, and
syslog on Unix and Unix-like systems).
This section describes how to configure error logging using the
built-in filter, log_filter_internal, and the
system log sink, log_sink_syseventlog, to
take effect immediately and for subsequent server startups. For
general information about configuring error logging, see
Section 5.4.2.1, “Error Log Configuration”.
To enable the system log sink, first load the sink component,
then modify the
log_error_services value:
INSTALL COMPONENT 'file://component_log_sink_syseventlog'; SET PERSIST log_error_services = 'log_filter_internal; log_sink_syseventlog';
To set log_error_services to
take effect at server startup, use the instructions at
Section 5.4.2.1, “Error Log Configuration”. Those instructions
apply to other error-logging system variables as well.
For MySQL 8.0 configuration, you must enable error logging to the system log explicitly. This differs from MySQL 5.7 and earlier, for which error logging to the system log is enabled by default on Windows, and on all platforms requires no component loading.
Error logging to the system log may require additional system configuration. Consult the system log documentation for your platform.
On Windows, error messages written to the Event Log within the Application log have these characteristics:
Entries marked as
Error,Warning, andNoteare written to the Event Log, but not messages such as information statements from individual storage engines.Event Log entries have a source of
MySQL(orMySQL-iftagsyseventlog.tagis defined astag).
On Unix and Unix-like systems, logging to the system log uses
syslog. The following system variables affect
syslog messages:
syseventlog.facility: The default facility forsyslogmessages isdaemon. Set this variable to specify a different facility.syseventlog.include_pid: Whether to include the server process ID in each line ofsyslogoutput.syseventlog.tag: This variable defines a tag to add to the server identifier (mysqld) insyslogmessages. If defined, the tag is appended to the identifier with a leading hyphen.
Prior to MySQL 8.0.13, use the
log_syslog_facility,
log_syslog_include_pid, and
log_syslog_tag system
variables rather than the
syseventlog.
variables.
xxx
MySQL uses the custom label “System” for important
system messages about non-error situations, such as startup,
shutdown, and some significant changes to settings. In logs that
do not support custom labels, including the Event Log on
Windows, and syslog on Unix and Unix-like
systems, system messages are assigned the label used for the
information priority level. However, these messages are printed
to the log even if the MySQL
log_error_verbosity setting
normally excludes messages at the information level.
When a log sink must fall back to a label of
“Information” instead of “System” in
this way, and the log event is further processed outside of the
MySQL server (for example, filtered or forwarded by a
syslog configuration), these events may by
default be processed by the secondary application as being of
“Information” priority rather than
“System” priority.
Each error log sink (writer) component has a characteristic output format it uses to write messages to its destination, but other factors may influence the content of the messages:
The information available to the log sink. If a log filter component executed prior to execution of the sink component removes a log event field, that field is not available for writing. For information about log filtering, see Section 5.4.2.4, “Types of Error Log Filtering”.
The information relevant to the log sink. Not every sink writes all fields available in error events.
System variables may affect log sinks. See System Variables That Affect Error Log Format.
For names and descriptions of the fields in error events, see Section 5.4.2.3, “Error Event Fields”. For all log sinks, the thread ID included in error log messages is that of the thread within mysqld responsible for writing the message. This ID indicates which part of the server produced the message, and is consistent with general query log and slow query log messages, which include the connection thread ID.
The internal log sink produces traditional error log output. For example:
2020-08-06T14:25:02.835618Z 0 [Note] [MY-012487] [InnoDB] DDL log recovery : begin 2020-08-06T14:25:02.936146Z 0 [Warning] [MY-010068] [Server] CA certificate /var/mysql/sslinfo/cacert.pem is self signed. 2020-08-06T14:25:02.963127Z 0 [Note] [MY-010253] [Server] IPv6 is available. 2020-08-06T14:25:03.109022Z 5 [Note] [MY-010051] [Server] Event Scheduler: scheduler thread started with id 5
Traditional-format messages have these fields:
time thread [label] [err_code] [subsystem] msg
The [ and ] square
bracket characters are literal characters in the message
format. They do not indicate that fields are optional.
The label value corresponds to the string
form of the prio error event priority
field.
The [err_code] and
[subsystem] fields were added in MySQL 8.0.
They are missing from logs generated by older servers. Log
parsers can treat these fields as parts of the message text
that is present only for logs written by servers recent enough
to include them. Parsers must treat the
err_code part of
[err_code] indicators as a string value,
not a number, because values such as
MY-012487 and MY-010051
contain nonnumeric characters.
The JSON-format log sink produces messages as JSON objects that contain key-value pairs. For example:
{
"prio": 3,
"err_code": 10051,
"source_line": 561,
"source_file": "event_scheduler.cc",
"function": "run",
"msg": "Event Scheduler: scheduler thread started with id 5",
"time": "2020-08-06T14:25:03.109022Z",
"ts": 1596724012005,
"thread": 5,
"err_symbol": "ER_SCHEDULER_STARTED",
"SQL_state": "HY000",
"subsystem": "Server",
"buffered": 1596723903109022,
"label": "Note"
}
The message shown is reformatted for readability. Events written to the error log appear one message per line.
The ts (timestamp) key was added in MySQL
8.0.20 and is unique to the JSON-format log sink. The value is
an integer indicating milliseconds since the epoch
('1970-01-01 00:00:00' UTC).
The ts and buffered
values are Unix timestamp values and can be converted using
FROM_UNIXTIME() and an
appropriate divisor:
mysql>SET time_zone = '+00:00';mysql>SELECT FROM_UNIXTIME(1596724012005/1000.0);+-------------------------------------+ | FROM_UNIXTIME(1596724012005/1000.0) | +-------------------------------------+ | 2020-08-06 14:26:52.0050 | +-------------------------------------+ mysql>SELECT FROM_UNIXTIME(1596723903109022/1000000.0);+-------------------------------------------+ | FROM_UNIXTIME(1596723903109022/1000000.0) | +-------------------------------------------+ | 2020-08-06 14:25:03.1090 | +-------------------------------------------+
The system log sink produces output that conforms to the system log format used on the local platform.
The server generates some error log messages before startup
options have been processed, and thus before it knows error
log settings such as the
log_error_verbosity and
log_timestamps system
variable values, and before it knows which log components are
to be used. The server handles error log messages that are
generated early in the startup process as follows:
Prior to MySQL 8.0.14, the server generates messages with the default timestamp, format, and verbosity level, and buffers them. After the startup options are processed and the error log configuration is known, the server flushes the buffered messages. Because these early messages use the default log configuration, they may differ from what is specified by the startup options. Also, the early messages are not flushed to log sinks other than the default. For example, logging to the JSON sink does not include these early messages because they are not in JSON format.
As of MySQL 8.0.14, the server buffers log events rather than formatted log messages. This enables it to retroactively apply configuration settings to those events after the settings are known, with the result that flushed messages use the configured settings, not the defaults. Also, messages are flushed to all configured sinks, not just the default sink.
If a fatal error occurs before log configuration is known and the server must exit, the server formats buffered messages using the logging defaults so they are not lost. If no fatal error occurs but startup is excessively slow prior to processing startup options, the server periodically formats and flushes buffered messages using the logging defaults so as not to appear unresponsive. Although this behavior is similar to pre-8.0.14 behavior in that the defaults are used, it is preferable to losing messages when exceptional conditions occur.
The log_timestamps system
variable controls the time zone of timestamps in messages
written to the error log (as well as to general query log and
slow query log files). The server applies
log_timestamps to error
events before they reach any log sink; it thus affects error
message output from all sinks.
Permitted log_timestamps
values are UTC (the default) and
SYSTEM (the local system time zone).
Timestamps are written using ISO 8601 / RFC 3339 format:
YYYY-MM-DDThh:mm:ss.uuuuuuZ signifying Zulu time
(UTC) or ±hh:mm (an offset that
indicates the local system time zone adjustment relative to
UTC). For example:
2020-08-07T15:02:00.832521Z (UTC) 2020-08-07T10:02:00.832521-05:00 (SYSTEM)
If you flush the error log using a FLUSH
ERROR LOGS or FLUSH
LOGS statment, or a mysqladmin
flush-logs command, the server closes and reopens any
error log file to which it is writing. To rename an error log
file, do so manually before flushing. Flushing the logs then
opens a new file with the original file name. For example,
assuming a log file name of
host_name.err
mvhost_name.errhost_name.err-old mysqladmin flush-logs mvhost_name.err-oldbackup-directory
On Windows, use rename rather than mv.
If the location of the error log file is not writable by the
server, the log-flushing operation fails to create a new log
file. For example, on Linux, the server might write the error
log to the /var/log/mysqld.log file, where
the /var/log directory is owned by
root and is not writable by
mysqld. For information about handling this
case, see Section 5.4.6, “Server Log Maintenance”.
If the server is not writing to a named error log file, no error log file renaming occurs when the error log is flushed.
The general query log is a general record of what mysqld is doing. The server writes information to this log when clients connect or disconnect, and it logs each SQL statement received from clients. The general query log can be very useful when you suspect an error in a client and want to know exactly what the client sent to mysqld.
Each line that shows when a client connects also includes
using
to indicate
the protocol used to establish the connection.
connection_typeconnection_type is one of
TCP/IP (TCP/IP connection established without
SSL), SSL/TLS (TCP/IP connection established
with SSL), Socket (Unix socket file
connection), Named Pipe (Windows named pipe
connection), or Shared Memory (Windows shared
memory connection).
mysqld writes statements to the query log in the order that it receives them, which might differ from the order in which they are executed. This logging order is in contrast with that of the binary log, for which statements are written after they are executed but before any locks are released. In addition, the query log may contain statements that only select data while such statements are never written to the binary log.
When using statement-based binary logging on a replication source server, statements received by its replicas are written to the query log of each replica. Statements are written to the query log of the source if a client reads events with the mysqlbinlog utility and passes them to the server.
However, when using row-based binary logging, updates are sent as
row changes rather than SQL statements, and thus these statements
are never written to the query log when
binlog_format is
ROW. A given update also might not be written
to the query log when this variable is set to
MIXED, depending on the statement used. See
Section 17.2.1.1, “Advantages and Disadvantages of Statement-Based and Row-Based
Replication”, for more information.
By default, the general query log is disabled. To specify the
initial general query log state explicitly, use
--general_log[={0|1}]. With no
argument or an argument of 1,
--general_log enables the log. With
an argument of 0, this option disables the log. To specify a log
file name, use
--general_log_file=.
To specify the log destination, use the
file_namelog_output system variable (as
described in Section 5.4.1, “Selecting General Query Log and Slow Query Log Output Destinations”).
If you specify the TABLE log destination, see
Log Tables and “Too many open files” Errors.
If you specify no name for the general query log file, the default
name is
host_name.log
To disable or enable the general query log or change the log file
name at runtime, use the global
general_log and
general_log_file system
variables. Set general_log to 0
(or OFF) to disable the log or to 1 (or
ON) to enable it. Set
general_log_file to specify the
name of the log file. If a log file already is open, it is closed
and the new file is opened.
When the general query log is enabled, the server writes output to
any destinations specified by the
log_output system variable. If
you enable the log, the server opens the log file and writes
startup messages to it. However, further logging of queries to the
file does not occur unless the FILE log
destination is selected. If the destination is
NONE, the server writes no queries even if the
general log is enabled. Setting the log file name has no effect on
logging if the log destination value does not contain
FILE.
Server restarts and log flushing do not cause a new general query log file to be generated (although flushing closes and reopens it). To rename the file and create a new one, use the following commands:
shell>mvshell>host_name.loghost_name-old.logmysqladmin flush-logsshell>mvhost_name-old.logbackup-directory
On Windows, use rename rather than mv.
You can also rename the general query log file at runtime by disabling the log:
SET GLOBAL general_log = 'OFF';
With the log disabled, rename the log file externally (for example, from the command line). Then enable the log again:
SET GLOBAL general_log = 'ON';
This method works on any platform and does not require a server restart.
To disable or enable general query logging for the current
session, set the session
sql_log_off variable to
ON or OFF. (This assumes
that the general query log itself is enabled.)
Passwords in statements written to the general query log are
rewritten by the server not to occur literally in plain text.
Password rewriting can be suppressed for the general query log by
starting the server with the
--log-raw option. This option may
be useful for diagnostic purposes, to see the exact text of
statements as received by the server, but for security reasons is
not recommended for production use. See also
Section 6.1.2.3, “Passwords and Logging”.
An implication of password rewriting is that statements that
cannot be parsed (due, for example, to syntax errors) are not
written to the general query log because they cannot be known to
be password free. Use cases that require logging of all statements
including those with errors should use the
--log-raw option, bearing in mind
that this also bypasses password rewriting.
Password rewriting occurs only when plain text passwords are expected. For statements with syntax that expect a password hash value, no rewriting occurs. If a plain text password is supplied erroneously for such syntax, the password is logged as given, without rewriting.
The log_timestamps system
variable controls the time zone of timestamps in messages written
to the general query log file (as well as to the slow query log
file and the error log). It does not affect the time zone of
general query log and slow query log messages written to log
tables, but rows retrieved from those tables can be converted from
the local system time zone to any desired time zone with
CONVERT_TZ() or by setting the
session time_zone system
variable.
The binary log contains “events” that describe
database changes such as table creation operations or changes to
table data. It also contains events for statements that
potentially could have made changes (for example, a
DELETE which matched no rows),
unless row-based logging is used. The binary log also contains
information about how long each statement took that updated data.
The binary log has two important purposes:
For replication, the binary log on a replication source server provides a record of the data changes to be sent to replicas. The source sends the information contained in its binary log to its replicas, which reproduce those transactions to make the same data changes that were made on the source. See Section 17.2, “Replication Implementation”.
Certain data recovery operations require use of the binary log. After a backup has been restored, the events in the binary log that were recorded after the backup was made are re-executed. These events bring databases up to date from the point of the backup. See Section 7.5, “Point-in-Time (Incremental) Recovery”.
The binary log is not used for statements such as
SELECT or
SHOW that do not modify data. To
log all statements (for example, to identify a problem query), use
the general query log. See Section 5.4.3, “The General Query Log”.
Running a server with binary logging enabled makes performance slightly slower. However, the benefits of the binary log in enabling you to set up replication and for restore operations generally outweigh this minor performance decrement.
The binary log is resilient to unexpected halts. Only complete events or transactions are logged or read back.
Passwords in statements written to the binary log are rewritten by the server not to occur literally in plain text. See also Section 6.1.2.3, “Passwords and Logging”.
From MySQL 8.0.14, binary log files and relay log files can be
encrypted, helping to protect these files and the potentially
sensitive data contained in them from being misused by outside
attackers, and also from unauthorized viewing by users of the
operating system where they are stored. You enable encryption on a
MySQL server by setting the
binlog_encryption system variable
to ON. For more information, see
Section 17.3.2, “Encrypting Binary Log Files and Relay Log Files”.
The following discussion describes some of the server options and variables that affect the operation of binary logging. For a complete list, see Section 17.1.6.4, “Binary Logging Options and Variables”.
Binary logging is enabled by default (the
log_bin system variable is set to
ON). The exception is if you use mysqld to
initialize the data directory manually by invoking it with the
--initialize or
--initialize-insecure option, when
binary logging is disabled by default, but can be enabled by
specifying the --log-bin option.
To disable binary logging, you can specify the
--skip-log-bin
or
--disable-log-bin
option at startup. If either of these options is specified and
--log-bin is also specified, the
option specified later takes precedence.
The --log-slave-updates and
--slave-preserve-commit-order
options require binary logging. If you disable binary logging,
either omit these options, or specify
--log-slave-updates=OFF and
--skip-slave-preserve-commit-order.
MySQL disables these options by default when
--skip-log-bin
or
--disable-log-bin
is specified. If you specify
--log-slave-updates or
--slave-preserve-commit-order
together with
--skip-log-bin
or
--disable-log-bin,
a warning or error message is issued.
The
--log-bin[=
option is used to specify the base name for binary log files. If
you do not supply the base_name]--log-bin option, MySQL
uses binlog as the default base name for the
binary log files. For compatibility with earlier releases, if you
supply the --log-bin option with no string or
with an empty string, the base name defaults to
host_name-bin--log-bin=),
the extension is silently removed and ignored.
base_name.extension
mysqld appends a numeric extension to the binary log base name to generate binary log file names. The number increases each time the server creates a new log file, thus creating an ordered series of files. The server creates a new file in the series each time any of the following events occurs:
The server is started or restarted
The server flushes the logs.
The size of the current log file reaches
max_binlog_size.
A binary log file may become larger than
max_binlog_size if you are using
large transactions because a transaction is written to the file in
one piece, never split between files.
To keep track of which binary log files have been used,
mysqld also creates a binary log index file
that contains the names of the binary log files. By default, this
has the same base name as the binary log file, with the extension
'.index'. You can change the name of the binary
log index file with the
--log-bin-index[=
option. You should not manually edit this file while
mysqld is running; doing so would confuse
mysqld.
file_name]
The term “binary log file” generally denotes an individual numbered file containing database events. The term “binary log” collectively denotes the set of numbered binary log files plus the index file.
The default location for binary log files and the binary log index
file is the data directory. You can use the
--log-bin option to specify an
alternative location, by adding a leading absolute path name to
the base name to specify a different directory. When the server
reads an entry from the binary log index file, which tracks the
binary log files that have been used, it checks whether the entry
contains a relative path. If it does, the relative part of the
path is replaced with the absolute path set using the
--log-bin option. An absolute path
recorded in the binary log index file remains unchanged; in such a
case, the index file must be edited manually to enable a new path
or paths to be used. The binary log file base name and any
specified path are available as the
log_bin_basename system variable.
In MySQL 5.7, a server ID had to be specified when binary logging
was enabled, or the server would not start. In MySQL
8.0, the server_id
system variable is set to 1 by default. The server can be started
with this default ID when binary logging is enabled, but an
informational message is issued if you do not specify a server ID
explicitly using the server_id
system variable. For servers that are used in a replication
topology, you must specify a unique nonzero server ID for each
server.
A client that has privileges sufficient to set restricted session
system variables (see
Section 5.1.9.1, “System Variable Privileges”) can disable binary
logging of its own statements by using a
SET
sql_log_bin=OFF statement.
By default, the server logs the length of the event as well as the
event itself and uses this to verify that the event was written
correctly. You can also cause the server to write checksums for
the events by setting the
binlog_checksum system variable.
When reading back from the binary log, the source uses the event
length by default, but can be made to use checksums if available
by enabling the
master_verify_checksum system
variable. The replication I/O thread on the replica also verifies
events received from the source. You can cause the replication SQL
thread to use checksums if available when reading from the relay
log by enabling the
slave_sql_verify_checksum system
variable.
The format of the events recorded in the binary log is dependent on the binary logging format. Three format types are supported: row-based logging, statement-based logging and mixed-base logging. The binary logging format used depends on the MySQL version. For general descriptions of the logging formats, see Section 5.4.4.1, “Binary Logging Formats”. For detailed information about the format of the binary log, see MySQL Internals: The Binary Log.
The server evaluates the
--binlog-do-db and
--binlog-ignore-db options in the
same way as it does the
--replicate-do-db and
--replicate-ignore-db options. For
information about how this is done, see
Section 17.2.5.1, “Evaluation of Database-Level Replication and Binary Logging Options”.
A replica is started with the
log_slave_updates system variable
enabled by default, meaning that the replica writes to its own
binary log any data modifications that are received from the
source. The binary log must be enabled for this setting to work
(see Section 17.1.6.3, “Replica Server Options and Variables”). This setting
enables the replica to act as a source to other replicas.
You can delete all binary log files with the
RESET MASTER statement, or a subset
of them with PURGE BINARY LOGS. See
Section 13.7.8.6, “RESET Statement”, and Section 13.4.1.1, “PURGE BINARY LOGS Statement”.
If you are using replication, you should not delete old binary log
files on the source until you are sure that no replica still needs
to use them. For example, if your replicas never run more than
three days behind, once a day you can execute mysqladmin
flush-logs on the source and then remove any logs that
are more than three days old. You can remove the files manually,
but it is preferable to use PURGE BINARY
LOGS, which also safely updates the binary log index
file for you (and which can take a date argument). See
Section 13.4.1.1, “PURGE BINARY LOGS Statement”.
You can display the contents of binary log files with the mysqlbinlog utility. This can be useful when you want to reprocess statements in the log for a recovery operation. For example, you can update a MySQL server from the binary log as follows:
shell> mysqlbinlog log_file | mysql -h server_name
mysqlbinlog also can be used to display the contents of the relay log file on a replica, because they are written using the same format as binary log files. For more information on the mysqlbinlog utility and how to use it, see Section 4.6.8, “mysqlbinlog — Utility for Processing Binary Log Files”. For more information about the binary log and recovery operations, see Section 7.5, “Point-in-Time (Incremental) Recovery”.
Binary logging is done immediately after a statement or transaction completes but before any locks are released or any commit is done. This ensures that the log is logged in commit order.
Updates to nontransactional tables are stored in the binary log immediately after execution.
Within an uncommitted transaction, all updates
(UPDATE,
DELETE, or
INSERT) that change transactional
tables such as InnoDB tables are cached until a
COMMIT statement is received by the
server. At that point, mysqld writes the entire
transaction to the binary log before the
COMMIT is executed.
Modifications to nontransactional tables cannot be rolled back. If
a transaction that is rolled back includes modifications to
nontransactional tables, the entire transaction is logged with a
ROLLBACK
statement at the end to ensure that the modifications to those
tables are replicated.
When a thread that handles the transaction starts, it allocates a
buffer of binlog_cache_size to
buffer statements. If a statement is bigger than this, the thread
opens a temporary file to store the transaction. The temporary
file is deleted when the thread ends. From MySQL 8.0.17, if binary
log encryption is active on the server, the temporary file is
encrypted.
The Binlog_cache_use status
variable shows the number of transactions that used this buffer
(and possibly a temporary file) for storing statements. The
Binlog_cache_disk_use status
variable shows how many of those transactions actually had to use
a temporary file. These two variables can be used for tuning
binlog_cache_size to a large
enough value that avoids the use of temporary files.
The max_binlog_cache_size system
variable (default 4GB, which is also the maximum) can be used to
restrict the total size used to cache a multiple-statement
transaction. If a transaction is larger than this many bytes, it
fails and rolls back. The minimum value is 4096.
If you are using the binary log and row based logging, concurrent
inserts are converted to normal inserts for CREATE ...
SELECT or
INSERT ...
SELECT statements. This is done to ensure that you can
re-create an exact copy of your tables by applying the log during
a backup operation. If you are using statement-based logging, the
original statement is written to the log.
The binary log format has some known limitations that can affect recovery from backups. See Section 17.5.1, “Replication Features and Issues”.
Binary logging for stored programs is done as described in Section 25.7, “Stored Program Binary Logging”.
Note that the binary log format differs in MySQL 8.0 from previous versions of MySQL, due to enhancements in replication. See Section 17.5.2, “Replication Compatibility Between MySQL Versions”.
If the server is unable to write to the binary log, flush binary
log files, or synchronize the binary log to disk, the binary log
on the replication source server can become inconsistent and
replicas can lose synchronization with the source. The
binlog_error_action system
variable controls the action taken if an error of this type is
encountered with the binary log.
The default setting,
ABORT_SERVER, makes the server halt binary logging and shut down. At this point, you can identify and correct the cause of the error. On restart, recovery proceeds as in the case of an unexpected server halt (see Section 17.4.2, “Handling an Unexpected Halt of a Replica”).The setting
IGNORE_ERRORprovides backward compatibility with older versions of MySQL. With this setting, the server continues the ongoing transaction and logs the error, then halts binary logging, but continues to perform updates. At this point, you can identify and correct the cause of the error. To resume binary logging,log_binmust be enabled again, which requires a server restart. Only use this option if you require backward compatibility, and the binary log is non-essential on this MySQL server instance. For example, you might use the binary log only for intermittent auditing or debugging of the server, and not use it for replication from the server or rely on it for point-in-time restore operations.
By default, the binary log is synchronized to disk at each write
(sync_binlog=1). If
sync_binlog was not enabled, and
the operating system or machine (not only the MySQL server)
crashed, there is a chance that the last statements of the binary
log could be lost. To prevent this, enable the
sync_binlog system variable to
synchronize the binary log to disk after every
N commit groups. See
Section 5.1.8, “Server System Variables”. The safest value for
sync_binlog is 1 (the default),
but this is also the slowest.
In earlier MySQL releases, there was a chance of inconsistency
between the table content and binary log content if a crash
occurred, even with sync_binlog
set to 1. For example, if you are using InnoDB
tables and the MySQL server processes a
COMMIT statement, it writes many
prepared transactions to the binary log in sequence, synchronizes
the binary log, and then commits the transaction into
InnoDB. If the server unexpectedly exited
between those two operations, the transaction would be rolled back
by InnoDB at restart but still exist in the
binary log. Such an issue was resolved in previous releases by
enabling InnoDB support for two-phase commit in
XA transactions. In 8.0.0 and higher, the
InnoDB support for two-phase commit in XA
transactions is always enabled.
InnoDB support for two-phase commit in XA
transactions ensures that the binary log and
InnoDB data files are synchronized. However,
the MySQL server should also be configured to synchronize the
binary log and the InnoDB logs to disk before
committing the transaction. The InnoDB logs are
synchronized by default, and sync_binlog=1
ensures the binary log is synchronized. The effect of implicit
InnoDB support for two-phase commit in XA
transactions and sync_binlog=1 is that at
restart after a crash, after doing a rollback of transactions, the
MySQL server scans the latest binary log file to collect
transaction xid values and calculate
the last valid position in the binary log file. The MySQL server
then tells InnoDB to complete any prepared
transactions that were successfully written to the to the binary
log, and truncates the binary log to the last valid position. This
ensures that the binary log reflects the exact data of
InnoDB tables, and therefore the replica
remains in synchrony with the source because it does not receive a
statement which has been rolled back.
If the MySQL server discovers at crash recovery that the binary
log is shorter than it should have been, it lacks at least one
successfully committed InnoDB transaction. This
should not happen if sync_binlog=1 and the
disk/file system do an actual sync when they are requested to
(some do not), so the server prints an error message The
binary log . In this case, this binary log is not
correct and replication should be restarted from a fresh snapshot
of the source's data.
file_name is shorter than
its expected size
The session values of the following system variables are written to the binary log and honored by the replica when parsing the binary log:
sql_mode(except that theNO_DIR_IN_CREATEmode is not replicated; see Section 17.5.1.39, “Replication and Variables”)
The server uses several logging formats to record information in the binary log:
Replication capabilities in MySQL originally were based on propagation of SQL statements from source to replica. This is called statement-based logging. You can cause this format to be used by starting the server with
--binlog-format=STATEMENT.In row-based logging (the default), the source writes events to the binary log that indicate how individual table rows are affected. You can cause the server to use row-based logging by starting it with
--binlog-format=ROW.A third option is also available: mixed logging. With mixed logging, statement-based logging is used by default, but the logging mode switches automatically to row-based in certain cases as described below. You can cause MySQL to use mixed logging explicitly by starting mysqld with the option
--binlog-format=MIXED.
The logging format can also be set or limited by the storage engine being used. This helps to eliminate issues when replicating certain statements between a source and replica which are using different storage engines.
With statement-based replication, there may be issues with replicating nondeterministic statements. In deciding whether or not a given statement is safe for statement-based replication, MySQL determines whether it can guarantee that the statement can be replicated using statement-based logging. If MySQL cannot make this guarantee, it marks the statement as potentially unreliable and issues the warning, Statement may not be safe to log in statement format.
You can avoid these issues by using MySQL's row-based replication instead.
You can select the binary logging format explicitly by starting
the MySQL server with
--binlog-format=.
The supported values for typetype are:
STATEMENTcauses logging to be statement based.ROWcauses logging to be row based. This is the default.MIXEDcauses logging to use mixed format.
The logging format also can be switched at runtime, although
note that there are a number of situations in which you cannot
do this, as discussed later in this section. Set the global
value of the binlog_format
system variable to specify the format for clients that connect
subsequent to the change:
mysql>SET GLOBAL binlog_format = 'STATEMENT';mysql>SET GLOBAL binlog_format = 'ROW';mysql>SET GLOBAL binlog_format = 'MIXED';
An individual client can control the logging format for its own
statements by setting the session value of
binlog_format:
mysql>SET SESSION binlog_format = 'STATEMENT';mysql>SET SESSION binlog_format = 'ROW';mysql>SET SESSION binlog_format = 'MIXED';
Changing the global
binlog_format value requires
privileges sufficient to set global system variables. Changing
the session binlog_format value
requires privileges sufficient to set restricted session system
variables. See Section 5.1.9.1, “System Variable Privileges”.
There are several reasons why a client might want to set binary logging on a per-session basis:
A session that makes many small changes to the database might want to use row-based logging.
A session that performs updates that match many rows in the
WHEREclause might want to use statement-based logging because it is more efficient to log a few statements than many rows.Some statements require a lot of execution time on the source, but result in just a few rows being modified. It might therefore be beneficial to replicate them using row-based logging.
There are exceptions when you cannot switch the replication format at runtime:
The replication format cannot be changed from within a stored function or a trigger.
If the
NDBstorage engine is enabled.If a session has open temporary tables, the replication format cannot be changed for the session (
SET @@SESSION.binlog_format).If any replication channel has open temporary tables, the replication format cannot be changed globally (
SET @@GLOBAL.binlog_formatorSET @@PERSIST.binlog_format).If any replication channel applier thread is currently running, the replication format cannot be changed globally (
SET @@GLOBAL.binlog_formatorSET @@PERSIST.binlog_format).
Trying to switch the replication format in any of these cases
(or attempting to set the current replication format) results in
an error. You can, however, use PERSIST_ONLY
(SET @@PERSIST_ONLY.binlog_format) to change
the replication format at any time, because this action does not
modify the runtime global system variable value, and takes
effect only after a server restart.
Switching the replication format at runtime is not recommended when any temporary tables exist, because temporary tables are logged only when using statement-based replication, whereas with row-based replication and mixed replication, they are not logged.
Switching the replication format while replication is ongoing
can also cause issues. Each MySQL Server can set its own and
only its own binary logging format (true whether
binlog_format is set with
global or session scope). This means that changing the logging
format on a replication source server does not cause a replica
to change its logging format to match. When using
STATEMENT mode, the
binlog_format system variable
is not replicated. When using MIXED or
ROW logging mode, it is replicated but is
ignored by the replica.
A replica is not able to convert binary log entries received in
ROW logging format to
STATEMENT format for use in its own binary
log. The replica must therefore use ROW or
MIXED format if the source does. Changing the
binary logging format on the source from
STATEMENT to ROW or
MIXED while replication is ongoing to a
replica with STATEMENT format can cause
replication to fail with errors such as Error
executing row event: 'Cannot execute statement: impossible to
write to binary log since statement is in row format and
BINLOG_FORMAT = STATEMENT.' Changing the binary
logging format on the replica to STATEMENT
format when the source is still using MIXED
or ROW format also causes the same type of
replication failure. To change the format safely, you must stop
replication and ensure that the same change is made on both the
source and the replica.
If you are using InnoDB tables and
the transaction isolation level is READ
COMMITTED or READ
UNCOMMITTED, only row-based logging can be used. It is
possible to change the logging format to
STATEMENT, but doing so at runtime leads very
rapidly to errors because InnoDB can no
longer perform inserts.
With the binary log format set to ROW, many
changes are written to the binary log using the row-based
format. Some changes, however, still use the statement-based
format. Examples include all DDL (data definition language)
statements such as CREATE TABLE,
ALTER TABLE, or
DROP TABLE.
When row-based binary logging is used, the
binlog_row_event_max_size
system variable and its corresponding startup option
--binlog-row-event-max-size set a
soft limit on the maximum size of row events. The default value
is 8192 bytes, and the value can only be changed at server
startup. Where possible, rows stored in the binary log are
grouped into events with a size not exceeding the value of this
setting. If an event cannot be split, the maximum size can be
exceeded.
The --binlog-row-event-max-size
option is available for servers that are capable of row-based
replication. Rows are stored into the binary log in chunks
having a size in bytes not exceeding the value of this option.
The value must be a multiple of 256. The default value is 8192.
When using statement-based logging for replication, it is possible for the data on the source and replica to become different if a statement is designed in such a way that the data modification is nondeterministic; that is, it is left up to the query optimizer. In general, this is not a good practice even outside of replication. For a detailed explanation of this issue, see Section B.3.7, “Known Issues in MySQL”.
When running in MIXED logging format, the
server automatically switches from statement-based to row-based
logging under the following conditions:
When a function contains
UUID().When one or more tables with
AUTO_INCREMENTcolumns are updated and a trigger or stored function is invoked. Like all other unsafe statements, this generates a warning ifbinlog_format = STATEMENT.For more information, see Section 17.5.1.1, “Replication and AUTO_INCREMENT”.
When the body of a view requires row-based replication, the statement creating the view also uses it. For example, this occurs when the statement creating a view uses the
UUID()function.When a call to a UDF is involved.
When
FOUND_ROWS()orROW_COUNT()is used. (Bug #12092, Bug #30244)When
USER(),CURRENT_USER(), orCURRENT_USERis used. (Bug #28086)When one of the tables involved is a log table in the
mysqldatabase.When the
LOAD_FILE()function is used. (Bug #39701)When a statement refers to one or more system variables. (Bug #31168)
Exception. The following system variables, when used with session scope (only), do not cause the logging format to switch:
For information about determining system variable scope, see Section 5.1.9, “Using System Variables”.
For information about how replication treats
sql_mode, see Section 17.5.1.39, “Replication and Variables”.
In earlier releases, when mixed binary logging format was in use, if a statement was logged by row and the session that executed the statement had any temporary tables, all subsequent statements were treated as unsafe and logged in row-based format until all temporary tables in use by that session were dropped. As of MySQL 8.0, operations on temporary tables are not logged in mixed binary logging format, and the presence of temporary tables in the session has no impact on the logging mode used for each statement.
A warning is generated if you try to execute a statement using
statement-based logging that should be written using row-based
logging. The warning is shown both in the client (in the
output of SHOW WARNINGS) and
through the mysqld error log. A warning is
added to the SHOW WARNINGS
table each time such a statement is executed. However, only
the first statement that generated the warning for each client
session is written to the error log to prevent flooding the
log.
In addition to the decisions above, individual engines can also determine the logging format used when information in a table is updated. The logging capabilities of an individual engine can be defined as follows:
If an engine supports row-based logging, the engine is said to be row-logging capable.
If an engine supports statement-based logging, the engine is said to be statement-logging capable.
A given storage engine can support either or both logging formats. The following table lists the formats supported by each engine.
| Storage Engine | Row Logging Supported | Statement Logging Supported |
|---|---|---|
ARCHIVE |
Yes | Yes |
BLACKHOLE |
Yes | Yes |
CSV |
Yes | Yes |
EXAMPLE |
Yes | No |
FEDERATED |
Yes | Yes |
HEAP |
Yes | Yes |
InnoDB |
Yes | Yes when the transaction isolation level is
REPEATABLE READ or
SERIALIZABLE; No
otherwise. |
MyISAM |
Yes | Yes |
MERGE |
Yes | Yes |
NDB |
Yes | No |
Whether a statement is to be logged and the logging mode to be
used is determined according to the type of statement (safe,
unsafe, or binary injected), the binary logging format
(STATEMENT, ROW, or
MIXED), and the logging capabilities of the
storage engine (statement capable, row capable, both, or
neither). (Binary injection refers to logging a change that must
be logged using ROW format.)
Statements may be logged with or without a warning; failed statements are not logged, but generate errors in the log. This is shown in the following decision table. Type, binlog_format, SLC, and RLC columns outline the conditions, and Error / Warning and Logged as columns represent the corresponding actions. SLC stands for “statement-logging capable”, and RLC stands for “row-logging capable”.
| Type | binlog_format |
SLC | RLC | Error / Warning | Logged as |
|---|---|---|---|---|---|
| * | * |
No | No | Error: Cannot execute statement: Binary logging is impossible since at least one engine is involved that is both row-incapable and statement-incapable. | - |
| Safe | STATEMENT |
Yes | No | - | STATEMENT |
| Safe | MIXED |
Yes | No | - | STATEMENT |
| Safe | ROW |
Yes | No | Error: Cannot execute statement: Binary logging
is impossible since BINLOG_FORMAT = ROW
and at least one table uses a storage engine that is not
capable of row-based logging. |
- |
| Unsafe | STATEMENT |
Yes | No | Warning: Unsafe statement binlogged in statement
format, since BINLOG_FORMAT =
STATEMENT |
STATEMENT |
| Unsafe | MIXED |
Yes | No | Error: Cannot execute statement: Binary logging
of an unsafe statement is impossible when the storage
engine is limited to statement-based logging, even if
BINLOG_FORMAT = MIXED. |
- |
| Unsafe | ROW |
Yes | No | Error: Cannot execute statement: Binary logging
is impossible since BINLOG_FORMAT = ROW
and at least one table uses a storage engine that is not
capable of row-based logging. |
- |
| Row Injection | STATEMENT |
Yes | No | Error: Cannot execute row injection: Binary logging is not possible since at least one table uses a storage engine that is not capable of row-based logging. | - |
| Row Injection | MIXED |
Yes | No | Error: Cannot execute row injection: Binary logging is not possible since at least one table uses a storage engine that is not capable of row-based logging. | - |
| Row Injection | ROW |
Yes | No | Error: Cannot execute row injection: Binary logging is not possible since at least one table uses a storage engine that is not capable of row-based logging. | - |
| Safe | STATEMENT |
No | Yes | Error: Cannot execute statement: Binary logging
is impossible since BINLOG_FORMAT =
STATEMENT and at least one table uses a storage
engine that is not capable of statement-based logging. |
- |
| Safe | MIXED |
No | Yes | - | ROW |
| Safe | ROW |
No | Yes | - | ROW |
| Unsafe | STATEMENT |
No | Yes | Error: Cannot execute statement: Binary logging
is impossible since BINLOG_FORMAT =
STATEMENT and at least one table uses a storage
engine that is not capable of statement-based logging. |
- |
| Unsafe | MIXED |
No | Yes | - | ROW |
| Unsafe | ROW |
No | Yes | - | ROW |
| Row Injection | STATEMENT |
No | Yes | Error: Cannot execute row injection: Binary
logging is not possible since BINLOG_FORMAT =
STATEMENT. |
- |
| Row Injection | MIXED |
No | Yes | - | ROW |
| Row Injection | ROW |
No | Yes | - | ROW |
| Safe | STATEMENT |
Yes | Yes | - | STATEMENT |
| Safe | MIXED |
Yes | Yes | - | STATEMENT |
| Safe | ROW |
Yes | Yes | - | ROW |
| Unsafe | STATEMENT |
Yes | Yes | Warning: Unsafe statement binlogged in statement
format since BINLOG_FORMAT =
STATEMENT. |
STATEMENT |
| Unsafe | MIXED |
Yes | Yes | - | ROW |
| Unsafe | ROW |
Yes | Yes | - | ROW |
| Row Injection | STATEMENT |
Yes | Yes | Error: Cannot execute row injection: Binary
logging is not possible because BINLOG_FORMAT =
STATEMENT. |
- |
| Row Injection | MIXED |
Yes | Yes | - | ROW |
| Row Injection | ROW |
Yes | Yes | - | ROW |
When a warning is produced by the determination, a standard
MySQL warning is produced (and is available using
SHOW WARNINGS). The information
is also written to the mysqld error log. Only
one error for each error instance per client connection is
logged to prevent flooding the log. The log message includes the
SQL statement that was attempted.
If a replica has
log_error_verbosity set to
display warnings, the replica prints messages to the error log
to provide information about its status, such as the binary log
and relay log coordinates where it starts its job, when it is
switching to another relay log, when it reconnects after a
disconnect, statements that are unsafe for statement-based
logging, and so forth.
The contents of the grant tables in the mysql
database can be modified directly (for example, with
INSERT or
DELETE) or indirectly (for
example, with GRANT or
CREATE USER). Statements that
affect mysql database tables are written to
the binary log using the following rules:
Data manipulation statements that change data in
mysqldatabase tables directly are logged according to the setting of thebinlog_formatsystem variable. This pertains to statements such asINSERT,UPDATE,DELETE,REPLACE,DO,LOAD DATA,SELECT, andTRUNCATE TABLE.Statements that change the
mysqldatabase indirectly are logged as statements regardless of the value ofbinlog_format. This pertains to statements such asGRANT,REVOKE,SET PASSWORD,RENAME USER,CREATE(all forms exceptCREATE TABLE ... SELECT),ALTER(all forms), andDROP(all forms).
CREATE TABLE ...
SELECT is a combination of data definition and data
manipulation. The CREATE TABLE
part is logged using statement format and the
SELECT part is logged according
to the value of binlog_format.
From MySQL 8.0.20, you can enable binary log transaction
compression on a MySQL server instance. When binary log
transaction compression is enabled, transaction payloads are
compressed using the zstd algorithm, and then written to the
server's binary log file as a single event (a
Transaction_payload_event). Compressed
transaction payloads remain in a compressed state while they are
sent in the replication stream to replicas, other Group
Replication group members, or clients such as
mysqlbinlog. They are not decompressed by
receiver threads, and are written to the relay log still in
their compressed state. Binary log transaction compression
therefore saves storage space both on the originator of the
transaction and on the recipient (and for their backups), and
saves network bandwidth when the transactions are sent between
server instances.
Compressed transaction payloads are decompressed when the
individual events contained in them need to be inspected. For
example, the Transaction_payload_event is
decompressed by an applier thread in order to apply the events
it contains on the recipient. Decompression is also carried out
during recovery, by mysqlbinlog when
replaying transactions, and by the SHOW
BINLOG EVENTS and SHOW RELAYLOG
EVENTS statements.
You can enable binary log transaction compression on a MySQL
server instance using the
binlog_transaction_compression
system variable, which defaults to OFF. You
can also use the
binlog_transaction_compression_level_zstd
system variable to set the level for the zstd algorithm that is
used for compression. This value determines the compression
effort, from 1 (the lowest effort) to 22 (the highest effort).
As the compression level increases, the compression ratio
increases, which reduces the storage space and network bandwidth
required for the transaction payload. However, the effort
required for data compression also increases, taking time and
CPU and memory resources on the originating server. Increases in
the compression effort do not have a linear relationship to
increases in the compression ratio.
The following types of event are excluded from binary log transaction compression, so are always written uncompressed to the binary log:
Events relating to the GTID for the transaction (including anonymous GTID events).
Other types of control event, such as view change events and heartbeat events.
Incident events and the whole of any transactions that contain them.
Non-transactional events and the whole of any transactions that contain them. A transaction involving a mix of non-transactional and transactional storage engines does not have its payload compressed.
Events that are logged using statement-based binary logging. Binary log transaction compression is only applied for the row-based binary logging format.
Binary log encryption can be used on binary log files that contain compressed transactions.
Transactions with payloads that are compressed can be rolled back like any other transaction, and they can also be filtered out on a replica by the usual filtering options. Binary log transaction compression can be applied to XA transactions.
When binary log transaction compression is enabled, the
max_allowed_packet and
slave_max_allowed_packet
limits for the server still apply, and are measured on the
compressed size of the
Transaction_payload_event, plus the bytes
used for the event header. Note that compressed transaction
payloads are sent as a single packet, rather than each event
of the transaction being sent in an individual packet, as is
the case when binary log transaction compression is not in
use.
For multithreaded workers, each transaction (including its
GTID event and Transaction_payload_event)
is assigned to a worker thread. The worker thread decompresses
the transaction payload and applies the individual events in
it one by one. If an error is found applying any event within
the Transaction_payload_event, the complete
transaction is reported to the co-ordinator as having failed.
When slave_parallel_type is
set to DATABASE, all the databases affected
by the transaction are mapped before the transaction is
scheduled. The use of binary log transaction compression with
the DATABASE policy can reduce parallelism
compared to uncompressed transactions, which are mapped and
scheduled for each event.
For semisynchronous replication (see
Section 17.4.10, “Semisynchronous Replication”), the replica
acknowledges the transaction when the complete
Transaction_payload_event has been
received.
When binary log checksums are enabled (which is the default),
the replication source server does not write checksums for
individual events in a compressed transaction payload.
Instead, a checksum is written for the complete
Transaction_payload_event, and indivdual
checksums are written for any events that were not compressed,
such as events relating to GTIDs.
For the SHOW BINLOG EVENTS and
SHOW RELAYLOG EVENTS
statements, the Transaction_payload_event
is first printed as a single unit, then it is unpacked and
each event inside it is printed.
For operations that reference the end position of an event,
such as START
REPLICA | SLAVE with the UNTIL
clause, MASTER_POS_WAIT(), and
sql_slave_skip_counter, you
must specify the end position of the compressed transaction
payload (the Transaction_payload_event).
When skipping events using
sql_slave_skip_counter,
a compressed transaction payload is counted as a single
counter value, so all the events inside it are skipped as a
unit.
MySQL Server releases that support binary log transaction compression can handle a mix of compressed and uncompressed transaction payloads.
The system variables relating to binary log transaction compression do not need to be set the same on all Group Replication group members, and are not replicated from sources to replicas in a replication topology. You can decide whether or not binary log transaction compression is appropriate for each MySQL Server instance that has a binary log.
If transaction compression is enabled then disabled on a server, compression is not applied to future transactions originated on that server, but transaction payloads that have been compressed can still be handled and displayed.
If transaction compression is specified for individual sessions by setting the session value of
binlog_transaction_compression, the binary log can contain a mix of compressed and uncompressed transaction payloads.
When a source in a replication topology and its replica both have binary log transaction compression enabled, the replica receives compressed transaction payloads and writes them compressed to its relay log. It decompresses the transaction payloads to apply the transactions, and then compresses them again after applying for writing to its binary log. Any downstream replicas receive the compressed transaction payloads.
When a source in a replication topology has binary log transaction compression enabled but its replica does not, the replica receives compressed transaction payloads and writes them compressed to its relay log. It decompresses the transaction payloads to apply the transactions, and then writes them uncompressed to its own binary log, if it has one. Any downstream replicas receive the uncompressed transaction payloads.
When a source in a replication topology does not have binary log transaction compression enabled but its replica does, if the replica has a binary log, it compresses the transaction payloads after applying them, and writes the compressed transaction payloads to its binary log. Any downstream replicas receive the compressed transaction payloads.
When a MySQL server instance has no binary log, if it is at a
release from MySQL 8.0.20, it can receive, handle, and display
compressed transaction payloads regardless of its value for
binlog_transaction_compression.
Compressed transaction payloads received by such server
instances are written in their compressed state to the relay
log, so they benefit indirectly from compression that was
carried out by other servers in the replication topology.
A replica at a release before MySQL 8.0.20 cannot replicate from a source with binary log transaction compression enabled. A replica at or above MySQL 8.0.20 can replicate from a source at an earlier release that does not support binary log transaction compression, and can carry out its own compression on transactions received from that source when writing them to its own binary log.
You can monitor the effects of binary log transaction
compression using the Performance Schema table
binary_log_transaction_compression_stats.
The statistics include the data compression ratio for the
monitored period, and you can also view the effect of
compression on the last transaction on the server. You can
reset the statistics by truncating the table. Statistics for
binary logs and relay logs are split out so you can see the
impact of compression for each log type. The MySQL server
instance must have a binary log to produce these statistics.
The Performance Schema table
events_stages_current shows when
a transaction is in the stage of decompression or compression
for its transaction payload, and displays its progress for
this stage. Compression is carried out by the worker thread
handling the transaction, just before the transaction is
committed, provided that there are no events in the finalized
capture cache that exclude the transaction from binary log
transaction compression (for example, incident events). When
decompression is required, it is carried out for one event
from the payload at a time.
mysqlbinlog with the
--verbose option includes
comments stating the compressed size and the uncompressed size
for compressed transaction payloads, and the compression
algorithm that was used.
You can enable connection compression at the protocol level
for replication connections, using the
MASTER_COMPRESSION_ALGORITHMS and
MASTER_ZSTD_COMPRESSION_LEVEL options of
the CHANGE MASTER TO statement
(or the deprecated
slave_compressed_protocol
system variable). If you enable binary log transaction
compression in a system where connection compression is also
enabled, the impact of connection compression is reduced, as
there might be little opportunity to further compress the
compressed transaction payloads. However, connection
compression can still operate on uncompressed events and on
message headers. Binary log transaction compression can be
enabled in combination with connection compression if you need
to save storage space as well as network bandwidth. For more
information on connection compression for replication
connections, see
Section 4.2.8, “Connection Compression Control”.
For Group Replication, compression is enabled by default for
messages that exceed the threshold set by the
group_replication_compression_threshold
system variable. You can also configure compression for
messages sent for distributed recovery by the method of state
transfer from a donor's binary log, using the
group_replication_recovery_compression_algorithm
and
group_replication_recovery_zstd_compression_level
system variables. If you enable binary log transaction
compression in a system where these are configured, Group
Replication's message compression can still operate on
uncompressed events and on message headers, but its impact is
reduced. For more information on message compression for Group
Replication, see
Section 18.6.3, “Message Compression”.
The slow query log consists of SQL statements that take more than
long_query_time seconds to
execute and require at least
min_examined_row_limit rows to be
examined. The slow query log can be used to find queries that take
a long time to execute and are therefore candidates for
optimization. However, examining a long slow query log can be a
time-consuming task. To make this easier, you can use the
mysqldumpslow command to process a slow query
log file and summarize its contents. See
Section 4.6.9, “mysqldumpslow — Summarize Slow Query Log Files”.
The time to acquire the initial locks is not counted as execution time. mysqld writes a statement to the slow query log after it has been executed and after all locks have been released, so log order might differ from execution order.
The minimum and default values of
long_query_time are 0 and 10,
respectively. The value can be specified to a resolution of
microseconds.
By default, administrative statements are not logged, nor are
queries that do not use indexes for lookups. This behavior can
be changed using
log_slow_admin_statements and
log_queries_not_using_indexes,
as described later.
By default, the slow query log is disabled. To specify the
initial slow query log state explicitly, use
--slow_query_log[={0|1}]. With no
argument or an argument of 1,
--slow_query_log enables the log.
With an argument of 0, this option disables the log. To specify
a log file name, use
--slow_query_log_file=.
To specify the log destination, use the
file_namelog_output system variable (as
described in Section 5.4.1, “Selecting General Query Log and Slow Query Log Output Destinations”).
If you specify the TABLE log destination,
see Log Tables and “Too many open files” Errors.
If you specify no name for the slow query log file, the default
name is
host_name-slow.log
To disable or enable the slow query log or change the log file
name at runtime, use the global
slow_query_log and
slow_query_log_file system
variables. Set slow_query_log
to 0 to disable the log or to 1 to enable it. Set
slow_query_log_file to specify
the name of the log file. If a log file already is open, it is
closed and the new file is opened.
The server writes less information to the slow query log if you
use the --log-short-format
option.
To include slow administrative statements in the slow query log,
enable the
log_slow_admin_statements
system variable. Administrative statements include
ALTER TABLE,
ANALYZE TABLE,
CHECK TABLE,
CREATE INDEX,
DROP INDEX,
OPTIMIZE TABLE, and
REPAIR TABLE.
To include queries that do not use indexes for row lookups in
the statements written to the slow query log, enable the
log_queries_not_using_indexes
system variable. (Even with that variable enabled, the server
does not log queries that would not benefit from the presence of
an index due to the table having fewer than two rows.)
When queries that do not use an index are logged, the slow query
log may grow quickly. It is possible to put a rate limit on
these queries by setting the
log_throttle_queries_not_using_indexes
system variable. By default, this variable is 0, which means
there is no limit. Positive values impose a per-minute limit on
logging of queries that do not use indexes. The first such query
opens a 60-second window within which the server logs queries up
to the given limit, then suppresses additional queries. If there
are suppressed queries when the window ends, the server logs a
summary that indicates how many there were and the aggregate
time spent in them. The next 60-second window begins when the
server logs the next query that does not use indexes.
The server uses the controlling parameters in the following order to determine whether to write a query to the slow query log:
The query must either not be an administrative statement, or
log_slow_admin_statementsmust be enabled.The query must have taken at least
long_query_timeseconds, orlog_queries_not_using_indexesmust be enabled and the query used no indexes for row lookups.The query must have examined at least
min_examined_row_limitrows.The query must not be suppressed according to the
log_throttle_queries_not_using_indexessetting.
The log_timestamps system
variable controls the time zone of timestamps in messages
written to the slow query log file (as well as to the general
query log file and the error log). It does not affect the time
zone of general query log and slow query log messages written to
log tables, but rows retrieved from those tables can be
converted from the local system time zone to any desired time
zone with CONVERT_TZ() or by
setting the session time_zone
system variable.
By default, a replica does not write replicated queries to the
slow query log. To change this, enable the
log_slow_slave_statements
system variable. Note that if row-based replication is in use
(binlog_format=ROW),
log_slow_slave_statements has
no effect. Queries are only added to the replica's slow query
log when they are logged in statement format in the binary log,
that is, when
binlog_format=STATEMENT is set,
or when binlog_format=MIXED is
set and the statement is logged in statement format. Slow
queries that are logged in row format when
binlog_format=MIXED is set, or
that are logged when
binlog_format=ROW is set, are
not added to the replica's slow query log, even if
log_slow_slave_statements is
enabled.
When the slow query log is enabled, the server writes output to
any destinations specified by the
log_output system variable. If
you enable the log, the server opens the log file and writes
startup messages to it. However, further logging of queries to
the file does not occur unless the FILE log
destination is selected. If the destination is
NONE, the server writes no queries even if
the slow query log is enabled. Setting the log file name has no
effect on logging if FILE is not selected as
an output destination.
If the slow query log is enabled and FILE is
selected as an output destination, each statement written to the
log is preceded by a line that begins with a
# character and has these fields (with all
fields on a single line):
Query_time:durationThe statement execution time in seconds.
Lock_time:durationThe time to acquire locks in seconds.
Rows_sent:NThe number of rows sent to the client.
Rows_examined:The number of rows examined by the server layer (not counting any processing internal to storage engines).
Enabling the log_slow_extra
system variable (available as of MySQL 8.0.14) causes the server
to write the following extra fields to FILE
output in addition to those just listed
(TABLE output is unaffected). Some field
descriptions refer to status variable names. Consult the status
variable descriptions for more information. However, in the slow
query log, the counters are per-statement values, not cumulative
per-session values.
Thread_id:IDThe statement thread identifier.
Errno:error_numberThe statement error number, or 0 if no error occurred.
Killed:NIf the statement was terminated, the error number indicating why, or 0 if the statement terminated normally.
Bytes_received:NThe
Bytes_receivedvalue for the statement.Bytes_sent:NThe
Bytes_sentvalue for the statement.Read_first:NThe
Handler_read_firstvalue for the statement.Read_last:NThe
Handler_read_lastvalue for the statement.Read_key:NThe
Handler_read_keyvalue for the statement.Read_next:NThe
Handler_read_nextvalue for the statement.Read_prev:NThe
Handler_read_prevvalue for the statement.Read_rnd:NThe
Handler_read_rndvalue for the statement.Read_rnd_next:NThe
Handler_read_rnd_nextvalue for the statement.Sort_merge_passes:NThe
Sort_merge_passesvalue for the statement.Sort_range_count:NThe
Sort_rangevalue for the statement.Sort_rows:NThe
Sort_rowsvalue for the statement.Sort_scan_count:NThe
Sort_scanvalue for the statement.Created_tmp_disk_tables:NThe
Created_tmp_disk_tablesvalue for the statement.Created_tmp_tables:NThe
Created_tmp_tablesvalue for the statement.Start:timestampThe statement execution start time.
End:timestampThe statement execution end time.
A given slow query log file may contain a mix of lines with and
without the extra fields added by enabling
log_slow_extra. Log file
analyzers can determine whether a line contains the additional
fields by the field count.
Each statement written to the slow query log file is preceded by
a SET
statement that includes a timestamp. As of MySQL 8.0.14, the
timestamp indicates when the slow statement began executing.
Prior to 8.0.14, the timestamp indicates when the slow statement
was logged (which occurs after the statement finishes
executing).
Passwords in statements written to the slow query log are rewritten by the server not to occur literally in plain text. See Section 6.1.2.3, “Passwords and Logging”.
As described in Section 5.4, “MySQL Server Logs”, MySQL Server can create several different log files to help you see what activity is taking place. However, you must clean up these files regularly to ensure that the logs do not take up too much disk space.
When using MySQL with logging enabled, you may want to back up and remove old log files from time to time and tell MySQL to start logging to new files. See Section 7.2, “Database Backup Methods”.
On a Linux (Red Hat) installation, you can use the
mysql-log-rotate script for log maintenance. If
you installed MySQL from an RPM distribution, this script should
have been installed automatically. Be careful with this script if
you are using the binary log for replication. You should not
remove binary logs until you are certain that their contents have
been processed by all replicas.
On other systems, you must install a short script yourself that you start from cron (or its equivalent) for handling log files.
Binary log files are automatically removed after the server's
binary log expiration period. Removal of the files can take place
at startup and when the binary log is flushed. The default binary
log expiration period is 30 days. To specify an alternative
expiration period, use the
binlog_expire_logs_seconds system
variable. If you are using replication, you should specify an
expiration period that is no lower than the maximum amount of time
your replicas might lag behind the source. To remove binary logs
on demand, use the PURGE BINARY
LOGS statement (see
Section 13.4.1.1, “PURGE BINARY LOGS Statement”).
To force MySQL to start using new log files, flush the logs. Log
flushing occurs when you execute a FLUSH
LOGS statement or a mysqladmin
flush-logs, mysqladmin refresh,
mysqldump --flush-logs, or mysqldump
--master-data command. See Section 13.7.8.3, “FLUSH Statement”,
Section 4.5.2, “mysqladmin — A MySQL Server Administration Program”, and Section 4.5.4, “mysqldump — A Database Backup Program”. In
addition, the server flushes the binary log automatically when
current binary log file size reaches the value of the
max_binlog_size system variable.
FLUSH LOGS supports optional
modifiers to enable selective flushing of individual logs (for
example, FLUSH BINARY LOGS). See
Section 13.7.8.3, “FLUSH Statement”.
A log-flushing operation has the following effects:
If binary logging is enabled, the server closes the current binary log file and opens a new log file with the next sequence number.
If general query logging or slow query logging to a log file is enabled, the server closes and reopens the log file.
If the server was started with the
--log-erroroption to cause the error log to be written to a file, the server closes and reopens the log file.
Execution of log-flushing statements or commands requires
connecting to the server using an account that has the
RELOAD privilege. On Unix and
Unix-like systems, another way to flush the logs is to send a
signal to the server, which can be done by root
or the account that owns the server process. (See
Section 4.10, “Unix Signal Handling in MySQL”.) Signals enable log
flushing to be performed without having to connect to the server:
A
SIGHUPsignal flushes all the logs. However,SIGHUPhas additional effects other than log flushing that might be undesirable.As of MySQL 8.0.19,
SIGUSR1causes the server to flush the error log, general query log, and slow query log. If you are interested in flushing only those logs,SIGUSR1can be used as a more “lightweight” signal that does not have theSIGHUPeffects that are unrelated to logs.
As mentioned previously, flushing the binary log creates a new
binary log file, whereas flushing the general query log, slow
query log, or error log just closes and reopens the log file. For
the latter logs, to cause a new log file to be created on Unix,
rename the current log file first before flushing it. At flush
time, the server opens the new log file with the original name.
For example, if the general query log, slow query log, and error
log files are named mysql.log,
mysql-slow.log, and
err.log, you can use a series of commands
like this from the command line:
cd mysql-data-directory
mv mysql.log mysql.log.old
mv mysql-slow.log mysql-slow.log.old
mv err.log err.log.old
mysqladmin flush-logs
On Windows, use rename rather than mv.
At this point, you can make a backup of
mysql.log.old,
mysql-slow.log.old, and
err.log.old, then remove them from disk.
To rename the general query log or slow query log at runtime, first connect to the server and disable the log:
SET GLOBAL general_log = 'OFF'; SET GLOBAL slow_query_log = 'OFF';
With the logs disabled, rename the log files externally (for example, from the command line). Then enable the logs again:
SET GLOBAL general_log = 'ON'; SET GLOBAL slow_query_log = 'ON';
This method works on any platform and does not require a server restart.
For the server to recreate a given log file after you have
renamed the file externally, the file location must be writable
by the server. This may not always be the case. For example, on
Linux, the server might write the error log as
/var/log/mysqld.log, where
/var/log is owned by
root and not writable by
mysqld. In this case, log-flushing operations
fail to create a new log file.
To handle this situation, you must manually create the new log
file with the proper ownership after renaming the original log
file. For example, execute these commands as
root:
mv /var/log/mysqld.log /var/log/mysqld.log.old install -omysql -gmysql -m0644 /dev/null /var/log/mysqld.log
MySQL Server includes a component-based infrastructure for extending server capabilities. A component provides services that are available to the server and other components. (With respect to service use, the server is a component, equal to other components.) Components interact with each other only through the services they provide.
MySQL distributions include several components that implement server extensions:
Components for configuring error logging. See Section 5.4.2, “The Error Log”, and Section 5.5.3, “Error Log Components”.
A component for checking passwords. See Section 6.4.3, “The Password Validation Component”.
A component that enables applications to add their own message events to the audit log. See Section 6.4.6, “The Audit Message Component”.
A component that implements a user-defined function for accessing query attributes. See Section 9.6, “Query Attributes”.
System and status variables implemented by a component are exposed
when the component is installed and have names that begin with a
component-specific prefix. For example, the
log_filter_dragnet error log filter component
implements a system variable named
log_error_filter_rules, the full name of which is
dragnet.log_error_filter_rules. To
refer to this variable, use the full name.
The following sections describe how to install and uninstall components, and how to determine at runtime which components are installed and obtain information about them.
For information about the internal implementation of components, see the MySQL Server Doxygen documentation, available at https://dev.mysql.com/doc/index-other.html. For example, if you intend to write your own components, this information is important for understanding how components work.
Components must be loaded into the server before they can be used. MySQL supports manual component loading at runtime and automatic loading during server startup.
While a component is loaded, information about it is available as described in Section 5.5.2, “Obtaining Component Information”.
The INSTALL COMPONENT and
UNINSTALL COMPONENT SQL statements
enable component loading and unloading. For example:
INSTALL COMPONENT 'file://component_validate_password'; UNINSTALL COMPONENT 'file://component_validate_password';
A loader service handles component loading and unloading, and also
registers loaded components in the
mysql.component system table.
The SQL statements for component manipulation affect server
operation and the mysql.component system table
as follows:
INSTALL COMPONENTloads components into the server. The components become active immediately. The loader service also registers loaded components in themysql.componentsystem table. For subsequent server restarts, the loader service loads any components listed inmysql.componentduring the startup sequence. This occurs even if the server is started with the--skip-grant-tablesoption.UNINSTALL COMPONENTdeactivates components and unloads them from the server. The loader service also unregisters the components from themysql.componentsystem table so that the server no longer loads them during its startup sequence for subsequent restarts.
Compared to the corresponding INSTALL
PLUGIN statement for server plugins, the
INSTALL COMPONENT statement for
components offers the significant advantage that it is not
necessary to know any platform-specific file name suffix for
naming the component. This means that a given
INSTALL COMPONENT statement can be
executed uniformly across platforms.
A component when installed may also automatically install related user-defined functions (UDFs). If so, the component when uninstalled also automatically uninstalls those UDFs.
The mysql.component sytem table contains
information about currently loaded components and shows which
components have been registered using INSTALL
COMPONENT. To see which components are installed, use
this statement:
SELECT * FROM mysql.component;
This section describes the characteristics of individual error log components. For general information about configuring error logging, see Section 5.4.2, “The Error Log”.
A log component can be a filter or a sink:
A filter processes log events, to add, remove, or modify event fields, or to delete events entirely. The resulting events pass to the next log component in the list of enabled components.
A sink is a destination (writer) for log events. Typically, a sink processes log events into log messages that have a particular format and writes these messages to its associated output, such as a file or the system log. A sink may also write to the Performance Schema
error_logtable; see Section 27.12.19.1, “The error_log Table”. Events pass unmodified to the next log component in the list of enabled components (that is, although a sink formats events to produce output messages, it does not modify events as they pass internally to the next component).
The log_error_services system
variable value lists the enabled log components. Components not
named in the list are disabled.
The following sections describe individual log components, grouped by component type:
Component descriptions include these types of information:
The component name and intended purpose.
Whether the component is built in or must be loaded. For a loadable component, the description specifies the URN to use to load and unload the component with the
INSTALL COMPONENTandUNINSTALL COMPONENTstatements.Whether the component can be listed multiple times in the
log_error_servicesvalue.For a sink component, the destination to which the component writes output.
For a sink component, whether it supports an interface to the Performance Schema
error_logtable.
Error log filter components implement filtering of error log events. If no filter component is enabled, no filtering occurs.
Any enabled filter component affects log events only for
components listed later in the
log_error_services value. In
particular, for any log sink component listed in
log_error_services earlier than
any filter component, no log event filtering occurs.
The log_filter_internal Component
Purpose: Implements filtering based on log event priority and error code, in combination with the
log_error_verbosityandlog_error_suppression_listsystem variables. See Section 5.4.2.5, “Priority-Based Error Log Filtering (log_filter_internal)”.URN: This component is built in and need not be loaded with
INSTALL COMPONENTbefore use.Multiple uses permitted: No.
If log_filter_internal is disabled,
log_error_verbosity and
log_error_suppression_list have
no effect.
The log_filter_dragnet Component
Purpose: Implements filtering based on the rules defined by the
dragnet.log_error_filter_rulessystem variable setting. See Section 5.4.2.6, “Rule-Based Error Log Filtering (log_filter_dragnet)”.URN:
file://component_log_filter_dragnetMultiple uses permitted: No.
Error log sink components are writers that implement error log output. If no sink component is enabled, no log output occurs.
Some sink component descriptions refer to the default error log
destination. This is the console or a file and is indicated by
the value of the log_error
system variable, determined as described in
Section 5.4.2.2, “Default Error Log Destination Configuration”.
The log_sink_internal Component
Purpose: Implements traditional error log message output format.
URN: This component is built in and need not be loaded with
INSTALL COMPONENTbefore use.Multiple uses permitted: No.
Output destination: Writes to the default error log destination.
Performance Schema support: Writes to the
error_logtable. Provides a parser for reading error log files created by previous server instances.
The log_sink_json Component
Purpose: Implements JSON-format error logging. See Section 5.4.2.7, “Error Logging in JSON Format”.
URN:
file://component_log_sink_jsonMultiple uses permitted: Yes.
Output destination: This sink determines its output destination based on the default error log destination, which is given by the
log_errorsystem variable:If
log_errornames a file, the sink bases output file naming on that file name, plus a numbered.suffix, withNN.jsonNNstarting at 00. For example, iflog_errorisfile_name, successive instances oflog_sink_jsonnamed in thelog_error_servicesvalue write tofile_name.00.jsonfile_name.01.jsonIf
log_errorisstderr, the sink writes to the console. Iflog_sink_jsonis named multiple times in thelog_error_servicesvalue, they all write to the console, which is likely not useful.
Performance Schema support: Writes to the
error_logtable. Provides a parser for reading error log files created by previous server instances.
The log_sink_syseventlog Component
Purpose: Implements error logging to the system log. This is the Event Log on Windows, and
syslogon Unix and Unix-like systems. See Section 5.4.2.8, “Error Logging to the System Log”.URN:
file://component_log_sink_syseventlogMultiple uses permitted: No.
Output destination: Writes to the system log. Does not use the default error log destination.
Performance Schema support: Does not write to the
error_logtable. Does not provide a parser for reading error log files created by previous server instances.
The log_sink_test Component
Purpose: Intended for internal use in writing test cases, not for production use.
URN:
file://component_log_sink_test
Sink properties such as whether multiple uses are permitted and
the output destination are not specified for
log_sink_test because, as mentioned, it is
for internal use. As such, its behavior is subject to change at
any time.
As of MySQL 8.0.23, a a component service provides access to query
attributes (see Section 9.6, “Query Attributes”). The
query_attributes component uses this service to
provide access to query attributes within SQL statements.
Purpose: Implements the
mysql_query_attribute_string()user-defined function that takes an attribute name argument and returns the attribute value as a string, orNULLif the attribute does not exist.URN:
file://component_query_attributes
Developers who wish to incorporate the same query-attribute
component service used by query_attributes
should consult the mysql_query_attributes.h
file in a MySQL source distribution.
MySQL supports an plugin API that enables creation of server
plugins. Plugins can be loaded at server startup, or loaded and
unloaded at runtime without restarting the server. The plugins
supported by this interface include, but are not limited to, storage
engines, INFORMATION_SCHEMA tables, full-text
parser plugins, and server extensions.
MySQL distributions include several plugins that implement server extensions:
Plugins for authenticating attempts by clients to connect to MySQL Server. Plugins are available for several authentication protocols. See Section 6.2.17, “Pluggable Authentication”.
A connection-control plugin that enables administrators to introduce an increasing delay after a certain number of consecutive failed client connection attempts. See Section 6.4.2, “The Connection-Control Plugins”.
A password-validation plugin implements password strength policies and assesses the strength of potential passwords. See Section 6.4.3, “The Password Validation Component”.
Semisynchronous replication plugins implement an interface to replication capabilities that permit the source to proceed as long as at least one replica has responded to each transaction. See Section 17.4.10, “Semisynchronous Replication”.
Group Replication enables you to create a highly available distributed MySQL service across a group of MySQL server instances, with data consistency, conflict detection and resolution, and group membership services all built-in. See Chapter 18, Group Replication.
MySQL Enterprise Edition includes a thread pool plugin that manages connection threads to increase server performance by efficiently managing statement execution threads for large numbers of client connections. See Section 5.6.3, “MySQL Enterprise Thread Pool”.
MySQL Enterprise Edition includes an audit plugin for monitoring and logging of connection and query activity. See Section 6.4.5, “MySQL Enterprise Audit”.
MySQL Enterprise Edition includes a firewall plugin that implements an application-level firewall to enable database administrators to permit or deny SQL statement execution based on matching against allowlists of accepted statement patterns. See Section 6.4.7, “MySQL Enterprise Firewall”.
Query rewrite plugins examine statements received by MySQL Server and possibly rewrite them before the server executes them. See Section 5.6.4, “The Rewriter Query Rewrite Plugin”, and Section 5.6.5, “The ddl_rewriter Plugin”.
Version Tokens enables creation of and synchronization around server tokens that applications can use to prevent accessing incorrect or out-of-date data. Version Tokens is based on a plugin library that implements a
version_tokensplugin and a set of user-defined functions. See Section 5.6.6, “Version Tokens”.Keyring plugins provide secure storage for sensitive information. See Section 6.4.4, “The MySQL Keyring”.
X Plugin extends MySQL Server to be able to function as a document store. Running X Plugin enables MySQL Server to communicate with clients using the X Protocol, which is designed to expose the ACID compliant storage abilities of MySQL as a document store. See Section 20.5, “X Plugin”.
Clone permits cloning
InnoDBdata from a local or remote MySQL server instance. See Section 5.6.7, “The Clone Plugin”.Test framework plugins test server services. For information about these plugins, see the Plugins for Testing Plugin Services section of the MySQL Server Doxygen documentation, available at https://dev.mysql.com/doc/index-other.html.
The following sections describe how to install and uninstall plugins, and how to determine at runtime which plugins are installed and obtain information about them. For information about writing plugins, see The MySQL Plugin API.
Server plugins must be loaded into the server before they can be used. MySQL supports plugin loading at server startup and runtime. It is also possible to control the activation state of loaded plugins at startup, and to unload them at runtime.
While a plugin is loaded, information about it is available as described in Section 5.6.2, “Obtaining Server Plugin Information”.
Before a server plugin can be used, it must be installed using
one of the following methods. In the descriptions,
plugin_name stands for a plugin name
such as innodb, csv, or
validate_password.
Built-in Plugins
A built-in plugin is known by the server automatically. By
default, the server enables the plugin at startup. Some built-in
plugins permit this to be changed with the
--
option.
plugin_name[=activation_state]
Plugins Registered in the mysql.plugin System Table
The mysql.plugin system table serves as a
registry of plugins (other than built-in plugins, which need not
be registered). During the normal startup sequence, the server
loads plugins registered in the table. By default, for a plugin
loaded from the mysql.plugin table, the
server also enables the plugin. This can be changed with the
--
option.
plugin_name[=activation_state]
If the server is started with the
--skip-grant-tables option,
plugins registered in the mysql.plugin table
are not loaded and are unavailable.
Plugins Named with Command-Line Options
A plugin located in a plugin library file can be loaded at
server startup with the
--plugin-load,
--plugin-load-add, or
--early-plugin-load option.
Normally, for a plugin loaded at startup, the server also
enables the plugin. This can be changed with the
--
option.
plugin_name[=activation_state]
The --plugin-load and
--plugin-load-add options load
plugins after built-in plugins and storage engines have
initialized during the server startup sequence. The
--early-plugin-load option is
used to load plugins that must be available prior to
initialization of built-in plugins and storage engines.
The value of each plugin-loading option is a semicolon-separated
list of
name=plugin_library
and plugin_library values. Each
name is the name of a plugin to load,
and plugin_library is the name of the
library file that contains the plugin code. If a plugin library
is named without any preceding plugin name, the server loads all
plugins in the library. The server looks for plugin library
files in the directory named by the
plugin_dir system variable.
Plugin-loading options do not register any plugin in the
mysql.plugin table. For subsequent restarts,
the server loads the plugin again only if
--plugin-load,
--plugin-load-add, or
--early-plugin-load is given
again. That is, the option produces a one-time
plugin-installation operation that persists for a single server
invocation.
--plugin-load,
--plugin-load-add, and
--early-plugin-load enable
plugins to be loaded even when
--skip-grant-tables is given
(which causes the server to ignore the
mysql.plugin table).
--plugin-load,
--plugin-load-add, and
--early-plugin-load also enable
plugins to be loaded at startup that cannot be loaded at
runtime.
The --plugin-load-add option
complements the --plugin-load
option:
Each instance of
--plugin-loadresets the set of plugins to load at startup, whereas--plugin-load-addadds a plugin or plugins to the set of plugins to be loaded without resetting the current set. Consequently, if multiple instances of--plugin-loadare specified, only the last one takes effect. With multiple instances of--plugin-load-add, all of them take effect.The argument format is the same as for
--plugin-load, but multiple instances of--plugin-load-addcan be used to avoid specifying a large set of plugins as a single long unwieldy--plugin-loadargument.--plugin-load-addcan be given in the absence of--plugin-load, but any instance of--plugin-load-addthat appears before--plugin-loadhas no effect because--plugin-loadresets the set of plugins to load.
For example, these options:
--plugin-load=x --plugin-load-add=y
are equivalent to these options:
--plugin-load-add=x --plugin-load-add=y
and are also equivalent to this option:
--plugin-load="x;y"
But these options:
--plugin-load-add=y --plugin-load=x
are equivalent to this option:
--plugin-load=x
Plugins Installed with the INSTALL PLUGIN Statement
A plugin located in a plugin library file can be loaded at
runtime with the INSTALL PLUGIN
statement. The statement also registers the plugin in the
mysql.plugin table to cause the server to
load it on subsequent restarts. For this reason,
INSTALL PLUGIN requires the
INSERT privilege for the
mysql.plugin table.
The plugin library file base name depends on your platform.
Common suffixes are .so for Unix and
Unix-like systems, .dll for Windows.
Example: The --plugin-load-add
option installs a plugin at server startup. To install a plugin
named myplugin from a plugin library file
named somepluglib.so, use these lines in a
my.cnf file:
[mysqld] plugin-load-add=myplugin=somepluglib.so
In this case, the plugin is not registered in
mysql.plugin. Restarting the server without
the --plugin-load-add option
causes the plugin not to be loaded at startup.
Alternatively, the INSTALL PLUGIN
statement causes the server to load the plugin code from the
library file at runtime:
INSTALL PLUGIN myplugin SONAME 'somepluglib.so';
INSTALL PLUGIN also causes
“permanent” plugin registration: The plugin is
listed in the mysql.plugin table to ensure
that the server loads it on subsequent restarts.
Many plugins can be loaded either at server startup or at
runtime. However, if a plugin is designed such that it must be
loaded and initialized during server startup, attempts to load
it at runtime using INSTALL
PLUGIN produce an error:
mysql> INSTALL PLUGIN myplugin SONAME 'somepluglib.so';
ERROR 1721 (HY000): Plugin 'myplugin' is marked as not dynamically
installable. You have to stop the server to install it.
In this case, you must use
--plugin-load,
--plugin-load-add, or
--early-plugin-load.
If a plugin is named both using a
--plugin-load,
--plugin-load-add, or
--early-plugin-load option and
(as a result of an earlier INSTALL
PLUGIN statement) in the
mysql.plugin table, the server starts but
writes these messages to the error log:
[ERROR] Function 'plugin_name' already exists [Warning] Couldn't load plugin named 'plugin_name' with soname 'plugin_object_file'.
If the server knows about a plugin when it starts (for example,
because the plugin is named using a
--plugin-load-add option or is
registered in the mysql.plugin table), the
server loads and enables the plugin by default. It is possible
to control activation state for such a plugin using a
--
startup option, where plugin_name[=activation_state]plugin_name is
the name of the plugin to affect, such as
innodb, csv, or
validate_password. As with other options,
dashes and underscores are interchangeable in option names.
Also, activation state values are not case-sensitive. For
example, --my_plugin=ON and
--my-plugin=on are equivalent.
--plugin_name=OFFTells the server to disable the plugin. This may not be possible for certain built-in plugins, such as
mysql_native_password.--plugin_name[=ON]Tells the server to enable the plugin. (Specifying the option as
--without a value has the same effect.) If the plugin fails to initialize, the server runs with the plugin disabled.plugin_name--plugin_name=FORCETells the server to enable the plugin, but if plugin initialization fails, the server does not start. In other words, this option forces the server to run with the plugin enabled or not at all.
--plugin_name=FORCE_PLUS_PERMANENTLike
FORCE, but in addition prevents the plugin from being unloaded at runtime. If a user attempts to do so withUNINSTALL PLUGIN, an error occurs.
Plugin activation states are visible in the
LOAD_OPTION column of the
INFORMATION_SCHEMA.PLUGINS table.
Suppose that CSV,
BLACKHOLE, and ARCHIVE are
built-in pluggable storage engines and that you want the server
to load them at startup, subject to these conditions: The server
is permitted to run if CSV initialization
fails, must require that BLACKHOLE
initialization succeeds, and should disable
ARCHIVE. To accomplish that, use these lines
in an option file:
[mysqld] csv=ON blackhole=FORCE archive=OFF
The
--enable-
option format is a synonym for
plugin_name--.
The
plugin_name=ON--disable-
and
plugin_name--skip-
option formats are synonyms for
plugin_name--.
plugin_name=OFF
If a plugin is disabled, either explicitly with
OFF or implicitly because it was enabled with
ON but fails to initialize, aspects of server
operation requiring the plugin change. For example, if the
plugin implements a storage engine, existing tables for the
storage engine become inaccessible, and attempts to create new
tables for the storage engine result in tables that use the
default storage engine unless the
NO_ENGINE_SUBSTITUTION SQL
mode is enabled to cause an error to occur instead.
Disabling a plugin may require adjustment to other options. For
example, if you start the server using
--skip-innodb
to disable InnoDB, other
innodb_
options likely also need to be omitted at startup. In addition,
because xxxInnoDB is the default
storage engine, it cannot start unless you specify another
available storage engine with
--default_storage_engine. You
must also set
--default_tmp_storage_engine.
At runtime, the UNINSTALL PLUGIN
statement disables and uninstalls a plugin known to the server.
The statement unloads the plugin and removes it from the
mysql.plugin system table, if it is
registered there. For this reason,
UNINSTALL PLUGIN statement
requires the DELETE privilege for
the mysql.plugin table. With the plugin no
longer registered in the table, the server does not load the
plugin during subsequent restarts.
UNINSTALL PLUGIN can unload a
plugin regardless of whether it was loaded at runtime with
INSTALL PLUGIN or at startup with
a plugin-loading option, subject to these conditions:
It cannot unload plugins that are built in to the server. These can be identified as those that have a library name of
NULLin the output fromINFORMATION_SCHEMA.PLUGINSorSHOW PLUGINS.It cannot unload plugins for which the server was started with
--, which prevents plugin unloading at runtime. These can be identified from theplugin_name=FORCE_PLUS_PERMANENTLOAD_OPTIONcolumn of theINFORMATION_SCHEMA.PLUGINStable.
To uninstall a plugin that currently is loaded at server startup with a plugin-loading option, use this procedure.
Remove from the
my.cnffile any options and system variables related to the plugin. If any plugin system variables were persisted to themysqld-auto.cnffile, remove them usingRESET PERSISTfor each one to remove it.var_nameRestart the server.
Plugins normally are installed using either a plugin-loading option at startup or with
INSTALL PLUGINat runtime, but not both. However, removing options for a plugin from themy.cnffile may not be sufficient to uninstall it if at some pointINSTALL PLUGINhas also been used. If the plugin still appears in the output fromINFORMATION_SCHEMA.PLUGINSorSHOW PLUGINS, useUNINSTALL PLUGINto remove it from themysql.plugintable. Then restart the server again.
There are several ways to determine which plugins are installed in the server:
The
INFORMATION_SCHEMA.PLUGINStable contains a row for each loaded plugin. Any that have aPLUGIN_LIBRARYvalue ofNULLare built in and cannot be unloaded.mysql>
SELECT * FROM INFORMATION_SCHEMA.PLUGINS\G*************************** 1. row *************************** PLUGIN_NAME: binlog PLUGIN_VERSION: 1.0 PLUGIN_STATUS: ACTIVE PLUGIN_TYPE: STORAGE ENGINE PLUGIN_TYPE_VERSION: 50158.0 PLUGIN_LIBRARY: NULL PLUGIN_LIBRARY_VERSION: NULL PLUGIN_AUTHOR: Oracle Corporation PLUGIN_DESCRIPTION: This is a pseudo storage engine to represent the binlog in a transaction PLUGIN_LICENSE: GPL LOAD_OPTION: FORCE ... *************************** 10. row *************************** PLUGIN_NAME: InnoDB PLUGIN_VERSION: 1.0 PLUGIN_STATUS: ACTIVE PLUGIN_TYPE: STORAGE ENGINE PLUGIN_TYPE_VERSION: 50158.0 PLUGIN_LIBRARY: ha_innodb_plugin.so PLUGIN_LIBRARY_VERSION: 1.0 PLUGIN_AUTHOR: Oracle Corporation PLUGIN_DESCRIPTION: Supports transactions, row-level locking, and foreign keys PLUGIN_LICENSE: GPL LOAD_OPTION: ON ...The
SHOW PLUGINSstatement displays a row for each loaded plugin. Any that have aLibraryvalue ofNULLare built in and cannot be unloaded.mysql>
SHOW PLUGINS\G*************************** 1. row *************************** Name: binlog Status: ACTIVE Type: STORAGE ENGINE Library: NULL License: GPL ... *************************** 10. row *************************** Name: InnoDB Status: ACTIVE Type: STORAGE ENGINE Library: ha_innodb_plugin.so License: GPL ...The
mysql.plugintable shows which plugins have been registered withINSTALL PLUGIN. The table contains only plugin names and library file names, so it does not provide as much information as thePLUGINStable or theSHOW PLUGINSstatement.
MySQL Enterprise Thread Pool is an extension included in MySQL Enterprise Edition, a commercial product. To learn more about commercial products, https://www.mysql.com/products/.
MySQL Enterprise Edition includes MySQL Enterprise Thread Pool, implemented using a server plugin. The default thread-handling model in MySQL Server executes statements using one thread per client connection. As more clients connect to the server and execute statements, overall performance degrades. The thread pool plugin provides an alternative thread-handling model designed to reduce overhead and improve performance. The plugin implements a thread pool that increases server performance by efficiently managing statement execution threads for large numbers of client connections.
The thread pool addresses several problems of the model that uses one thread per connection:
Too many thread stacks make CPU caches almost useless in highly parallel execution workloads. The thread pool promotes thread stack reuse to minimize the CPU cache footprint.
With too many threads executing in parallel, context switching overhead is high. This also presents a challenge to the operating system scheduler. The thread pool controls the number of active threads to keep the parallelism within the MySQL server at a level that it can handle and that is appropriate for the server host on which MySQL is executing.
Too many transactions executing in parallel increases resource contention. In
InnoDB, this increases the time spent holding central mutexes. The thread pool controls when transactions start to ensure that not too many execute in parallel.
Additional Resources
Section A.15, “MySQL 8.0 FAQ: MySQL Enterprise Thread Pool”
MySQL Enterprise Thread Pool comprises these elements:
A plugin library file implements a plugin for the thread pool code as well as several associated monitoring tables that provide information about thread pool operation:
As of MySQL 8.0.14, the monitoring tables are Performance Schema tables; see Section 27.12.16, “Performance Schema Thread Pool Tables”.
Prior to MySQL 8.0.14, the monitoring tables are
INFORMATION_SCHEMAtables; see Section 26.52, “INFORMATION_SCHEMA Thread Pool Tables”.The
INFORMATION_SCHEMAtables now are deprecated; expect them to be removed in a future version of MySQL. Applications should transition away from theINFORMATION_SCHEMAtables to the Performance Schema tables. For example, if an application uses this query:SELECT * FROM INFORMATION_SCHEMA.TP_THREAD_STATE;
The application should use this query instead:
SELECT * FROM performance_schema.tp_thread_state;
NoteIf you do not load all the monitoring tables, some or all MySQL Enterprise Monitor thread pool graphs may be empty.
For a detailed description of how the thread pool works, see Section 5.6.3.3, “Thread Pool Operation”.
Several system variables are related to the thread pool. The
thread_handlingsystem variable has a value ofloaded-dynamicallywhen the server successfully loads the thread pool plugin.The other related system variables are implemented by the thread pool plugin and are not available unless it is enabled. For information about using these variables, see Section 5.6.3.3, “Thread Pool Operation”, and Section 5.6.3.4, “Thread Pool Tuning”.
The Performance Schema has instruments that expose information about the thread pool and may be used to investigate operational performance. To identify them, use this query:
SELECT * FROM performance_schema.setup_instruments WHERE NAME LIKE '%thread_pool%';
For more information, see Chapter 27, MySQL Performance Schema.
This section describes how to install MySQL Enterprise Thread Pool. For general information about installing plugins, see Section 5.6.1, “Installing and Uninstalling Plugins”.
To be usable by the server, the plugin library file must be
located in the MySQL plugin directory (the directory named by
the plugin_dir system
variable). If necessary, configure the plugin directory location
by setting the value of
plugin_dir at server startup.
The plugin library file base name is
thread_pool. The file name suffix differs per
platform (for example, .so for Unix and
Unix-like systems, .dll for Windows).
In MySQL 8.0.14 and higher, the thread pool monitoring tables
are Performance Schema tables that are loaded and unloaded
along with the thread pool plugin. The
INFORMATION_SCHEMA versions of the tables
are deprecated but still available; they are installed per the
instructions in
Thread Pool Installation Prior to MySQL 8.0.14.
To enable thread pool capability, load the plugin by starting
the server with the
--plugin-load-add option. To do
this, put these lines in the server
my.cnf file, adjusting the
.so suffix for your platform as
necessary:
[mysqld] plugin-load-add=thread_pool.so
To verify plugin installation, examine the
INFORMATION_SCHEMA.PLUGINS table
or use the SHOW PLUGINS
statement (see
Section 5.6.2, “Obtaining Server Plugin Information”). For example:
mysql>SELECT PLUGIN_NAME, PLUGIN_STATUSFROM INFORMATION_SCHEMA.PLUGINSWHERE PLUGIN_NAME LIKE 'thread%';+-----------------------+---------------+ | PLUGIN_NAME | PLUGIN_STATUS | +-----------------------+---------------+ | thread_pool | ACTIVE | +-----------------------+---------------+
To verify that the Performance Schema monitoring tables are
available, examine the
INFORMATION_SCHEMA.TABLES table
or use the SHOW TABLES
statement. For example:
mysql>SELECT TABLE_NAMEFROM INFORMATION_SCHEMA.TABLESWHERE TABLE_SCHEMA = 'performance_schema'AND TABLE_NAME LIKE 'tp%';+-----------------------+ | TABLE_NAME | +-----------------------+ | tp_thread_group_state | | tp_thread_group_stats | | tp_thread_state | +-----------------------+
If the server loads the thread pool plugin successfully, it
sets the thread_handling system variable to
loaded-dynamically.
If the plugin fails to initialize, check the server error log for diagnostic messages.
Prior to MySQL 8.0.14, the thread pool monitoring tables are plugins separate from the thread pool plugin and can be installed separately.
To enable thread pool capability, load the plugins to be used
by starting the server with the
--plugin-load-add option. For
example, if you name only the plugin library file, the server
loads all plugins that it contains (that is, the thread pool
plugin and all the INFORMATION_SCHEMA
tables). To do this, put these lines in the server
my.cnf file, adjusting the
.so suffix for your platform as
necessary:
[mysqld] plugin-load-add=thread_pool.so
That is equivalent to loading all thread pool plugins by naming them individually:
[mysqld] plugin-load-add=thread_pool=thread_pool.so plugin-load-add=tp_thread_state=thread_pool.so plugin-load-add=tp_thread_group_state=thread_pool.so plugin-load-add=tp_thread_group_stats=thread_pool.so
If desired, you can load individual plugins from the library
file. To load the thread pool plugin but not the
INFORMATION_SCHEMA tables, use an option
like this:
[mysqld] plugin-load-add=thread_pool=thread_pool.so
To load the thread pool plugin and only the
TP_THREAD_STATE
INFORMATION_SCHEMA table, use options like
this:
[mysqld] plugin-load-add=thread_pool=thread_pool.so plugin-load-add=tp_thread_state=thread_pool.so
To verify plugin installation, examine the
INFORMATION_SCHEMA.PLUGINS table
or use the SHOW PLUGINS
statement (see
Section 5.6.2, “Obtaining Server Plugin Information”). For example:
mysql>SELECT PLUGIN_NAME, PLUGIN_STATUSFROM INFORMATION_SCHEMA.PLUGINSWHERE PLUGIN_NAME LIKE 'thread%' OR PLUGIN_NAME LIKE 'tp%';+-----------------------+---------------+ | PLUGIN_NAME | PLUGIN_STATUS | +-----------------------+---------------+ | thread_pool | ACTIVE | | TP_THREAD_STATE | ACTIVE | | TP_THREAD_GROUP_STATE | ACTIVE | | TP_THREAD_GROUP_STATS | ACTIVE | +-----------------------+---------------+
If the server loads the thread pool plugin successfully, it
sets the thread_handling system variable to
loaded-dynamically.
If a plugin fails to initialize, check the server error log for diagnostic messages.
The thread pool consists of a number of thread groups, each of which manages a set of client connections. As connections are established, the thread pool assigns them to thread groups in round-robin fashion.
The thread pool exposes system variables that may be used to configure its operation:
thread_pool_algorithm: The concurrency algorithm to use for scheduling.thread_pool_high_priority_connection: How to schedule statement execution for a session.thread_pool_max_active_query_threads: How many active threads per group to permit.thread_pool_max_unused_threads: How many sleeping threads to permit.thread_pool_prio_kickup_timer: How long before the thread pool moves a statement awaiting execution from the low-priority queue to the high-priority queue.thread_pool_size: The number of thread groups in the thread pool. This is the most important parameter controlling thread pool performance.thread_pool_stall_limit: The time before an executing statement is considered to be stalled.
To configure the number of thread groups, use the
thread_pool_size system
variable. The default number of groups is 16. For guidelines on
setting this variable, see Section 5.6.3.4, “Thread Pool Tuning”.
The maximum number of threads per group is 4096 (or 4095 on some systems where one thread is used internally).
The thread pool separates connections and threads, so there is no fixed relationship between connections and the threads that execute statements received from those connections. This differs from the default thread-handling model that associates one thread with one connection such that a given thread executes all statements from its connection.
By default, the thread pool tries to ensure a maximum of one thread executing in each group at any time, but sometimes permits more threads to execute temporarily for best performance:
Each thread group has a listener thread that listens for incoming statements from the connections assigned to the group. When a statement arrives, the thread group either begins executing it immediately or queues it for later execution:
Immediate execution occurs if the statement is the only one received and no statements are queued or currently executing.
Queuing occurs if the statement cannot begin executing immediately.
If immediate execution occurs, the listener thread performs it. (This means that temporarily no thread in the group is listening.) If the statement finishes quickly, the executing thread returns to listening for statements. Otherwise, the thread pool considers the statement stalled and starts another thread as a listener thread (creating it if necessary). To ensure that no thread group becomes blocked by stalled statements, the thread pool has a background thread that regularly monitors thread group states.
By using the listening thread to execute a statement that can begin immediately, there is no need to create an additional thread if the statement finishes quickly. This ensures the most efficient execution possible in the case of a low number of concurrent threads.
When the thread pool plugin starts, it creates one thread per group (the listener thread), plus the background thread. Additional threads are created as necessary to execute statements.
The value of the
thread_pool_stall_limitsystem variable determines the meaning of “finishes quickly” in the previous item. The default time before threads are considered stalled is 60ms but can be set to a maximum of 6s. This parameter is configurable to enable you to strike a balance appropriate for the server work load. Short wait values permit threads to start more quickly. Short values are also better for avoiding deadlock situations. Long wait values are useful for workloads that include long-running statements, to avoid starting too many new statements while the current ones execute.If
thread_pool_max_active_query_threadsis 0, the default algorithm applies as just described for determining the maximum number of active threads per group. The default algorithm takes stalled threads into account and may temporarily permit more active threads. Ifthread_pool_max_active_query_threadsis greater than 0, it places a limit on the number of active threads per group.The thread pool focuses on limiting the number of concurrent short-running statements. Before an executing statement reaches the stall time, it prevents other statements from beginning to execute. If the statement executes past the stall time, it is permitted to continue but no longer prevents other statements from starting. In this way, the thread pool tries to ensure that in each thread group there is never more than one short-running statement, although there might be multiple long-running statements. It is undesirable to let long-running statements prevent other statements from executing because there is no limit on the amount of waiting that might be necessary. For example, on a replication source server, a thread that is sending binary log events to a replica effectively runs forever.
A statement becomes blocked if it encounters a disk I/O operation or a user level lock (row lock or table lock). The block would cause the thread group to become unused, so there are callbacks to the thread pool to ensure that the thread pool can immediately start a new thread in this group to execute another statement. When a blocked thread returns, the thread pool permits it to restart immediately.
There are two queues, a high-priority queue and a low-priority queue. The first statement in a transaction goes to the low-priority queue. Any following statements for the transaction go to the high-priority queue if the transaction is ongoing (statements for it have begun executing), or to the low-priority queue otherwise. Queue assignment can be affected by enabling the
thread_pool_high_priority_connectionsystem variable, which causes all queued statements for a session to go into the high-priority queue.Statements for a nontransactional storage engine, or a transactional engine if
autocommitis enabled, are treated as low-priority statements because in this case each statement is a transaction. Thus, given a mix of statements forInnoDBandMyISAMtables, the thread pool prioritizes those forInnoDBover those forMyISAMunlessautocommitis enabled. Withautocommitenabled, all statements have low priority.When the thread group selects a queued statement for execution, it first looks in the high-priority queue, then in the low-priority queue. If a statement is found, it is removed from its queue and begins to execute.
If a statement stays in the low-priority queue too long, the thread pool moves to the high-priority queue. The value of the
thread_pool_prio_kickup_timersystem variable controls the time before movement. For each thread group, a maximum of one statement per 10ms (100 per second) is moved from the low-priority queue to the high-priority queue.The thread pool reuses the most active threads to obtain a much better use of CPU caches. This is a small adjustment that has a great impact on performance.
While a thread executes a statement from a user connection, Performance Schema instrumentation accounts thread activity to the user connection. Otherwise, Performance Schema accounts activity to the thread pool.
Here are examples of conditions under which a thread group might have multiple threads started to execute statements:
One thread begins executing a statement, but runs long enough to be considered stalled. The thread group permits another thread to begin executing another statement even through the first thread is still executing.
One thread begins executing a statement, then becomes blocked and reports this back to the thread pool. The thread group permits another thread to begin executing another statement.
One thread begins executing a statement, becomes blocked, but does not report back that it is blocked because the block does not occur in code that has been instrumented with thread pool callbacks. In this case, the thread appears to the thread group to be still running. If the block lasts long enough for the statement to be considered stalled, the group permits another thread to begin executing another statement.
The thread pool is designed to be scalable across an increasing number of connections. It is also designed to avoid deadlocks that can arise from limiting the number of actively executing statements. It is important that threads that do not report back to the thread pool do not prevent other statements from executing and thus cause the thread pool to become deadlocked. Examples of such statements follow:
Long-running statements. These would lead to all resources used by only a few statements and they could prevent all others from accessing the server.
Binary log dump threads that read the binary log and send it to replicas. This is a kind of long-running “statement” that runs for a very long time, and that should not prevent other statements from executing.
Statements blocked on a row lock, table lock, sleep, or any other blocking activity that has not been reported back to the thread pool by MySQL Server or a storage engine.
In each case, to prevent deadlock, the statement is moved to the stalled category when it does not complete quickly, so that the thread group can permit another statement to begin executing. With this design, when a thread executes or becomes blocked for an extended time, the thread pool moves the thread to the stalled category and for the rest of the statement's execution, it does not prevent other statements from executing.
The maximum number of threads that can occur is the sum of
max_connections and
thread_pool_size. This can
happen in a situation where all connections are in execution
mode and an extra thread is created per group to listen for more
statements. This is not necessarily a state that happens often,
but it is theoretically possible.
This section provides guidelines on setting thread pool system variables for best performance, measured using a metric such as transactions per second.
thread_pool_size is the most
important parameter controlling thread pool performance. It can
be set only at server startup. Our experience in testing the
thread pool indicates the following:
If the primary storage engine is
InnoDB, the optimalthread_pool_sizesetting is likely to be between 16 and 36, with the most common optimal values tending to be from 24 to 36. We have not seen any situation where the setting has been optimal beyond 36. There may be special cases where a value smaller than 16 is optimal.For workloads such as DBT2 and Sysbench, the optimum for
InnoDBseems to be usually around 36. For very write-intensive workloads, the optimal setting can sometimes be lower.If the primary storage engine is
MyISAM, thethread_pool_sizesetting should be fairly low. Optimal performance is often seen with values from 4 to 8. Higher values tend to have a slightly negative but not dramatic impact on performance.
Another system variable,
thread_pool_stall_limit, is
important for handling of blocked and long-running statements.
If all calls that block the MySQL Server are reported to the
thread pool, it would always know when execution threads are
blocked. However, this may not always be true. For example,
blocks could occur in code that has not been instrumented with
thread pool callbacks. For such cases, the thread pool must be
able to identify threads that appear to be blocked. This is done
by means of a timeout that can be tuned using the
thread_pool_stall_limit system
variable, the value of which is measured in 10ms units. This
parameter ensures that the server does not become completely
blocked. The value of
thread_pool_stall_limit has an
upper limit of 6 seconds to prevent the risk of a deadlocked
server.
thread_pool_stall_limit also
enables the thread pool to handle long-running statements. If a
long-running statement was permitted to block a thread group,
all other connections assigned to the group would be blocked and
unable to start execution until the long-running statement
completed. In the worst case, this could take hours or even
days.
The value of
thread_pool_stall_limit should
be chosen such that statements that execute longer than its
value are considered stalled. Stalled statements generate a lot
of extra overhead since they involve extra context switches and
in some cases even extra thread creations. On the other hand,
setting the
thread_pool_stall_limit
parameter too high means that long-running statements block a
number of short-running statements for longer than necessary.
Short wait values permit threads to start more quickly. Short
values are also better for avoiding deadlock situations. Long
wait values are useful for workloads that include long-running
statements, to avoid starting too many new statements while the
current ones execute.
Suppose a server executes a workload where 99.9% of the
statements complete within 100ms even when the server is loaded,
and the remaining statements take between 100ms and 2 hours
fairly evenly spread. In this case, it would make sense to set
thread_pool_stall_limit to 10
(10 × 10ms = 100ms). The default value of 6 (60ms)
is suitable for servers that primarily execute very simple
statements.
The thread_pool_stall_limit
parameter can be changed at runtime to enable you to strike a
balance appropriate for the server work load. Assuming that the
tp_thread_group_stats table is
enabled, you can use the following query to determine the
fraction of executed statements that stalled:
SELECT SUM(STALLED_QUERIES_EXECUTED) / SUM(QUERIES_EXECUTED) FROM performance_schema.tp_thread_group_stats;
This number should be as low as possible. To decrease the
likelihood of statements stalling, increase the value of
thread_pool_stall_limit.
When a statement arrives, what is the maximum time it can be delayed before it actually starts executing? Suppose that the following conditions apply:
There are 200 statements queued in the low-priority queue.
There are 10 statements queued in the high-priority queue.
thread_pool_prio_kickup_timeris set to 10000 (10 seconds).thread_pool_stall_limitis set to 100 (1 second).
In the worst case, the 10 high-priority statements represent 10 transactions that continue executing for a long time. Thus, in the worst case, no statements can be moved to the high-priority queue because it always already contains statements awaiting execution. After 10 seconds, the new statement is eligible to be moved to the high-priority queue. However, before it can be moved, all the statements before it must be moved as well. This could take another 2 seconds because a maximum of 100 statements per second are moved to the high-priority queue. Now when the statement reaches the high-priority queue, there could potentially be many long-running statements ahead of it. In the worst case, every one of those becomes stalled and 1 second is required for each statement before the next statement is retrieved from the high-priority queue. Thus, in this scenario, it takes 222 seconds before the new statement starts executing.
This example shows a worst case for an application. How to handle it depends on the application. If the application has high requirements for the response time, it should most likely throttle users at a higher level itself. Otherwise, it can use the thread pool configuration parameters to set some kind of a maximum waiting time.
MySQL supports query rewrite plugins that can examine and possibly modify SQL statements received by the server before the server executes them. See Query Rewrite Plugins.
MySQL distributions include a postparse query rewrite plugin named
Rewriter and scripts for installing the plugin
and its associated elements. These elements work together to
provide statement-rewriting capability:
A server-side plugin named
Rewriterexamines statements and may rewrite them, based on its in-memory cache of rewrite rules.These statements are subject to rewriting:
Standalone statements and prepared statements are subject to rewriting. Statements occurring within view definitions or stored programs are not subject to rewriting.
The
Rewriterplugin uses a database namedquery_rewritecontaining a table namedrewrite_rules. The table provides persistent storage for the rules that the plugin uses to decide whether to rewrite statements. Users communicate with the plugin by modifying the set of rules stored in this table. The plugin communicates with users by setting themessagecolumn of table rows.The
query_rewritedatabase contains a stored procedure namedflush_rewrite_rules()that loads the contents of the rules table into the plugin.A user-defined function named
load_rewrite_rules()is used by theflush_rewrite_rules()stored procedure.The
Rewriterplugin exposes system variables that enable plugin configuration and status variables that provide runtime operational information.
The following sections describe how to install and use the
Rewriter plugin, and provide reference
information for its associated elements.
If installed, the Rewriter plugin involves
some overhead even when disabled. To avoid this overhead, do
not install the plugin unless you plan to use it.
To install or uninstall the Rewriter query
rewrite plugin, choose the appropriate script located in the
share directory of your MySQL installation:
install_rewriter.sql: Choose this script to install theRewriterplugin and its associated elements.uninstall_rewriter.sql: Choose this script to uninstall theRewriterplugin and its associated elements.
Run the chosen script as follows:
shell>mysql -u root -p < install_rewriter.sqlEnter password:(enter root password here)
The example here uses the
install_rewriter.sql installation script.
Substitute uninstall_rewriter.sql if you
are uninstalling the plugin.
Running an installation script should install and enable the plugin. To verify that, connect to the server and execute this statement:
mysql> SHOW GLOBAL VARIABLES LIKE 'rewriter_enabled';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| rewriter_enabled | ON |
+------------------+-------+
For usage instructions, see Section 5.6.4.2, “Using the Rewriter Query Rewrite Plugin”. For reference information, see Section 5.6.4.3, “Rewriter Query Rewrite Plugin Reference”.
To enable or disable the plugin, enable or disable the
rewriter_enabled system
variable. By default, the Rewriter plugin is
enabled when you install it (see
Section 5.6.4.1, “Installing or Uninstalling the Rewriter Query Rewrite Plugin”).
To set the initial plugin state explicitly, you can set the
variable at server startup. For example, to enable the plugin in
an option file, use these lines:
[mysqld] rewriter_enabled=ON
It is also possible to enable or disable the plugin at runtime:
SET GLOBAL rewriter_enabled = ON; SET GLOBAL rewriter_enabled = OFF;
Assuming that the Rewriter plugin is enabled,
it examines and possibly modifies each rewritable statement
received by the server. The plugin determines whether to rewrite
statements based on its in-memory cache of rewriting rules,
which are loaded from the rewrite_rules table
in the query_rewrite database.
These statements are subject to rewriting:
Standalone statements and prepared statements are subject to rewriting. Statements occurring within view definitions or stored programs are not subject to rewriting.
To add rules for the Rewriter plugin, add
rows to the rewrite_rules table, then
invoke the flush_rewrite_rules() stored
procedure to load the rules from the table into the plugin.
The following example creates a simple rule to match
statements that select a single literal value:
INSERT INTO query_rewrite.rewrite_rules (pattern, replacement)
VALUES('SELECT ?', 'SELECT ? + 1');
The resulting table contents look like this:
mysql> SELECT * FROM query_rewrite.rewrite_rules\G
*************************** 1. row ***************************
id: 1
pattern: SELECT ?
pattern_database: NULL
replacement: SELECT ? + 1
enabled: YES
message: NULL
pattern_digest: NULL
normalized_pattern: NULL
The rule specifies a pattern template indicating which
SELECT statements to match, and
a replacement template indicating how to rewrite matching
statements. However, adding the rule to the
rewrite_rules table is not sufficient to
cause the Rewriter plugin to use the rule.
You must invoke flush_rewrite_rules() to
load the table contents into the plugin in-memory cache:
mysql> CALL query_rewrite.flush_rewrite_rules();
If your rewrite rules seem not to be working properly, make
sure that you have reloaded the rules table by calling
flush_rewrite_rules().
When the plugin reads each rule from the rules table, it
computes a normalized (statement digest) form from the pattern
and a digest hash value, and uses them to update the
normalized_pattern and
pattern_digest columns:
mysql> SELECT * FROM query_rewrite.rewrite_rules\G
*************************** 1. row ***************************
id: 1
pattern: SELECT ?
pattern_database: NULL
replacement: SELECT ? + 1
enabled: YES
message: NULL
pattern_digest: d1b44b0c19af710b5a679907e284acd2ddc285201794bc69a2389d77baedddae
normalized_pattern: select ?
For information about statement digesting, normalized statements, and digest hash values, see Section 27.10, “Performance Schema Statement Digests and Sampling”.
If a rule cannot be loaded due to some error, calling
flush_rewrite_rules() produces an error:
mysql> CALL query_rewrite.flush_rewrite_rules();
ERROR 1644 (45000): Loading of some rule(s) failed.
When this occurs, the plugin writes an error message to the
message column of the rule row to
communicate the problem. Check the
rewrite_rules table for rows with
non-NULL message column
values to see what problems exist.
Patterns use the same syntax as prepared statements (see
Section 13.5.1, “PREPARE Statement”). Within a pattern template,
? characters act as parameter markers that
match data values. Parameter markers can be used only where
data values should appear, not for SQL keywords, identifiers,
and so forth. The ? characters should not
be enclosed within quotation marks.
Like the pattern, the replacement can contain
? characters. For a statement that matches
a pattern template, the plugin rewrites it, replacing
? parameter markers in the replacement
using data values matched by the corresponding markers in the
pattern. The result is a complete statement string. The plugin
asks the server to parse it, and returns the result to the
server as the representation of the rewritten statement.
After adding and loading the rule, check whether rewriting occurs according to whether statements match the rule pattern:
mysql>SELECT PI();+----------+ | PI() | +----------+ | 3.141593 | +----------+ 1 row in set (0.01 sec) mysql>SELECT 10;+--------+ | 10 + 1 | +--------+ | 11 | +--------+ 1 row in set, 1 warning (0.00 sec)
No rewriting occurs for the first
SELECT statement, but does for
the second. The second statement illustrates that when the
Rewriter plugin rewrites a statement, it
produces a warning message. To view the message, use
SHOW WARNINGS:
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Note
Code: 1105
Message: Query 'SELECT 10' rewritten to 'SELECT 10 + 1' by a query rewrite plugin
A statement need not be rewritten to a statement of the same
type. The following example loads a rule that rewrites
DELETE statements to
UPDATE statements:
INSERT INTO query_rewrite.rewrite_rules (pattern, replacement)
VALUES('DELETE FROM db1.t1 WHERE col = ?',
'UPDATE db1.t1 SET col = NULL WHERE col = ?');
CALL query_rewrite.flush_rewrite_rules();
To enable or disable an existing rule, modify its
enabled column and reload the table into
the plugin. To disable rule 1:
UPDATE query_rewrite.rewrite_rules SET enabled = 'NO' WHERE id = 1; CALL query_rewrite.flush_rewrite_rules();
This enables you to deactivate a rule without removing it from the table.
To re-enable rule 1:
UPDATE query_rewrite.rewrite_rules SET enabled = 'YES' WHERE id = 1; CALL query_rewrite.flush_rewrite_rules();
The rewrite_rules table contains a
pattern_database column that
Rewriter uses for matching table names that
are not qualified with a database name:
Qualified table names in statements match qualified names in the pattern if corresponding database and table names are identical.
Unqualified table names in statements match unqualified names in the pattern only if the default database is the same as
pattern_databaseand the table names are identical.
Suppose that a table named appdb.users has
a column named id and that applications are
expected to select rows from the table using a query of one of
these forms, where the second can be used only if
appdb is the default database:
SELECT * FROM users WHERE appdb.id =id_value; SELECT * FROM users WHERE id =id_value;
Suppose also that the id column is renamed
to user_id (perhaps the table must be
modified to add another type of ID and it is necessary to
indicate more specifically what type of ID the
id column represents).
The change means that applications must refer to
user_id rather than id
in the WHERE clause. But if there are old
applications that cannot be written to change the
SELECT queries they generate, they no
longer work properly. The Rewriter plugin
can solve this problem. To match and rewrite statements
whether or not they qualify the table name, add the following
two rules and reload the rules table:
INSERT INTO query_rewrite.rewrite_rules
(pattern, replacement) VALUES(
'SELECT * FROM appdb.users WHERE id = ?',
'SELECT * FROM appdb.users WHERE user_id = ?'
);
INSERT INTO query_rewrite.rewrite_rules
(pattern, replacement, pattern_database) VALUES(
'SELECT * FROM users WHERE id = ?',
'SELECT * FROM users WHERE user_id = ?',
'appdb'
);
CALL query_rewrite.flush_rewrite_rules();
Rewriter uses the first rule to match
statements that use the qualified table name. It uses the
second to match statements that used the unqualified name, but
only if the default database is appdb (the
value in pattern_database).
The Rewriter plugin uses statement digests
and digest hash values to match incoming statements against
rewrite rules in stages. The
max_digest_length system variable
determines the size of the buffer used for computing statement
digests. Larger values enable computation of digests that
distinguish longer statements. Smaller values use less memory
but increase the likelihood of longer statements colliding
with the same digest value.
The plugin matches each statement to the rewrite rules as follows:
Compute the statement digest hash value and compare it to the rule digest hash values. This is subject to false positives, but serves as a quick rejection test.
If the statement digest hash value matches any pattern digest hash values, match the normalized (statement digest) form of the statement to the normalized form of the matching rule patterns.
If the normalized statement matches a rule, compare the literal values in the statement and the pattern. A
?character in the pattern matches any literal value in the statement. If the statement prepares a statement,?in the pattern also matches?in the statement. Otherwise, corresponding literals must be the same.
If multiple rules match a statement, it is nondeterministic which one the plugin uses to rewrite the statement.
If a pattern contains more markers than the replacement, the
plugin discards excess data values. If a pattern contains
fewer markers than the replacement, it is an error. The plugin
notices this when the rules table is loaded, writes an error
message to the message column of the rule
row to communicate the problem, and sets the
Rewriter_reload_error status
variable to ON.
Prepared statements are rewritten at parse time (that is, when they are prepared), not when they are executed later.
Prepared statements differ from nonprepared statements in that
they may contain ? characters as parameter
markers. To match a ? in a prepared
statement, a Rewriter pattern must contain
? in the same location. Suppose that a
rewrite rule has this pattern:
SELECT ?, 3
The following table shows several prepared
SELECT statements and whether
the rule pattern matches them.
| Prepared Statement | Whether Pattern Matches Statement |
|---|---|
PREPARE s AS 'SELECT 3, 3' |
Yes |
PREPARE s AS 'SELECT ?, 3' |
Yes |
PREPARE s AS 'SELECT 3, ?' |
No |
PREPARE s AS 'SELECT ?, ?' |
No |
The Rewriter plugin makes information
available about its operation by means of several status
variables:
mysql> SHOW GLOBAL STATUS LIKE 'Rewriter%';
+-----------------------------------+-------+
| Variable_name | Value |
+-----------------------------------+-------+
| Rewriter_number_loaded_rules | 1 |
| Rewriter_number_reloads | 5 |
| Rewriter_number_rewritten_queries | 1 |
| Rewriter_reload_error | ON |
+-----------------------------------+-------+
For descriptions of these variables, see Section 5.6.4.3.4, “Rewriter Query Rewrite Plugin Status Variables”.
When you load the rules table by calling the
flush_rewrite_rules() stored procedure, if
an error occurs for some rule, the CALL
statement produces an error, and the plugin sets the
Rewriter_reload_error status variable to
ON:
mysql>CALL query_rewrite.flush_rewrite_rules();ERROR 1644 (45000): Loading of some rule(s) failed. mysql>SHOW GLOBAL STATUS LIKE 'Rewriter_reload_error';+-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | Rewriter_reload_error | ON | +-----------------------+-------+
In this case, check the rewrite_rules table
for rows with non-NULL
message column values to see what problems
exist.
When the rewrite_rules table is loaded into
the Rewriter plugin, the plugin interprets
statements using the current global value of the
character_set_client system
variable. If the global
character_set_client value is
changed subsequently, the rules table must be reloaded.
A client must have a session
character_set_client value
identical to what the global value was when the rules table
was loaded or rule matching does not work for that client.
The following discussion serves as a reference to these elements
associated with the Rewriter query rewrite
plugin:
The
Rewriterrules table in thequery_rewritedatabaseRewriterprocedures and functionsRewritersystem and status variables
The rewrite_rules table in the
query_rewrite database provides persistent
storage for the rules that the Rewriter
plugin uses to decide whether to rewrite statements.
Users communicate with the plugin by modifying the set of
rules stored in this table. The plugin communicates
information to users by setting the table's
message column.
The rules table is loaded into the plugin by the
flush_rewrite_rules stored procedure.
Unless that procedure has been called following the most
recent table modification, the table contents do not
necessarily correspond to the set of rules the plugin is
using.
The rewrite_rules table has these columns:
idThe rule ID. This column is the table primary key. You can use the ID to uniquely identify any rule.
patternThe template that indicates the pattern for statements that the rule matches. Use
?to represent parameter markers that match data values.pattern_databaseThe database used to match unqualified table names in statements. Qualified table names in statements match qualified names in the pattern if corresponding database and table names are identical. Unqualified table names in statements match unqualified names in the pattern only if the default database is the same as
pattern_databaseand the table names are identical.replacementThe template that indicates how to rewrite statements matching the
patterncolumn value. Use?to represent parameter markers that match data values. In rewritten statements, the plugin replaces?parameter markers inreplacementusing data values matched by the corresponding markers inpattern.enabledWhether the rule is enabled. Load operations (performed by invoking the
flush_rewrite_rules()stored procedure) load the rule from the table into theRewriterin-memory cache only if this column isYES.This column makes it possible to deactivate a rule without removing it: Set the column to a value other than
YESand reload the table into the plugin.messageThe plugin uses this column for communicating with users. If no error occurs when the rules table is loaded into memory, the plugin sets the
messagecolumn toNULL. A non-NULLvalue indicates an error and the column contents are the error message. Errors can occur under these circumstances:Either the pattern or the replacement is an incorrect SQL statement that produces syntax errors.
The replacement contains more
?parameter markers than the pattern.
If a load error occurs, the plugin also sets the
Rewriter_reload_errorstatus variable toON.pattern_digestThis column is used for debugging and diagnostics. If the column exists when the rules table is loaded into memory, the plugin updates it with the pattern digest. This column may be useful if you are trying to determine why some statement fails to be rewritten.
normalized_patternThis column is used for debugging and diagnostics. If the column exists when the rules table is loaded into memory, the plugin updates it with the normalized form of the pattern. This column may be useful if you are trying to determine why some statement fails to be rewritten.
Rewriter plugin operation uses a stored
procedure that loads the rules table into its in-memory cache,
and a helper user-defined function (UDF). Under normal
operation, users invoke only the stored procedure. The UDF is
intended to be invoked by the stored procedure, not directly
by users.
flush_rewrite_rules()This stored procedure uses the
load_rewrite_rules()UDF to load the contents of therewrite_rulestable into theRewriterin-memory cache.Calling
flush_rewrite_rules()impliesCOMMIT.Invoke this procedure after you modify the rules table to cause the plugin to update its cache from the new table contents. If any errors occur, the plugin sets the
messagecolumn for the appropriate rule rows in the table and sets theRewriter_reload_errorstatus variable toON.This UDF is a helper routine used by the
flush_rewrite_rules()stored procedure.
The Rewriter query rewrite plugin supports
the following system variables. These variables are available
only if the plugin is installed (see
Section 5.6.4.1, “Installing or Uninstalling the Rewriter Query Rewrite Plugin”).
-
System Variable rewriter_enabledScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value ONWhether the
Rewriterquery rewrite plugin is enabled. -
System Variable rewriter_verboseScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer For internal use.
The Rewriter query rewrite plugin supports
the following status variables. These variables are available
only if the plugin is installed (see
Section 5.6.4.1, “Installing or Uninstalling the Rewriter Query Rewrite Plugin”).
The number of rewrite plugin rewrite rules successfully loaded from the
rewrite_rulestable into memory for use by theRewriterplugin.The number of times the
rewrite_rulestable has been loaded into the in-memory cache used by theRewriterplugin.Rewriter_number_rewritten_queriesThe number of queries rewritten by the
Rewriterquery rewrite plugin since it was loaded.Whether an error occurred the most recent time that the
rewrite_rulestable was loaded into the in-memory cache used by theRewriterplugin. If the value isOFF, no error occurred. If the value isON, an error occurred; check themessagecolumn of therewriter_rulestable for error messages.
MySQL 8.0.16 and higher includes a ddl_rewriter
plugin that modifies CREATE TABLE
statements received by the server before it parses and executes
them. The plugin removes ENCRYPTION,
DATA DIRECTORY, and INDEX
DIRECTORY clauses, which may be helpful when restoring
tables from SQL dump files created from databases that are
encrypted or that have their tables stored outside the data
directory. For example, the plugin may enable restoring such dump
files into an unencrypted instance or in an environment where the
paths outside the data directory are not accessible.
Before using the ddl_rewriter plugin, install
it according to the instructions provided in
Section 5.6.5.1, “Installing or Uninstalling ddl_rewriter”.
ddl_rewriter examines SQL statements received
by the server prior to parsing, rewriting them according to these
conditions:
ddl_rewriterconsiders onlyCREATE TABLEstatements, and only if they are standalone statements that occur at the beginning of an input line or at the beginning of prepared statement text.ddl_rewriterdoes not considerCREATE TABLEstatements within stored program definitions. Statements can extend over multiple lines.Within statements considered for rewrite, instances of the following clauses are rewritten and each instance replaced by a single space:
ENCRYPTIONDATA DIRECTORY(at the table and partition levels)INDEX DIRECTORY(at the table and partition levels)
Rewriting does not depend on lettercase.
If ddl_rewriter rewrites a statement, it
generates a warning:
mysql>CREATE TABLE t (i INT) DATA DIRECTORY '/var/mysql/data';Query OK, 0 rows affected, 1 warning (0.03 sec) mysql>SHOW WARNINGS\G*************************** 1. row *************************** Level: Note Code: 1105 Message: Query 'CREATE TABLE t (i INT) DATA DIRECTORY '/var/mysql/data'' rewritten to 'CREATE TABLE t (i INT) ' by a query rewrite plugin 1 row in set (0.00 sec)
If the general query log or binary log is enabled, the server
writes to it statements as they appear after any rewriting by
ddl_rewriter.
When installed, ddl_rewriter exposes the
Performance Schema memory/rewriter/ddl_rewriter
instrument for tracking plugin memory use. See
Section 27.12.18.10, “Memory Summary Tables”
This section describes how to install or uninstall the
ddl_rewriter plugin. For general information
about installing plugins, see Section 5.6.1, “Installing and Uninstalling Plugins”.
If installed, the ddl_rewriter plugin
involves some minimal overhead even when disabled. To avoid
this overhead, install ddl_rewriter only
for the period during which you intend to use it.
The primary use case is modification of statements restored from dump files, so the typical usage pattern is: 1) Install the plugin; 2) restore the dump file or files; 3) uninstall the plugin.
To be usable by the server, the plugin library file must be
located in the MySQL plugin directory (the directory named by
the plugin_dir system
variable). If necessary, configure the plugin directory location
by setting the value of
plugin_dir at server startup.
The plugin library file base name is
ddl_rewriter. The file name suffix differs
per platform (for example, .so for Unix and
Unix-like systems, .dll for Windows).
To install the ddl_rewriter plugin, use the
INSTALL PLUGIN statement,
adjusting the .so suffix for your platform
as necessary:
INSTALL PLUGIN ddl_rewriter SONAME 'ddl_rewriter.so';
To verify plugin installation, examine the
INFORMATION_SCHEMA.PLUGINS table or
use the SHOW PLUGINS statement
(see Section 5.6.2, “Obtaining Server Plugin Information”). For
example:
mysql>SELECT PLUGIN_NAME, PLUGIN_STATUS, PLUGIN_TYPEFROM INFORMATION_SCHEMA.PLUGINSWHERE PLUGIN_NAME LIKE 'ddl%';+--------------+---------------+-------------+ | PLUGIN_NAME | PLUGIN_STATUS | PLUGIN_TYPE | +--------------+---------------+-------------+ | ddl_rewriter | ACTIVE | AUDIT | +--------------+---------------+-------------+
As the preceding result shows, ddl_rewriter
is implemented as an audit plugin.
If the plugin fails to initialize, check the server error log for diagnostic messages.
Once installed as just described,
ddl_rewriter remains installed until
uninstalled. To remove it, use UNINSTALL
PLUGIN:
UNINSTALL PLUGIN ddl_rewriter;
If ddl_rewriter is installed, you can use the
--ddl-rewriter option for
subsequent server startups to control
ddl_rewriter plugin activation. For example,
to prevent the plugin from being enabled at runtime, use this
option:
[mysqld] ddl-rewriter=OFF
This section describes the command options that control
operation of the ddl_rewriter plugin. If
values specified at startup time are incorrect, the
ddl_rewriter plugin may fail to initialize
properly and the server does not load it.
To control activation of the ddl_rewriter
plugin, use this option:
-
Command-Line Format --ddl-rewriter[=value]Introduced 8.0.16 Type Enumeration Default Value ONValid Values ONOFFFORCEFORCE_PLUS_PERMANENTThis option controls how the server loads the
ddl_rewriterplugin at startup. It is available only if the plugin has been previously registered withINSTALL PLUGINor is loaded with--plugin-loador--plugin-load-add. See Section 5.6.5.1, “Installing or Uninstalling ddl_rewriter”.The option value should be one of those available for plugin-loading options, as described in Section 5.6.1, “Installing and Uninstalling Plugins”. For example,
--ddl-rewriter=OFFdisables the plugin at server startup.
MySQL includes Version Tokens, a feature that enables creation of and synchronization around server tokens that applications can use to prevent accessing incorrect or out-of-date data.
The Version Tokens interface has these characteristics:
Version tokens are pairs consisting of a name that serves as a key or identifier, plus a value.
Version tokens can be locked. An application can use token locks to indicate to other cooperating applications that tokens are in use and should not be modified.
Version token lists are established per server (for example, to specify the server assignment or operational state). In addition, an application that communicates with a server can register its own list of tokens that indicate the state it requires the server to be in. An SQL statement sent by the application to a server not in the required state produces an error. This is a signal to the application that it should seek a different server in the required state to receive the SQL statement.
The following sections describe the elements of Version Tokens, discuss how to install and use it, and provide reference information for its elements.
Version Tokens is based on a plugin library that implements these elements:
A server-side plugin named
version_tokensholds the list of version tokens associated with the server and subscribes to notifications for statement execution events. Theversion_tokensplugin uses the audit plugin API to monitor incoming statements from clients and matches each client's session-specific version token list against the server version token list. If there is a match, the plugin lets the statement through and the server continues to process it. Otherwise, the plugin returns an error to the client and the statement fails.A set of user-defined functions (UDFs) provides an SQL-level API for manipulating and inspecting the list of server version tokens maintained by the plugin. The
VERSION_TOKEN_ADMINprivilege (or the deprecatedSUPERprivilege) is required to call any of the Version Token UDFs.When the
version_tokensplugin loads, it defines theVERSION_TOKEN_ADMINdynamic privilege. This privilege can be granted to users of the UDFs.A system variable enables clients to specify the list of version tokens that register the required server state. If the server has a different state when a client sends a statement, the client receives an error.
If installed, Version Tokens involves some overhead. To avoid this overhead, do not install it unless you plan to use it.
This section describes how to install or uninstall Version Tokens, which is implemented in a plugin library file containing a plugin and user-defined functions (UDFs). For general information about installing or uninstalling plugins and UDFs, see Section 5.6.1, “Installing and Uninstalling Plugins”, and Section 5.7.1, “Installing and Uninstalling User-Defined Functions”.
To be usable by the server, the plugin library file must be
located in the MySQL plugin directory (the directory named by
the plugin_dir system
variable). If necessary, configure the plugin directory location
by setting the value of
plugin_dir at server startup.
The plugin library file base name is
version_tokens. The file name suffix differs
per platform (for example, .so for Unix and
Unix-like systems, .dll for Windows).
To install the Version Tokens plugin and UDFs, use the
INSTALL PLUGIN and
CREATE FUNCTION statements,
adjusting the .so suffix for your platform
as necessary:
INSTALL PLUGIN version_tokens SONAME 'version_token.so'; CREATE FUNCTION version_tokens_set RETURNS STRING SONAME 'version_token.so'; CREATE FUNCTION version_tokens_show RETURNS STRING SONAME 'version_token.so'; CREATE FUNCTION version_tokens_edit RETURNS STRING SONAME 'version_token.so'; CREATE FUNCTION version_tokens_delete RETURNS STRING SONAME 'version_token.so'; CREATE FUNCTION version_tokens_lock_shared RETURNS INT SONAME 'version_token.so'; CREATE FUNCTION version_tokens_lock_exclusive RETURNS INT SONAME 'version_token.so'; CREATE FUNCTION version_tokens_unlock RETURNS INT SONAME 'version_token.so';
You must install the UDFs to manage the server's version token list, but you must also install the plugin because the UDFs do not work correctly without it.
If the plugin and UDFs are used on a replication source server, install them on all replica servers as well to avoid replication problems.
Once installed as just described, the plugin and UDFs remain
installed until uninstalled. To remove them, use the
UNINSTALL PLUGIN and
DROP FUNCTION statements:
UNINSTALL PLUGIN version_tokens; DROP FUNCTION version_tokens_set; DROP FUNCTION version_tokens_show; DROP FUNCTION version_tokens_edit; DROP FUNCTION version_tokens_delete; DROP FUNCTION version_tokens_lock_shared; DROP FUNCTION version_tokens_lock_exclusive; DROP FUNCTION version_tokens_unlock;
Before using Version Tokens, install it according to the instructions provided at Section 5.6.6.2, “Installing or Uninstalling Version Tokens”.
A scenario in which Version Tokens can be useful is a system that accesses a collection of MySQL servers but needs to manage them for load balancing purposes by monitoring them and adjusting server assignments according to load changes. Such a system comprises these elements:
The collection of MySQL servers to be managed.
An administrative or management application that communicates with the servers and organizes them into high-availability groups. Groups serve different purposes, and servers within each group may have different assignments. Assignment of a server within a certain group can change at any time.
Client applications that access the servers to retrieve and update data, choosing servers according to the purposes assigned them. For example, a client should not send an update to a read-only server.
Version Tokens permit server access to be managed according to assignment without requiring clients to repeatedly query the servers about their assignments:
The management application performs server assignments and establishes version tokens on each server to reflect its assignment. The application caches this information to provide a central access point to it.
If at some point the management application needs to change a server assignment (for example, to change it from permitting writes to read only), it changes the server's version token list and updates its cache.
To improve performance, client applications obtain cache information from the management application, enabling them to avoid having to retrieve information about server assignments for each statement. Based on the type of statements it issues (for example, reads versus writes), a client selects an appropriate server and connects to it.
In addition, the client sends to the server its own client-specific version tokens to register the assignment it requires of the server. For each statement sent by the client to the server, the server compares its own token list with the client token list. If the server token list contains all tokens present in the client token list with the same values, there is a match and the server executes the statement.
On the other hand, perhaps the management application has changed the server assignment and its version token list. In this case, the new server assignment may now be incompatible with the client requirements. A token mismatch between the server and client token lists occurs and the server returns an error in reply to the statement. This is an indication to the client to refresh its version token information from the management application cache, and to select a new server to communicate with.
The client-side logic for detecting version token errors and selecting a new server can be implemented different ways:
The client can handle all version token registration, mismatch detection, and connection switching itself.
The logic for those actions can be implemented in a connector that manages connections between clients and MySQL servers. Such a connector might handle mismatch error detection and statement resending itself, or it might pass the error to the application and leave it to the application to resend the statement.
The following example illustrates the preceding discussion in more concrete form.
When Version Tokens initializes on a given server, the server's
version token list is empty. Token list maintenance is performed
by calling user-defined functions (UDFs). The
VERSION_TOKEN_ADMIN privilege (or
the deprecated SUPER privilege)
is required to call any of the Version Token UDFs, so token list
modification is expected to be done by a management or
administrative application that has that privilege.
Suppose that a management application communicates with a set of
servers that are queried by clients to access employee and
product databases (named emp and
prod, respectively). All servers are
permitted to process data retrieval statements, but only some of
them are permitted to make database updates. To handle this on a
database-specific basis, the management application establishes
a list of version tokens on each server. In the token list for a
given server, token names represent database names and token
values are read or write
depending on whether the database must be used in read-only
fashion or whether it can take reads and writes.
Client applications register a list of version tokens they require the server to match by setting a system variable. Variable setting occurs on a client-specific basis, so different clients can register different requirements. By default, the client token list is empty, which matches any server token list. When a client sets its token list to a nonempty value, matching may succeed or fail, depending on the server version token list.
To define the version token list for a server, the management
application calls the
version_tokens_set() UDF. (There
are also UDFs for modifying and displaying the token list,
described later.) For example, the application might send these
statements to a group of three servers:
Server 1:
mysql> SELECT version_tokens_set('emp=read;prod=read');
+------------------------------------------+
| version_tokens_set('emp=read;prod=read') |
+------------------------------------------+
| 2 version tokens set. |
+------------------------------------------+
Server 2:
mysql> SELECT version_tokens_set('emp=write;prod=read');
+-------------------------------------------+
| version_tokens_set('emp=write;prod=read') |
+-------------------------------------------+
| 2 version tokens set. |
+-------------------------------------------+
Server 3:
mysql> SELECT version_tokens_set('emp=read;prod=write');
+-------------------------------------------+
| version_tokens_set('emp=read;prod=write') |
+-------------------------------------------+
| 2 version tokens set. |
+-------------------------------------------+
The token list in each case is specified as a
semicolon-separated list of
name=value
Any server accepts reads for either database.
Only server 2 accepts updates for the
empdatabase.Only server 3 accepts updates for the
proddatabase.
In addition to assigning each server a version token list, the management application also maintains a cache that reflects the server assignments.
Before communicating with the servers, a client application
contacts the management application and retrieves information
about server assignments. Then the client selects a server based
on those assignments. Suppose that a client wants to perform
both reads and writes on the emp database.
Based on the preceding assignments, only server 2 qualifies. The
client connects to server 2 and registers its server
requirements there by setting its
version_tokens_session system
variable:
mysql> SET @@SESSION.version_tokens_session = 'emp=write';
For subsequent statements sent by the client to server 2, the server compares its own version token list to the client list to check whether they match. If so, statements execute normally:
mysql>UPDATE emp.employee SET salary = salary * 1.1 WHERE id = 4981;Query OK, 1 row affected (0.07 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql>SELECT last_name, first_name FROM emp.employee WHERE id = 4981;+-----------+------------+ | last_name | first_name | +-----------+------------+ | Smith | Abe | +-----------+------------+ 1 row in set (0.01 sec)
Discrepancies between the server and client version token lists can occur two ways:
A token name in the
version_tokens_sessionvalue is not present in the server token list. In this case, anER_VTOKEN_PLUGIN_TOKEN_NOT_FOUNDerror occurs.A token value in the
version_tokens_sessionvalue differs from the value of the corresponding token in the server token list. In this case, anER_VTOKEN_PLUGIN_TOKEN_MISMATCHerror occurs.
As long as the assignment of server 2 does not change, the
client continues to use it for reads and writes. But suppose
that the management application wants to change server
assignments so that writes for the emp
database must be sent to server 1 instead of server 2. To do
this, it uses
version_tokens_edit() to modify
the emp token value on the two servers (and
updates its cache of server assignments):
Server 1:
mysql> SELECT version_tokens_edit('emp=write');
+----------------------------------+
| version_tokens_edit('emp=write') |
+----------------------------------+
| 1 version tokens updated. |
+----------------------------------+
Server 2:
mysql> SELECT version_tokens_edit('emp=read');
+---------------------------------+
| version_tokens_edit('emp=read') |
+---------------------------------+
| 1 version tokens updated. |
+---------------------------------+
version_tokens_edit() modifies the
named tokens in the server token list and leaves other tokens
unchanged.
The next time the client sends a statement to server 2, its own token list no longer matches the server token list and an error occurs:
mysql> UPDATE emp.employee SET salary = salary * 1.1 WHERE id = 4982;
ERROR 3136 (42000): Version token mismatch for emp. Correct value read
In this case, the client should contact the management application to obtain updated information about server assignments, select a new server, and send the failed statement to the new server.
Each client must cooperate with Version Tokens by sending only
statements in accordance with the token list that it registers
with a given server. For example, if a client registers a
token list of 'emp=read', there is nothing
in Version Tokens to prevent the client from sending updates
for the emp database. The client itself
must refrain from doing so.
For each statement received from a client, the server implicitly uses locking, as follows:
Take a shared lock for each token named in the client token list (that is, in the
version_tokens_sessionvalue)Perform the comparison between the server and client token lists
Execute the statement or produce an error depending on the comparison result
Release the locks
The server uses shared locks so that comparisons for multiple sessions can occur without blocking, while preventing changes to the tokens for any session that attempts to acquire an exclusive lock before it manipulates tokens of the same names in the server token list.
The preceding example uses only a few of the user-defined included in the Version Tokens plugin library, but there are others. One set of UDFs permits the server's list of version tokens to be manipulated and inspected. Another set of UDFs permits version tokens to be locked and unlocked.
These UDFs permit the server's list of version tokens to be created, changed, removed, and inspected:
version_tokens_set()completely replaces the current list and assigns a new list. The argument is a semicolon-separated list ofname=valueversion_tokens_edit()enables partial modifications to the current list. It can add new tokens or change the values of existing tokens. The argument is a semicolon-separated list ofname=valueversion_tokens_delete()deletes tokens from the current list. The argument is a semicolon-separated list of token names.version_tokens_show()displays the current token list. It takes no argument.
Each of those functions, if successful, returns a binary string indicating what action occurred. The following example establishes the server token list, modifies it by adding a new token, deletes some tokens, and displays the resulting token list:
mysql>SELECT version_tokens_set('tok1=a;tok2=b');+-------------------------------------+ | version_tokens_set('tok1=a;tok2=b') | +-------------------------------------+ | 2 version tokens set. | +-------------------------------------+ mysql>SELECT version_tokens_edit('tok3=c');+-------------------------------+ | version_tokens_edit('tok3=c') | +-------------------------------+ | 1 version tokens updated. | +-------------------------------+ mysql>SELECT version_tokens_delete('tok2;tok1');+------------------------------------+ | version_tokens_delete('tok2;tok1') | +------------------------------------+ | 2 version tokens deleted. | +------------------------------------+ mysql>SELECT version_tokens_show();+-----------------------+ | version_tokens_show() | +-----------------------+ | tok3=c; | +-----------------------+
Warnings occur if a token list is malformed:
mysql>SELECT version_tokens_set('tok1=a; =c');+----------------------------------+ | version_tokens_set('tok1=a; =c') | +----------------------------------+ | 1 version tokens set. | +----------------------------------+ 1 row in set, 1 warning (0.00 sec) mysql>SHOW WARNINGS\G*************************** 1. row *************************** Level: Warning Code: 42000 Message: Invalid version token pair encountered. The list provided is only partially updated. 1 row in set (0.00 sec)
As mentioned previously, version tokens are defined using a
semicolon-separated list of
name=valueversion_tokens_set():
mysql> SELECT version_tokens_set('tok1=b;;; tok2= a = b ; tok1 = 1\'2 3"4')
+---------------------------------------------------------------+
| version_tokens_set('tok1=b;;; tok2= a = b ; tok1 = 1\'2 3"4') |
+---------------------------------------------------------------+
| 3 version tokens set. |
+---------------------------------------------------------------+
Version Tokens interprets the argument as follows:
Whitespace around names and values is ignored. Whitespace within names and values is permitted. (For
version_tokens_delete(), which takes a list of names without values, whitespace around names is ignored.)There is no quoting mechanism.
Order of tokens is not significant except that if a token list contains multiple instances of a given token name, the last value takes precedence over earlier values.
Given those rules, the preceding
version_tokens_set() call results
in a token list with two tokens: tok1 has the
value 1'2 3"4, and tok2
has the value a = b. To verify this, call
version_tokens_show():
mysql> SELECT version_tokens_show();
+--------------------------+
| version_tokens_show() |
+--------------------------+
| tok2=a = b;tok1=1'2 3"4; |
+--------------------------+
If the token list contains two tokens, why did
version_tokens_set() return the
value 3 version tokens set? That occurred
because the original token list contained two definitions for
tok1, and the second definition replaced the
first.
The Version Tokens token-manipulation UDFs place these constraints on token names and values:
Token names cannot contain
=or;characters and have a maximum length of 64 characters.Token values cannot contain
;characters. Length of values is constrained by the value of themax_allowed_packetsystem variable.Version Tokens treats token names and values as binary strings, so comparisons are case-sensitive.
Version Tokens also includes a set of UDFs enabling tokens to be locked and unlocked:
version_tokens_lock_exclusive()acquires exclusive version token locks. It takes a list of one or more lock names and a timeout value.version_tokens_lock_shared()acquires shared version token locks. It takes a list of one or more lock names and a timeout value.version_tokens_unlock()releases version token locks (exclusive and shared). It takes no argument.
Each locking function returns nonzero for success. Otherwise, an error occurs:
mysql>SELECT version_tokens_lock_shared('lock1', 'lock2', 0);+-------------------------------------------------+ | version_tokens_lock_shared('lock1', 'lock2', 0) | +-------------------------------------------------+ | 1 | +-------------------------------------------------+ mysql>SELECT version_tokens_lock_shared(NULL, 0);ERROR 3131 (42000): Incorrect locking service lock name '(null)'.
Locking using Version Tokens locking functions is advisory; applications must agree to cooperate.
It is possible to lock nonexisting token names. This does not create the tokens.
Version Tokens locking functions are based on the locking
service described at Section 5.6.8.1, “The Locking Service”, and
thus have the same semantics for shared and exclusive locks.
(Version Tokens uses the locking service routines built into
the server, not the locking service UDF interface, so those
UDFs need not be installed to use Version Tokens.) Locks
acquired by Version Tokens use a locking service namespace of
version_token_locks. Locking service locks
can be monitored using the Performance Schema, so this is also
true for Version Tokens locks. For details, see
Locking Service Monitoring.
For the Version Tokens locking functions, token name arguments
are used exactly as specified. Surrounding whitespace is not
ignored and = and ;
characters are permitted. This is because Version Tokens simply
passes the token names to be locked as is to the locking
service.
The following discussion serves as a reference to these Version Tokens elements:
The Version Tokens plugin library includes several
user-defined functions. One set of UDFs permits the server's
list of version tokens to be manipulated and inspected.
Another set of UDFs permits version tokens to be locked and
unlocked. The
VERSION_TOKEN_ADMIN privilege
(or the deprecated SUPER
privilege) is required to invoke any Version Tokens UDF.
The following UDFs permit the server's list of version tokens
to be created, changed, removed, and inspected. Interpretation
of name_list and
token_list arguments (including
whitespace handling) occurs as described in
Section 5.6.6.3, “Using Version Tokens”, which provides details
about the syntax for specifying tokens, as well as additional
examples.
version_tokens_delete(name_list)Deletes tokens from the server's list of version tokens using the
name_listargument and returns a binary string that indicates the outcome of the operation.name_listis a semicolon-separated list of version token names to delete.mysql>
SELECT version_tokens_delete('tok1;tok3');+------------------------------------+ | version_tokens_delete('tok1;tok3') | +------------------------------------+ | 2 version tokens deleted. | +------------------------------------+An argument of
NULLis treated as an empty string, which has no effect on the token list.version_tokens_delete()deletes the tokens named in its argument, if they exist. (It is not an error to delete nonexisting tokens.) To clear the token list entirely without knowing which tokens are in the list, passNULLor a string containing no tokens toversion_tokens_set():mysql>
SELECT version_tokens_set(NULL);+------------------------------+ | version_tokens_set(NULL) | +------------------------------+ | Version tokens list cleared. | +------------------------------+ mysql>SELECT version_tokens_set('');+------------------------------+ | version_tokens_set('') | +------------------------------+ | Version tokens list cleared. | +------------------------------+version_tokens_edit(token_list)Modifies the server's list of version tokens using the
token_listargument and returns a binary string that indicates the outcome of the operation.token_listis a semicolon-separated list ofname=valueNULLor a string containing no tokens, the token list remains unchanged.mysql>
SELECT version_tokens_set('tok1=value1;tok2=value2');+-----------------------------------------------+ | version_tokens_set('tok1=value1;tok2=value2') | +-----------------------------------------------+ | 2 version tokens set. | +-----------------------------------------------+ mysql>SELECT version_tokens_edit('tok2=new_value2;tok3=new_value3');+--------------------------------------------------------+ | version_tokens_edit('tok2=new_value2;tok3=new_value3') | +--------------------------------------------------------+ | 2 version tokens updated. | +--------------------------------------------------------+version_tokens_set(token_list)Replaces the server's list of version tokens with the tokens defined in the
token_listargument and returns a binary string that indicates the outcome of the operation.token_listis a semicolon-separated list ofname=valueNULLor a string containing no tokens, the token list is cleared.mysql>
SELECT version_tokens_set('tok1=value1;tok2=value2');+-----------------------------------------------+ | version_tokens_set('tok1=value1;tok2=value2') | +-----------------------------------------------+ | 2 version tokens set. | +-----------------------------------------------+Returns the server's list of version tokens as a binary string containing a semicolon-separated list of
name=valuemysql>
SELECT version_tokens_show();+--------------------------+ | version_tokens_show() | +--------------------------+ | tok2=value2;tok1=value1; | +--------------------------+
The following UDFs permit version tokens to be locked and unlocked:
version_tokens_lock_exclusive(token_name[,token_name] ...,timeout)Acquires exclusive locks on one or more version tokens, specified by name as strings, timing out with an error if the locks are not acquired within the given timeout value.
mysql>
SELECT version_tokens_lock_exclusive('lock1', 'lock2', 10);+-----------------------------------------------------+ | version_tokens_lock_exclusive('lock1', 'lock2', 10) | +-----------------------------------------------------+ | 1 | +-----------------------------------------------------+version_tokens_lock_shared(token_name[,token_name] ...,timeout)Acquires shared locks on one or more version tokens, specified by name as strings, timing out with an error if the locks are not acquired within the given timeout value.
mysql>
SELECT version_tokens_lock_shared('lock1', 'lock2', 10);+--------------------------------------------------+ | version_tokens_lock_shared('lock1', 'lock2', 10) | +--------------------------------------------------+ | 1 | +--------------------------------------------------+Releases all locks that were acquired within the current session using
version_tokens_lock_exclusive()andversion_tokens_lock_shared().mysql>
SELECT version_tokens_unlock();+-------------------------+ | version_tokens_unlock() | +-------------------------+ | 1 | +-------------------------+
The locking functions share these characteristics:
The return value is nonzero for success. Otherwise, an error occurs.
Token names are strings.
In contrast to argument handling for the UDFs that manipulate the server token list, whitespace surrounding token name arguments is not ignored and
=and;characters are permitted.It is possible to lock nonexisting token names. This does not create the tokens.
Timeout values are nonnegative integers representing the time in seconds to wait to acquire locks before timing out with an error. If the timeout is 0, there is no waiting and the function produces an error if locks cannot be acquired immediately.
Version Tokens locking functions are based on the locking service described at Section 5.6.8.1, “The Locking Service”.
Version Tokens supports the following system variables. These variables are unavailable unless the Version Tokens plugin is installed (see Section 5.6.6.2, “Installing or Uninstalling Version Tokens”).
System variables:
-
Command-Line Format --version-tokens-session=valueSystem Variable version_tokens_sessionScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type String Default Value NULLThe session value of this variable specifies the client version token list and indicates the tokens that the client session requires the server version token list to have.
If the
version_tokens_sessionvariable isNULL(the default) or has an empty value, any server version token list matches. (In effect, an empty value disables matching requirements.)If the
version_tokens_sessionvariable has a nonempty value, any mismatch between its value and the server version token list results in an error for any statement the session sends to the server. A mismatch occurs under these conditions:A token name in the
version_tokens_sessionvalue is not present in the server token list. In this case, anER_VTOKEN_PLUGIN_TOKEN_NOT_FOUNDerror occurs.A token value in the
version_tokens_sessionvalue differs from the value of the corresponding token in the server token list. In this case, anER_VTOKEN_PLUGIN_TOKEN_MISMATCHerror occurs.
It is not a mismatch for the server version token list to include a token not named in the
version_tokens_sessionvalue.Suppose that a management application has set the server token list as follows:
mysql>
SELECT version_tokens_set('tok1=a;tok2=b;tok3=c');+--------------------------------------------+ | version_tokens_set('tok1=a;tok2=b;tok3=c') | +--------------------------------------------+ | 3 version tokens set. | +--------------------------------------------+A client registers the tokens it requires the server to match by setting its
version_tokens_sessionvalue. Then, for each subsequent statement sent by the client, the server checks its token list against the clientversion_tokens_sessionvalue and produces an error if there is a mismatch:mysql>
SET @@SESSION.version_tokens_session = 'tok1=a;tok2=b';mysql>SELECT 1;+---+ | 1 | +---+ | 1 | +---+ mysql>SET @@SESSION.version_tokens_session = 'tok1=b';mysql>SELECT 1;ERROR 3136 (42000): Version token mismatch for tok1. Correct value aThe first
SELECTsucceeds because the client tokenstok1andtok2are present in the server token list and each token has the same value in the server list. The secondSELECTfails because, althoughtok1is present in the server token list, it has a different value than specified by the client.At this point, any statement sent by the client fails, unless the server token list changes such that it matches again. Suppose that the management application changes the server token list as follows:
mysql>
SELECT version_tokens_edit('tok1=b');+-------------------------------+ | version_tokens_edit('tok1=b') | +-------------------------------+ | 1 version tokens updated. | +-------------------------------+ mysql>SELECT version_tokens_show();+-----------------------+ | version_tokens_show() | +-----------------------+ | tok3=c;tok1=b;tok2=b; | +-----------------------+Now the client
version_tokens_sessionvalue matches the server token list and the client can once again successfully execute statements:mysql>
SELECT 1;+---+ | 1 | +---+ | 1 | +---+ -
Command-Line Format --version-tokens-session-number=#System Variable version_tokens_session_numberScope Global, Session Dynamic No SET_VARHint AppliesNo Type Integer Default Value 0This variable is for internal use.
- 5.6.7.1 Installing the Clone Plugin
- 5.6.7.2 Cloning Data Locally
- 5.6.7.3 Cloning Remote Data
- 5.6.7.4 Cloning Encrypted Data
- 5.6.7.5 Cloning Compressed Data
- 5.6.7.6 Cloning for Replication
- 5.6.7.7 Directories and Files Created During a Cloning Operation
- 5.6.7.8 Remote Cloning Operation Failure Handling
- 5.6.7.9 Monitoring Cloning Operations
- 5.6.7.10 Stopping a Cloning Operation
- 5.6.7.11 Clone System Variable Reference
- 5.6.7.12 Clone System Variables
- 5.6.7.13 Clone Plugin Limitations
The clone plugin permits cloning data locally or from a remote
MySQL server instance. Cloned data is a physical snapshot of data
stored in InnoDB that includes schemas, tables,
tablespaces, and data dictionary metadata. The cloned data
comprises a fully functional data directory, which permits using
the clone plugin for MySQL server provisioning.
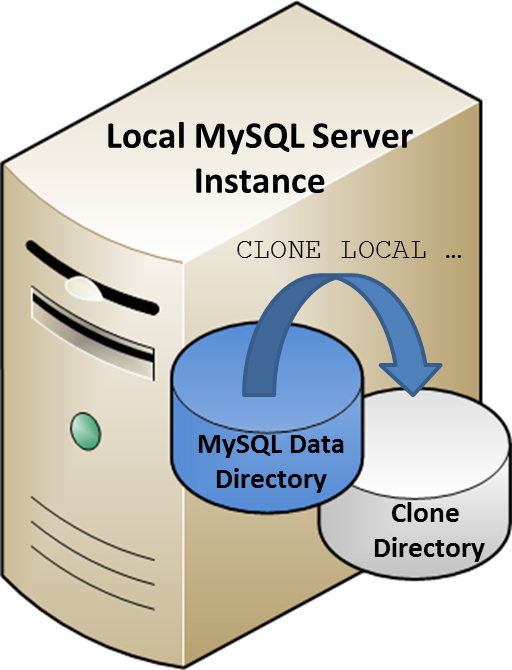
A local cloning operation clones data from the MySQL server instance where the cloning operation is initiated to a directory on the same server or node where MySQL server instance runs.
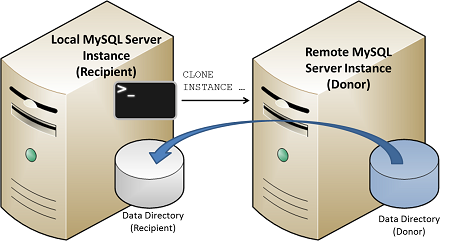
A remote cloning operation involves a local MySQL server instance (the “recipient”) where the cloning operation is initiated, and a remote MySQL server instance (the “donor”) where the source data is located. When a remote cloning operation is initiated on the recipient, cloned data is transferred over the network from the donor to the recipient. By default, a remote cloning operation removes the data in the recipient data directory and replaces it with the cloned data. Optionally, you can clone data to a different directory on the recipient to avoid removing existing data.
There is no difference with respect to data that is cloned by a local cloning operation as compared to a remote cloning operation. Both operations clone the same data.
The clone plugin supports replication. In addition to cloning data, a cloning operation extracts and transfers replication coordinates from the donor and applies them on the recipient, which enables using the clone plugin for provisioning Group Replication members and replicas. Using the clone plugin for provisioning is considerably faster and more efficient than replicating a large number of transactions (see Section 5.6.7.6, “Cloning for Replication”). Group Replication members can also be configured to use the clone plugin as an alternative method of recovery, so that members automatically choose the most efficient way to retrieve group data from seed members. For more information, see Section 18.4.3.2, “Cloning for Distributed Recovery”.
The clone plugin supports cloning of encrypted and page-compressed data. See Section 5.6.7.4, “Cloning Encrypted Data”, and Section 5.6.7.5, “Cloning Compressed Data”.
The clone plugin must be installed before you can use it. For installation instructions, see Section 5.6.7.1, “Installing the Clone Plugin”. For cloning instructions, see Section 5.6.7.2, “Cloning Data Locally”, and Section 5.6.7.3, “Cloning Remote Data”.
Performance Schema tables and instrumentation are provided for monitoring cloning operations. See Section 5.6.7.9, “Monitoring Cloning Operations”.
This section describes how to install and configure the clone plugin. For remote cloning operations, the clone plugin must be installed on the donor and recipient MySQL server instances.
For general information about installing or uninstalling plugins, see Section 5.6.1, “Installing and Uninstalling Plugins”.
To be usable by the server, the plugin library file must be
located in the MySQL plugin directory (the directory named by
the plugin_dir system
variable). If necessary, set the value of
plugin_dir at server startup to
tell the server the plugin directory location.
The plugin library file base name is
mysql_clone.so. The file name suffix differs
by platform (for example, .so for Unix and
Unix-like systems, .dll for Windows).
To load the plugin at server startup, use the
--plugin-load-add option to name
the library file that contains it. With this plugin-loading
method, the option must be given each time the server starts.
For example, put these lines in your my.cnf
file, adjusting the .so suffix for your
platform as necessary:
[mysqld] plugin-load-add=mysql_clone.so
After modifying my.cnf, restart the server
to cause the new settings to take effect.
The --plugin-load-add option
cannot be used to load the clone plugin when restarting the
server during an upgrade from a previous MySQL version. For
example, after upgrading binaries or packages from MySQL 5.7
to MySQL 8.0, attempting to restart the server with
plugin-load-add=mysql_clone.so
causes this error: [ERROR] [MY-013238] [Server]
Error installing plugin 'clone': Cannot install during
upgrade. The workaround is to upgrade the server
before attempting to start the server with
plugin-load-add=mysql_clone.so.
Alternatively, to load the plugin at runtime, use this
statement, adjusting the .so suffix for
your platform as necessary:
INSTALL PLUGIN clone SONAME 'mysql_clone.so';
INSTALL PLUGIN loads the plugin,
and also registers it in the mysql.plugins
system table to cause the plugin to be loaded for each
subsequent normal server startup without the need for
--plugin-load-add.
To verify plugin installation, examine the
INFORMATION_SCHEMA.PLUGINS table or
use the SHOW PLUGINS statement
(see Section 5.6.2, “Obtaining Server Plugin Information”). For
example:
mysql>SELECT PLUGIN_NAME, PLUGIN_STATUSFROM INFORMATION_SCHEMA.PLUGINSWHERE PLUGIN_NAME = 'clone';+------------------------+---------------+ | PLUGIN_NAME | PLUGIN_STATUS | +------------------------+---------------+ | clone | ACTIVE | +------------------------+---------------+
If the plugin fails to initialize, check the server error log for clone or plugin-related diagnostic messages.
If the plugin has been previously registered with
INSTALL PLUGIN or is loaded with
--plugin-load-add, you can use
the --clone option at server startup to control
the plugin activation state. For example, to load the plugin at
startup and prevent it from being removed at runtime, use these
options:
[mysqld] plugin-load-add=mysql_clone.so clone=FORCE_PLUS_PERMANENT
If you want to prevent the server from running without the clone
plugin, use --clone with a value of
FORCE or
FORCE_PLUS_PERMANENT to force server startup
to fail if the plugin does not initialize successfully.
For more information about plugin activation states, see Controlling Plugin Activation State.
The clone plugin supports the following syntax for cloning data locally; that is, cloning data from the local MySQL data directory to another directory on the same server or node where the MySQL server instance runs:
CLONE LOCAL DATA DIRECTORY [=] 'clone_dir';
To use CLONE syntax, the clone
plugin must be installed. For installation instructions, see
Section 5.6.7.1, “Installing the Clone Plugin”.
The BACKUP_ADMIN privilege is
required to execute CLONE
LOCAL DATA DIRECTORY statements.
mysql> GRANT BACKUP_ADMIN ON *.* TO 'clone_user';
where clone_userBACKUP_ADMIN
privilege on *.*.
The following example demonstrates cloning data locally:
mysql> CLONE LOCAL DATA DIRECTORY = '/path/to/clone_dir';
where /path/to/clone_dir is the full
path of the local directory that data is cloned to. An absolute
path is required, and the specified directory
(“clone_dir”) must not
exist, but the specified path must be an existent path. The
MySQL server must have the necessary write access to create the
directory.
A local cloning operation does not support cloning of
user-created tables or tablespaces that reside outside of the
data directory. Attempting to clone such tables or tablespaces
causes the following error: ERROR 1086 (HY000):
File '/path/to/tablespace_name.ibd'
already exists. Cloning a tablespace with the same
path as the source tablespace would cause a conflict and is
therefore prohibited.
All other user-created InnoDB tables and
tablespaces, the InnoDB system tablespace,
redo logs, and undo tablespaces are cloned to the specified
directory.
If desired, you can start the MySQL server on the cloned directory after the cloning operation is complete.
shell> mysqld_safe --datadir=clone_dir
where clone_dir is the directory that
data was cloned to.
For information about monitoring cloning operation status and progress, see Section 5.6.7.9, “Monitoring Cloning Operations”.
The clone plugin supports the following syntax for cloning remote data; that is, cloning data from a remote MySQL server instance (the donor) and transferring it to the MySQL instance where the cloning operation was initiated (the recipient).
CLONE INSTANCE FROM 'user'@'host':portIDENTIFIED BY 'password' [DATA DIRECTORY [=] 'clone_dir'] [REQUIRE [NO] SSL];
where:
userpassworduserhosthostnameaddress of the donor MySQL server instance. Internet Protocol version 6 (IPv6) address format is not supported. An alias to the IPv6 address can be used instead. An IPv4 address can be used as is.portportnumber of the donor MySQL server instance. (The X Protocol port specified bymysqlx_portis not supported. Connecting to the donor MySQL server instance through MySQL Router is also not supported.)DATA DIRECTORY [=] 'is an optional clause used to specify a directory on the recipient for the data you are cloning. Use this option if you do not want to remove existing data in the recipient data directory. An absolute path is required, and the directory must not exist. The MySQL server must have the necessary write access to create the directory.clone_dir'When the optional
DATA DIRECTORY [=] 'clause is not used, a cloning operation removes existing data in the recipient data directory, replaces it with the cloned data, and automatically restarts the server afterward.clone_dir'[REQUIRE [NO] SSL]explicitly specifies whether an encrypted connection is to be used or not when transferring cloned data over the network. An error is returned if the explicit specification cannot be satisfied. If an SSL clause is not specified, clone attempts to establish an encrypted connection by default, falling back to an insecure connection if the secure connection attempt fails. A secure connection is required when cloning encrypted data regardless of whether this clause is specified. For more information, see Configuring an Encrypted Connection for Cloning.
By default, user-created InnoDB tables and
tablespaces that reside in the data directory on the donor
MySQL server instance are cloned to the data directory on the
recipient MySQL server instance. If the DATA
DIRECTORY [=] '
clause is specified, they are cloned to the specified
directory.
clone_dir'
User-created InnoDB tables and tablespaces
that reside outside of the data directory on the donor MySQL
server instance are cloned to the same path on the recipient
MySQL server instance. An error is reported if a table or
tablespace already exists.
By default, the InnoDB system tablespace,
redo logs, and undo tablespaces are cloned to the same
locations that are configured on the donor (as defined by
innodb_data_home_dir and
innodb_data_file_path,
innodb_log_group_home_dir,
and innodb_undo_directory,
respectively). If the DATA DIRECTORY [=]
' clause is
specified, those tablespaces and logs are cloned to the
specified directory.
clone_dir'
To perform a cloning operation, the clone plugin must be active on both the donor and recipient MySQL server instances. For installation instructions, see Section 5.6.7.1, “Installing the Clone Plugin”.
A MySQL user on the donor and recipient is required for executing the cloning operation (the “clone user”).
On the donor, the clone user requires the
BACKUP_ADMINprivilege for accessing and transferring data from the donor, and for blocking DDL during the cloning operation.On the recipient, the clone user requires the
CLONE_ADMINprivilege for replacing recipient data, blocking DDL during the cloning operation, and automatically restarting the server. TheCLONE_ADMINprivilege includesBACKUP_ADMINandSHUTDOWNprivileges implicitly.
Instructions for creating the clone user and granting the required privileges are included in the remote cloning example that follows this prerequisite information.
The following prerequisites are checked when the
CLONE
INSTANCE statement is executed:
The donor and recipient must have the same MySQL server version. The clone plugin is supported in MYSQL 8.0.17 and higher.
mysql> SHOW VARIABLES LIKE 'version'; +---------------+--------+ | Variable_name | Value | +---------------+--------+ | version | 8.0.17 | +---------------+--------+
The donor and recipient MySQL server instances must run on the same operating system and platform. For example, if the donor instance runs on a Linux 64-bit platform, the recipient instance must also run on that platform. Refer to your operating system documentation for information about how to determine your operating system platform.
The recipient must have enough disk space for the cloned data. By default, recipient data is removed prior to cloning the donor data, so you only require enough space for the donor data. If you clone to a named directory using the
DATA DIRECTORYclause, you must have enough disk space for the existing recipient data and the cloned data. You can estimate the size of your data by checking the data directory size on your file system and the size of any tablespaces that reside outside of the data directory. When estimating data size on the donor, remember that onlyInnoDBdata is cloned. If you store data in other storage engines, adjust your data size estimate accordingly.InnoDBpermits creating some tablespace types outside of the data directory. If the donor MySQL server instance has tablespaces that reside outside of the data directory, the cloning operation must be able access those tablespaces. You can query theINFORMATION_SCHEMA.FILEStable to identify tablespaces that reside outside of the data directory. Files that reside outside of the data directory have a fully qualified path to a directory other than the data directory.mysql> SELECT FILE_NAME FROM INFORMATION_SCHEMA.FILES;
Plugins that are active on the donor, including any keyring plugin, must also be active on the recipient. You can identify active plugins by issuing a
SHOW PLUGINSstatement or by querying theINFORMATION_SCHEMA.PLUGINStable.The donor and recipient must have the same MySQL server character set and collation. For information about MySQL server character set and collation configuration, see Section 10.15, “Character Set Configuration”.
The same
innodb_page_sizeandinnodb_data_file_pathsettings are required on the donor and recipient. Theinnodb_data_file_pathsetting on the donor and recipient must specify the same number of data files of an equivalent size. You can check variable settings usingSHOW VARIABLESsyntax.mysql> SHOW VARIABLES LIKE 'innodb_page_size'; mysql> SHOW VARIABLES LIKE 'innodb_data_file_path';
If cloning encrypted or page-compressed data, the donor and recipient must have the same file system block size. For page-compressed data, the recipient file system must support sparse files and hole punching for hole punching to occur on the recipient. For information about these features and how to identify tables and tablespaces that use them, see Section 5.6.7.4, “Cloning Encrypted Data”, and Section 5.6.7.5, “Cloning Compressed Data”. To determine your file system block size, refer to your operating system documentation.
A secure connection is required if you are cloning encrypted data. See Configuring an Encrypted Connection for Cloning.
The
clone_valid_donor_listsetting on the recipient must include the host address of the donor MySQL server instance. You can only clone data from a host on the valid donor list. A MySQL user with theSYSTEM_VARIABLES_ADMINprivilege is required to configure this variable. Instructions for setting theclone_valid_donor_listvariable are provided in the remote cloning example that follows this section. You can check theclone_valid_donor_listsetting usingSHOW VARIABLESsyntax.mysql> SHOW VARIABLES LIKE 'clone_valid_donor_list';
There must be no other cloning operation running. Only a single cloning operation is permitted at a time. To determine if a clone operation is running, query the
clone_statustable. See Monitoring Cloning Operations using Performance Schema Clone Tables.The clone plugin transfers data in 1MB packets plus metadata. The minimum required
max_allowed_packetvalue is therefore 2MB on the donor and the recipient MySQL server instances. Amax_allowed_packetvalue less than 2MB results in an error. Use the following query to check yourmax_allowed_packetsetting:mysql> SHOW VARIABLES LIKE 'max_allowed_packet';
The following prerequisites also apply:
Undo tablespace file names on the donor must be unique. When data is cloned to the recipient, undo tablespaces, regardless of their location on the donor, are cloned to the
innodb_undo_directorylocation on the recipient or to the directory specified by theDATA DIRECTORY [=] 'clause, if used. Duplicate undo tablespace file names on the donor are not permitted for this reason. As of MySQL 8.0.18, an error is reported if duplicate undo tablespace file names are encountered during a cloning operation. Prior to MySQL 8.0.18, cloning undo tablespaces with the same file name could result in undo tablespace files being overwritten on the recipient.clone_dir'To view undo tablespace file names on the donor to ensure that they are unique, query
INFORMATION_SCHEMA.FILES:mysql> SELECT TABLESPACE_NAME, FILE_NAME FROM INFORMATION_SCHEMA.FILES WHERE FILE_TYPE LIKE 'UNDO LOG';For information about dropping and adding undo tablespace files, see Section 15.6.3.4, “Undo Tablespaces”.
By default, the recipient MySQL server instance is restarted (stopped and started) automatically after the data is cloned. For an automatic restart to occur, a monitoring process must be available on the recipient to detect server shutdowns. Otherwise, the cloning operation halts with the following error after the data is cloned, and the recipient MySQL server instance is shut down:
ERROR 3707 (HY000): Restart server failed (mysqld is not managed by supervisor process).
This error does not indicate a cloning failure. It means that the recipient MySQL server instance must be started again manually after the data is cloned. After starting the server manually, you can connect to the recipient MySQL server instance and check the Performance Schema clone tables to verify that the cloning operation completed successfully (see Monitoring Cloning Operations using Performance Schema Clone Tables.) The
RESTARTstatement has the same monitoring process requirement. For more information, see Section 13.7.8.8, “RESTART Statement”. This requirement is not applicable if cloning to a named directory using theDATA DIRECTORYclause, as an automatic restart is not performed in this case.Several variables control various aspects of a remote cloning operation. Before performing a remote cloning operation, review the variables and adjust settings as necessary to suit your computing environment. Clone variables are set on recipient MySQL server instance where the cloning operation is executed. See Section 5.6.7.12, “Clone System Variables”.
The following example demonstrates cloning remote data. By default, a remote cloning operation removes the data in the recipient data directory, replaces it with the cloned data, and restarts the MySQL server afterward.
The example assumes that remote cloning prerequisites are met. See Remote Cloning Prerequisites.
Login to the donor MySQL server instance with an administrative user account.
Create a clone user with the
BACKUP_ADMINprivilege.mysql> CREATE USER 'donor_clone_user'@'example.donor.host.com' IDENTIFIED BY '
password'; mysql> GRANT BACKUP_ADMIN on *.* to 'donor_clone_user'@'example.donor.host.com';Install the clone plugin:
mysql> INSTALL PLUGIN clone SONAME 'mysql_clone.so';
Login to the recipient MySQL server instance with an administrative user account.
Create a clone user with the
CLONE_ADMINprivilege.mysql> CREATE USER 'recipient_clone_user'@'example.recipient.host.com' IDENTIFIED BY '
password'; mysql> GRANT CLONE_ADMIN on *.* to 'recipient_clone_user'@'example.recipient.host.com';Install the clone plugin:
mysql> INSTALL PLUGIN clone SONAME 'mysql_clone.so';
Add the host address of the donor MySQL server instance to the
clone_valid_donor_listvariable setting.mysql> SET GLOBAL clone_valid_donor_list = '
example.donor.host.com:3306';
Log on to the recipient MySQL server instance as the clone user you created previously (
recipient_clone_user'@'example.recipient.host.com) and execute theCLONE INSTANCEstatement.mysql> CLONE INSTANCE FROM 'donor_clone_user'@'example.donor.host.com':3306 IDENTIFIED BY 'password';After the data is cloned, the MySQL server instance on the recipient is restarted automatically.
For information about monitoring cloning operation status and progress, see Section 5.6.7.9, “Monitoring Cloning Operations”.
By default, a remote cloning operation removes the data in the recipient data directory and replaces it with the cloned data. By cloning to a named directory, you can avoid removing existing data from the recipient data directory.
The procedure for cloning to a named directory is the same
procedure described in
Cloning Remote Data with one
exception: The CLONE
INSTANCE statement must include the DATA
DIRECTORY clause. For example:
mysql> CLONE INSTANCE FROM 'user'@'example.donor.host.com':3306IDENTIFIED BY 'password' DATA DIRECTORY = '/path/to/clone_dir';
An absolute path is required, and the directory must not exist. The MySQL server must have the necessary write access to create the directory.
When cloning to a named directory, the recipient MySQL server instance is not restarted automatically after the data is cloned. If you want to restart the MySQL server on the named directory, you must do so manually:
shell> mysqld_safe --datadir=/path/to/clone_dir
where /path/to/clone_dir is the
path to the named directory on the recipient.
You can configure an encrypted connection for remote cloning operations to protect data as it is cloned over the network. An encrypted connection is required by default when cloning encrypted data. (see Section 5.6.7.4, “Cloning Encrypted Data”.)
The instructions that follow describe how to configure the recipient MySQL server instance to use an encrypted connection. It is assumed that the donor MySQL server instance is already configured to use encrypted connections. If not, refer to Section 6.3.1, “Configuring MySQL to Use Encrypted Connections” for server-side configuration instructions.
To configure the recipient MySQL server instance to use an encrypted connection:
Make the client certificate and key files of the donor MySQL server instance available to the recipient host. Either distribute the files to the recipient host using a secure channel or place them on a mounted partition that is accessible to the recipient host. The client certificate and key files to make available include:
ca.pemThe self-signed certificate authority (CA) file.
client-cert.pemThe client public key certificate file.
client-key.pemThe client private key file.
Configure the following SSL options on the recipient MySQL server instance.
Specifies the path to the self-signed certificate authority (CA) file.
Specifies the path to the client public key certificate file.
Specifies the path to the client private key file.
For example:
clone_ssl_ca=/
path/to/ca.pem clone_ssl_cert=/path/to/client-cert.pem clone_ssl_key=/path/to/client-key.pemTo require that an encrypted connection is used, include the
REQUIRE SSLclause when issuing theCLONEstatement on the recipient.mysql> CLONE INSTANCE FROM '
user'@'example.donor.host.com':3306IDENTIFIED BY 'password' DATA DIRECTORY = '/path/to/clone_dir' REQUIRE SSL;If an SSL clause is not specified, the clone plugin attempts to establish an encrypted connection by default, falling back to an unencrypted connection if the encrypted connection attempt fails.
NoteIf you are cloning encrypted data, an encrypted connection is required by default regardless of whether the
REQUIRE SSLclause is specified. UsingREQUIRE NO SSLcauses an error if you attempt to clone encrypted data.
Cloning of encrypted data is supported. The following requirements apply:
A secure connection is required when cloning remote data to ensure safe transfer of unencrypted tablespace keys over the network. Tablespace keys are decrypted at the donor before transport and re-encrypted at the recipient using the recipient master key. An error is reported if an encrypted connection is not available or the
REQUIRE NO SSLclause is used in theCLONE INSTANCEstatement. For information about configuring an encrypted connection for cloning, see Configuring an Encrypted Connection for Cloning.When cloning data to a local data directory that uses a locally managed keyring, the same keyring must be used when starting the MySQL server on the clone directory.
When cloning data to a remote data directory (the recipient directory) that uses a locally managed keyring, the recipient keyring must be used when starting the MySQL sever on the cloned directory.
The innodb_redo_log_encrypt
and innodb_undo_log_encrypt
variable settings cannot be modified while a cloning operation
is in progress.
For information about the data encryption feature, see Section 15.13, “InnoDB Data-at-Rest Encryption”.
Cloning of page-compressed data is supported. The following requirements apply when cloning remote data:
The recipient file system must support sparse files and hole punching for hole punching to occur on the recipient.
The donor and recipient file systems must have the same block size. If file system block sizes differ, an error similar to the following is reported: ERROR 3868 (HY000): Clone Configuration FS Block Size: Donor value: 114688 is different from Recipient value: 4096.
For information about the page compression feature, see Section 15.9.2, “InnoDB Page Compression”.
The clone plugin supports replication. In addition to cloning data, a cloning operation extracts replication coordinates from the donor and transfers them to the recipient, which enables using the clone plugin for provisioning Group Replication members and replicas. Using the clone plugin for provisioning is considerably faster and more efficient than replicating a large number of transactions.
Group Replication members can also be configured to use the clone plugin as an option for distributed recovery, in which case joining members automatically choose the most efficient way to retrieve group data from existing group members. For more information, see Section 18.4.3.2, “Cloning for Distributed Recovery”.
During the cloning operation, both the binary log position
(filename, offset) and the
gtid_executed GTID set are
extracted and transferred from the donor MySQL server instance
to the recipient. This data permits initiating replication at a
consistent position in the replication stream. The binary logs
and relay logs, which are held in files, are not copied from the
donor to the recipient. To initiate replication, the binary logs
required for the recipient to catch up to the donor must not be
purged between the time that the data is cloned and the time
that replication is started. If the required binary logs are not
available, a replication handshake error is reported. A cloned
instance should therefore be added to a replication group
without excessive delay to avoid required binary logs being
purged or the new member lagging behind significantly, requiring
more recovery time.
Issue this query on a cloned MySQL server instance to check the binary log position that was transferred to the recipient:
mysql> SELECT BINLOG_FILE, BINLOG_POSITION FROM performance_schema.clone_status;
Issue this query on a cloned MySQL server instance to check the
gtid_executedGTID set that was transferred to the recipient:mysql> SELECT @@GLOBAL.GTID_EXECUTED;
By default in MySQL 8.0, the replication metadata repositories are held in tables that are copied from the donor to the recipient during the cloning operation. The replication metadata repositories hold replication-related configuration settings that can be used to resume replication correctly after the cloning operation.
In MySQL 8.0.17 and 8.0.18, only the table
mysql.slave_master_info(the connection metadata repository) is copied.From MySQL 8.0.19, the tables
mysql.slave_relay_log_info(the applier metadata repository) andmysql.slave_worker_info(the applier worker metadata repository) are also copied.
For a list of what is included in each table, see
Section 17.2.4.2, “Replication Metadata Repositories”. Note that if the settings
master_info_repository=FILE and
relay_log_info_repository=FILE
are used on the server (which is not the default in MySQL 8.0
and is deprecated), the replication metadata repositories are
not cloned; they are only cloned if TABLE is
set.
To clone for replication, perform the following steps:
For a new group member for Group Replication, first configure the MySQL Server instance for Group Replication, following the instructions in Section 18.2.1.6, “Adding Instances to the Group”. Also set up the prerequisites for cloning described in Section 18.4.3.2, “Cloning for Distributed Recovery”. When you issue
START GROUP_REPLICATIONon the joining member, the cloning operation is managed automatically by Group Replication, so you do not need to carry out the operation manually, and you do not need to perform any further setup steps on the joining member.For a replica in a source/replica MySQL replication topology, first clone the data from the donor MySQL server instance to the recipient manually. The donor must be a source or replica in the replication topology. For cloning instructions, see Section 5.6.7.3, “Cloning Remote Data”.
After the cloning operation completes successfully, if you want to use the same replication channels on the recipient MySQL server instance that were present on the donor, verify which of them can resume replication automatically in the source/replica MySQL replication topology, and which need to be set up manually.
For GTID-based replication, if the recipient is configured with
gtid_mode=ONand has cloned from a donor withgtid_mode=ON,ON_PERMISSIVE, orOFF_PERMISSIVE, thegtid_executedGTID set from the donor is applied on the recipient. If the recipient is cloned from a replica already in the topology, replication channels on the recipient that use GTID auto-positioning (as specified by theMASTER_AUTO_POSITIONoption on theCHANGE MASTER TOstatement) can resume replication automatically after the cloning operation when the channel is started. You do not need to perform any manual setup if you just want to use these same channels.For binary log file position based replication, if the recipient is at MySQL 8.0.17 or 8.0.18, the binary log position from the donor is not applied on the recipient, only recorded in the Performance Schema
clone_statustable. Replication channels on the recipient that use binary log file position based replication must therefore be set up manually to resume replication after the cloning operation. Ensure that these channels are not configured to start replication automatically at server startup, as they do not yet have the binary log position and attempt to start replication from the beginning.For binary log file position based replication, if the recipient is at MySQL 8.0.19 or above, the binary log position from the donor is applied on the recipient. Replication channels on the recipient that use binary log file position based replication automatically attempt to carry out the relay log recovery process, using the cloned relay log information, before restarting replication. For a single-threaded replica (
slave_parallel_workersis set to 0), relay log recovery should succeed in the absence of any other issues, enabling the channel to resume replication with no further setup. For a multithreaded replica (slave_parallel_workersis greater than 0), relay log recovery is likely to fail because it cannot usually be completed automatically. In this case, an error message is issued, and you must set the channel up manually.
If you need to set up cloned replication channels manually, or want to use different replication channels on the recipient, the following instructions provide a summary and abbreviated examples for adding a recipient MySQL server instance to a replication topology. Also refer to the detailed instructions that apply to your replication setup.
To add a recipient MySQL server instance to a MySQL replication topology that uses GTID-based transactions as the replication data source, configure the instance as required, following the instructions in Section 17.1.3.4, “Setting Up Replication Using GTIDs”. Add replication channels for the instance as shown in the following abbreviated example. The
CHANGE MASTER TOstatement must define the host address and port number of the source, and theMASTER_AUTO_POSITIONoption should be enabled, as shown:mysql> CHANGE MASTER TO MASTER_HOST = '
source_host_name', MASTER_PORT =source_port_num, ... MASTER_AUTO_POSITION = 1, FOR CHANNEL 'setup_channel'; mysql> START SLAVE USER = 'user_name' PASSWORD = 'password' FOR CHANNEL 'setup_channel'; Or from MySQL 8.0.22: mysql> START REPLICA USER = 'user_name' PASSWORD = 'password' FOR CHANNEL 'setup_channel';To add a recipient MySQL server instance to a MySQL replication topology that uses binary log file position based replication, configure the instance as required, following the instructions in Section 17.1.2, “Setting Up Binary Log File Position Based Replication”. Add replication channels for the instance as shown in the following abbreviated example, using the binary log position that was transferred to the recipient during the cloning operation:
mysql> SELECT BINLOG_FILE, BINLOG_POSITION FROM performance_schema.clone_status; mysql> CHANGE MASTER TO MASTER_HOST = '
source_host_name', MASTER_PORT =source_port_num, ... MASTER_LOG_FILE = 'source_log_name', MASTER_LOG_POS =source_log_pos, FOR CHANNEL 'setup_channel'; mysql> START SLAVE USER = 'user_name' PASSWORD = 'password' FOR CHANNEL 'setup_channel'; Or from MySQL 8.0.22: mysql> START REPLICA USER = 'user_name' PASSWORD = 'password' FOR CHANNEL 'setup_channel';
When data is cloned, the following directories and files are created for internal use. They should not be modified.
#clone: Contains internal clone files used by the cloning operation. Created in the directory that data is cloned to.#ib_archive: Contains internally archived log files, archived on the donor during the cloning operation.*.#clonefiles: Temporary data files created on the recipient while the existing data directory is replaced by a remote cloning operation.
This section describes failure handing at different stages of a cloning operation.
Prerequisites are checked (see Remote Cloning Prerequisites).
If a failure occurs during the prerequisite check, the
CLONE INSTANCEoperation reports an error.
A backup lock is taken to block DDL operations.
If the cloning operation is unable to obtain a DDL lock within the time limit specified by the
clone_ddl_timeoutvariable, an error is reported.
User-created data (schemas, tables, tablespaces) and binary logs on the recipient are removed before data is cloned to the recipient data directory.
When user created data is removed from the recipient during a remote cloning operation, existing data in the recipient data directory is not saved and may be lost if a failure occurs. If the data to be replaced on the recipient is of importance, a backup should be taken before initiating a remote cloning operation.
For informational purposes, warnings are printed to the server error log to specify when data removal starts and finishes:
[Warning] [MY-013453] [InnoDB] Clone removing all user data for provisioning: Started... [Warning] [MY-013453] [InnoDB] Clone removing all user data for provisioning: Finished
If a failure occurs while removing data, the recipient may be left with a partial set of schemas, tables, and tablespaces that existed before the cloning operation. Any time during the execution of a cloning operation or after a failure, the server is always in a consistent state.
Data is cloned from the donor. User-created data, dictionary metadata, and other system data are cloned.
If a failure occurs while cloning data, the cloning operation is rolled back and all cloned data removed. At this stage, the previously existing data on the recipient has also been removed, which leaves the recipient with no user data.
Should this scenario occur, you can either rectify the cause of the failure and re-execute the cloning operation, or forgo the cloning operation and restore the recipient data from a backup taken before the cloning operation.
The server is restarted automatically (applies to remote cloning operations that do not clone to a named directory). During startup, typical server startup tasks are performed.
If the automatic server restart fails, you can restart the server manually to complete the cloning operation.
If a network error occurs during a cloning operation, the operation resumes if the error is resolved within five minutes. Otherwise, the operation aborts and returns an error.
This section describes options for monitoring cloning operations.
A cloning operation may take some time to complete, depending
on the amount of data and other factors related to data
transfer. You can monitor the status and progress of a cloning
operation on the recipient MySQL server instance using the
clone_status and
clone_progress Performance Schema
tables.
The clone_status and
clone_progress Performance
Schema tables can be used to monitor a cloning operation on
the recipient MySQL server instance only. To monitor a
cloning operation on the donor MySQL server instance, use
the clone stage events, as described in
Monitoring Cloning Operations Using Performance Schema Stage Events.
The
clone_statustable provides the state of the current or last executed cloning operation. A clone operation has four possible states:Not Started,In Progress,Completed, andFailed.The
clone_progresstable provides progress information for the current or last executed clone operation, by stage. The stages of a cloning operation includeDROP DATA,FILE COPY,PAGE_COPY,REDO_COPY,FILE_SYNC,RESTART, andRECOVERY.
The SELECT and
EXECUTE privileges on the
Performance Schema is required to access the Performance
Schema clone tables.
To check the state of a cloning operation:
Connect to the recipient MySQL server instance.
Query the
clone_statustable:mysql>
SELECT STATE FROM performance_schema.clone_status;+-----------+ | STATE | +-----------+ | Completed | +-----------+
Should a failure occur during a cloning operation, you can
query the clone_status table for
error information:
mysql> SELECT STATE, ERROR_NO, ERROR_MESSAGE FROM performance_schema.clone_status;
+-----------+----------+---------------+
| STATE | ERROR_NO | ERROR_MESSAGE |
+-----------+----------+---------------+
| Failed | xxx | "xxxxxxxxxxx" |
+-----------+----------+---------------+
To review the details of each stage of a cloning operation:
Connect to the recipient MySQL server instance.
Query the
clone_progresstable. For example, the following query provides state and end time data for each stage of the cloning operation:mysql>
SELECT STAGE, STATE, END_TIME FROM performance_schema.clone_progress;+-----------+-----------+----------------------------+ | stage | state | end_time | +-----------+-----------+----------------------------+ | DROP DATA | Completed | 2019-01-27 22:45:43.141261 | | FILE COPY | Completed | 2019-01-27 22:45:44.457572 | | PAGE COPY | Completed | 2019-01-27 22:45:44.577330 | | REDO COPY | Completed | 2019-01-27 22:45:44.679570 | | FILE SYNC | Completed | 2019-01-27 22:45:44.918547 | | RESTART | Completed | 2019-01-27 22:45:48.583565 | | RECOVERY | Completed | 2019-01-27 22:45:49.626595 | +-----------+-----------+----------------------------+For other clone status and progress data points that you can monitor, refer to Section 27.12.17, “Performance Schema Clone Tables”.
A cloning operation may take some time to complete, depending
on the amount of data and other factors related to data
transfer. There are three stage events for monitoring the
progress of a cloning operation. Each stage event reports
WORK_COMPLETEDWORK_ESTIMATED
This method of monitoring a cloning operation can be used on the donor or recipient MySQL server instance.
In order of occurrence, cloning operation stage events include:
stage/innodb/clone (file copy): Indicates progress of the file copy phase of the cloning operation.WORK_ESTIMATEDWORK_COMPLETEDWORK_ESTIMATEDis set to the number of estimated file chunks.WORK_COMPLETEDis updated after each chunk is sent.stage/innodb/clone (page copy): Indicates progress of the page copy phase of cloning operation.WORK_ESTIMATEDandWORK_COMPLETEDunits are pages. Once the file copy phase is completed, the number of pages to be transferred is known, andWORK_ESTIMATEDis set to this value.WORK_COMPLETEDis updated after each page is sent.stage/innodb/clone (redo copy): Indicates progress of the redo copy phase of cloning operation.WORK_ESTIMATEDandWORK_COMPLETEDunits are redo chunks. Once the page copy phase is completed, the number of redo chunks to be transferred is known, andWORK_ESTIMATEDis set to this value.WORK_COMPLETEDis updated after each chunk is sent.
The following example demonstrates how to enable
stage/innodb/clone% event instruments and
related consumer tables to monitor a cloning operation. For
information about Performance Schema stage event instruments
and related consumers, see
Section 27.12.5, “Performance Schema Stage Event Tables”.
Enable the
stage/innodb/clone%instruments:mysql>
UPDATE performance_schema.setup_instruments SET ENABLED = 'YES'WHERE NAME LIKE 'stage/innodb/clone%';Enable the stage event consumer tables, which include
events_stages_current,events_stages_history, andevents_stages_history_long.mysql>
UPDATE performance_schema.setup_consumers SET ENABLED = 'YES'WHERE NAME LIKE '%stages%';Run a cloning operation. In this example, a local data directory is cloned to a directory named
cloned_dir.mysql>
CLONE LOCAL DATA DIRECTORY = '/path/to/cloned_dir';Check the progress of the cloning operation by querying the Performance Schema
events_stages_currenttable. The stage event shown differs depending on the cloning phase that is in progress. TheWORK_COMPLETEDcolumn shows the work completed. TheWORK_ESTIMATEDcolumn shows the work required in total.mysql>
SELECT EVENT_NAME, WORK_COMPLETED, WORK_ESTIMATED FROM performance_schema.events_stages_currentWHERE EVENT_NAME LIKE 'stage/innodb/clone%';+--------------------------------+----------------+----------------+ | EVENT_NAME | WORK_COMPLETED | WORK_ESTIMATED | +--------------------------------+----------------+----------------+ | stage/innodb/clone (redo copy) | 1 | 1 | +--------------------------------+----------------+----------------+The
events_stages_currenttable returns an empty set if the cloning operation has finished. In this case, you can check theevents_stages_historytable to view event data for the completed operation. For example:mysql>
SELECT EVENT_NAME, WORK_COMPLETED, WORK_ESTIMATED FROM events_stages_historyWHERE EVENT_NAME LIKE 'stage/innodb/clone%';+--------------------------------+----------------+----------------+ | EVENT_NAME | WORK_COMPLETED | WORK_ESTIMATED | +--------------------------------+----------------+----------------+ | stage/innodb/clone (file copy) | 301 | 301 | | stage/innodb/clone (page copy) | 0 | 0 | | stage/innodb/clone (redo copy) | 1 | 1 | +--------------------------------+----------------+----------------+
Performance Schema provides instrumentation for advanced performance monitoring of clone operations. To view the available clone instrumentation, issue the following query:
mysql>SELECT * FROM performance_schema.setup_instrumentsWHERE NAME LIKE WHERE NAME LIKE '%clone%';+----------------------------------------------+---------+ | NAME | ENABLED | +----------------------------------------------+---------+ | wait/synch/mutex/innodb/clone_snapshot_mutex | NO | | wait/synch/mutex/innodb/clone_sys_mutex | NO | | wait/synch/mutex/innodb/clone_task_mutex | NO | | wait/io/file/innodb/innodb_clone_file | YES | | stage/innodb/clone (file copy) | YES | | stage/innodb/clone (redo copy) | YES | | stage/innodb/clone (page copy) | YES | | statement/abstract/clone | YES | | statement/clone/local | YES | | statement/clone/client | YES | | statement/clone/server | YES | | memory/innodb/clone | YES | | memory/clone/data | YES | +----------------------------------------------+---------+
Wait Instruments
Performance schema wait instruments track events that take time. Clone wait event instruments include:
wait/synch/mutex/innodb/clone_snapshot_mutex: Tracks wait events for the clone snapshot mutex, which synchronizes access to the dynamic snapshot object (on the donor and recipient) between multiple clone threads.wait/synch/mutex/innodb/clone_sys_mutex: Tracks wait events for the clone sys mutex. There is one clone system object in a MySQL server instance. This mutex synchronizes access to the clone system object on the donor and recipient. It is acquired by clone threads and other foreground and background threads.wait/synch/mutex/innodb/clone_task_mutex: Tracks wait events for the clone task mutex, used for clone task management. Theclone_task_mutexis acquired by clone threads.wait/io/file/innodb/innodb_clone_file: Tracks all I/O wait operations for files that clone operates on.
For information about monitoring InnoDB
mutex waits, see
Section 15.16.2, “Monitoring InnoDB Mutex Waits Using Performance Schema”.
For information about monitoring wait events in general, see
Section 27.12.4, “Performance Schema Wait Event Tables”.
Stage Instruments
Performance Schema stage events track steps that occur during the statement-execution process. Clone stage event instruments include:
stage/innodb/clone (file copy): Indicates progress of the file copy phase of the cloning operation.stage/innodb/clone (redo copy): Indicates progress of the redo copy phase of cloning operation.stage/innodb/clone (page copy): Indicates progress of the page copy phase of cloning operation.
For information about monitoring cloning operations using stage events, see Monitoring Cloning Operations Using Performance Schema Stage Events. For general information about monitoring stage events, see Section 27.12.5, “Performance Schema Stage Event Tables”.
Statement Instruments
Performance Schema statement events track statement execution.
When a clone operation is initiated, the different statement
types tracked by clone statement instruments may be executed
in parallel. You can observe these statement events in the
Performance Schema statement event tables. The number of
statements that execute depends on the
clone_max_concurrency and
clone_autotune_concurrency
settings.
Clone statement event instruments include:
statement/abstract/clone: Tracks statement events for any clone operation before it is classified as a local, client, or server operation type.statement/clone/local: Tracks clone statement events for local clone operations; generated when executing aCLONE LOCALstatement.statement/clone/client: Tracks remote cloning statement events that occur on the recipient MySQL server instance; generated when executing aCLONE INSTANCEstatement on the recipient.statement/clone/server: Tracks remote cloning statement events that occur on the donor MySQL server instance; generated when executing aCLONE INSTANCEstatement on the recipient.
For information about monitoring Performance Schema statement events, see Section 27.12.6, “Performance Schema Statement Event Tables”.
Memory Instruments
Performance Schema memory instruments track memory usage. Clone memory usage instruments include:
memory/innodb/clone: Tracks memory allocated byInnoDBfor the dynamic snapshot.memory/clone/data: Tracks memory allocated by the clone plugin during a clone operation.
For information about monitoring memory usage using Performance Schema, see Section 27.12.18.10, “Memory Summary Tables”.
The
Com_clone
status variable provides a count of
CLONE statement executions.
For more information, refer to the discussion about
Com_xxx
statement counter variables in
Section 5.1.10, “Server Status Variables”.
If necessary, you can stop a cloning operation with a
KILL QUERY
statement.
processlist_id
On the recipient MySQL server instance, you can retrieve the
processlist identifier (PID) for a cloning operation from the
PID column of the
clone_status table.
mysql> SELECT * FROM performance_schema.clone_status\G
*************************** 1. row ***************************
ID: 1
PID: 8
STATE: In Progress
BEGIN_TIME: 2019-07-15 11:58:36.767
END_TIME: NULL
SOURCE: LOCAL INSTANCE
DESTINATION: /path/to/clone_dir/
ERROR_NO: 0
ERROR_MESSAGE:
BINLOG_FILE:
BINLOG_POSITION: 0
GTID_EXECUTED:
You can also retrieve the processlist identifier from the
ID column of the
INFORMATION_SCHEMA
PROCESSLIST table, the
Id column of SHOW
PROCESSLIST output, or the
PROCESSLIST_ID column of the Performance
Schema threads table. These methods
of obtaining the PID information can be used on the donor or
recipient MySQL server instance.
Table 5.6 Clone System Variable Reference
| Name | Cmd-Line | Option File | System Var | Status Var | Var Scope | Dynamic |
|---|---|---|---|---|---|---|
| clone_autotune_concurrency | Yes | Yes | Yes | Global | Yes | |
| clone_buffer_size | Yes | Yes | Yes | Global | Yes | |
| clone_ddl_timeout | Yes | Yes | Yes | Global | Yes | |
| clone_enable_compression | Yes | Yes | Yes | Global | Yes | |
| clone_max_concurrency | Yes | Yes | Yes | Global | Yes | |
| clone_max_data_bandwidth | Yes | Yes | Yes | Global | Yes | |
| clone_max_network_bandwidth | Yes | Yes | Yes | Global | Yes | |
| clone_ssl_ca | Yes | Yes | Yes | Global | Yes | |
| clone_ssl_cert | Yes | Yes | Yes | Global | Yes | |
| clone_ssl_key | Yes | Yes | Yes | Global | Yes | |
| clone_valid_donor_list | Yes | Yes | Yes | Global | Yes |
This section describes the system variables that control operation of the clone plugin. If values specified at startup are incorrect, the clone plugin may fail to initialize properly and the server does not load it. In this case, the server may also produce error messages for other clone settings because it does not recognize them.
Each system variable has a default value. System variables can
be set at server startup using options on the command line or in
an option file. They can be changed dynamically at runtime using
the SET statement, which enables
you to modify operation of the server without having to stop and
restart it.
Setting a global system variable runtime value normally requires
the SYSTEM_VARIABLES_ADMIN
privilege (or the deprecated
SUPER privilege). For more
information, see Section 5.1.9.1, “System Variable Privileges”.
Clone variables are configured on the recipient MySQL server instance where the cloning operation is executed.
-
Command-Line Format --clone-autotune-concurrencyIntroduced 8.0.17 System Variable clone_autotune_concurrencyScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value ONWhen
clone_autotune_concurrencyis enabled (the default), additional threads for remote cloning operations are spawned dynamically to optimize data transfer speed. The setting is applicable to recipient MySQL server instance only.During a cloning operation, the number of threads increases incrementally toward a target of double the current thread count. The effect on the data transfer speed is evaluated at each increment. The process either continues or stops according to the following rules:
If the data transfer speed degrades more than 5% with an incremental increase, the process stops.
If there is at least a 5% improvement after reaching 25% of the target, the process continues. Otherwise, the process stops.
If there is at least a 10% improvement after reaching 50% of the target, the process continues. Otherwise, the process stops.
If there is at least a 25% improvement after reaching the target, the process continues toward a new target of double the current thread count. Otherwise, the process stops.
The autotuning process does not support decreasing the number of threads.
The
clone_max_concurrencyvariable defines the maximum number of threads that can be spawned.If
clone_autotune_concurrencyis disabled,clone_max_concurrencydefines the number of threads spawned for a remote cloning operation. -
Command-Line Format --clone-buffer-sizeIntroduced 8.0.17 System Variable clone_buffer_sizeScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 4194304Minimum Value 1048576Maximum Value 268435456Defines the size of the intermediate buffer used when transferring data during a local cloning operation. This setting is not applicable to remote cloning operations. The default value is 4 mebibytes (MiB). A larger buffer size may permit I/O device drivers to fetch data in parallel, which can improve cloning performance.
-
Command-Line Format --clone-ddl-timeoutIntroduced 8.0.17 System Variable clone_ddl_timeoutScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 300Minimum Value 0Maximum Value 2592000The time in seconds to wait for a backup lock when executing a cloning operation. This setting is applied on both the donor and recipient MySQL server instances. A cloning operation cannot run concurrently with DDL operations. A backup lock is required on the donor and recipient MySQL server instances. The cloning operation waits for current DDL operations to finish. Once backup locks are acquired, DDL operations must wait for the cloning operation to finish. A value of 0 means that no backup lock is to be taken for the cloning operation. In this case, the cloning operation fails with an error if a DDL operation is attempted concurrently.
-
Command-Line Format --clone-enable-compressionIntroduced 8.0.17 System Variable clone_enable_compressionScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFEnables compression of data at the network layer during a remote cloning operation. Compression saves network bandwidth at the cost of CPU. Enabling compression may improve the data transfer rate. This setting is only applied on the recipient MySQL server instance.
-
Command-Line Format --clone-max-concurrencyIntroduced 8.0.17 System Variable clone_max_concurrencyScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 16Minimum Value 1Maximum Value 128Defines the maximum number of concurrent threads for a remote cloning operation. The default value is 16. A greater number of threads can improve cloning performance but also reduces the number of permitted simultaneous client connections, which can affect the performance of existing client connections. This setting is only applied on the recipient MySQL server instance.
If
clone_autotune_concurrencyis enabled (the default),clone_max_concurrencyis the maximum number of threads that can be dynamically spawned for a remote cloning operation. Ifclone_autotune_concurrencyis disabled,clone_max_concurrencydefines the number of threads spawned for a remote cloning operation.A minimum data transfer rate of 1 mebibyte (MiB) per thread is recommended for remote cloning operations. The data transfer rate for a remote cloning operation is controlled by the
clone_max_data_bandwidthvariable. -
Command-Line Format --clone-max-data-bandwidthIntroduced 8.0.17 System Variable clone_max_data_bandwidthScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 1048576Defines the maximum data transfer rate in mebibytes (MiB) per second for a remote cloning operation. This variable helps manage the performance impact of a cloning operation. A limit should be set only when donor disk I/O bandwidth is saturated, affecting performance. A value of 0 means “unlimited”, which permits cloning operations to run at the highest possible data transfer rate. This setting is only applicable to the recipient MySQL server instance.
The minimum data transfer rate is 1 MiB per second, per thread. For example, if there are 8 threads, the minimum transfer rate is 8 MiB per second. The
clone_max_concurrencyvariable controls the maximum number threads spawned for a remote cloning operation.The requested data transfer rate specified by
clone_max_data_bandwidthmay differ from the actual data transfer rate reported by theDATA_SPEEDcolumn in theperformance_schema.clone_progresstable. If your cloning operation is not achieving the desired data transfer rate and you have available bandwidth, check I/O usage on the recipient and donor. If there is underutilized bandwidth, I/O is the next mostly likely bottleneck. -
Command-Line Format --clone-max-network-bandwidthIntroduced 8.0.17 System Variable clone_max_network_bandwidthScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 1048576Specifies the maximum approximate network transfer rate in mebibytes (MiB) per second for a remote cloning operation. This variable can be used to manage the performance impact of a cloning operation on network bandwidth. It should be set only when network bandwidth is saturated, affecting performance on the donor instance. A value of 0 means “unlimited”, which permits cloning at the highest possible data transfer rate over the network, providing the best performance. This setting is only applicable to the recipient MySQL server instance.
-
Command-Line Format --clone-ssl-ca=file_nameIntroduced 8.0.14 System Variable clone_ssl_caScope Global Dynamic Yes SET_VARHint AppliesNo Type File name Default Value empty stringSpecifies the path to the certificate authority (CA) file. Used to configure an encrypted connection for a remote cloning operation. This setting configured on the recipient and used when connecting to the donor.
-
Command-Line Format --clone-ssl-cert=file_nameIntroduced 8.0.14 System Variable clone_ssl_certScope Global Dynamic Yes SET_VARHint AppliesNo Type File name Default Value empty stringSpecifies the path to the public key certificate. Used to configure an encrypted connection for a remote cloning operation. This setting configured on the recipient and used when connecting to the donor.
-
Command-Line Format --clone-ssl-key=file_nameIntroduced 8.0.14 System Variable clone_ssl_keyScope Global Dynamic Yes SET_VARHint AppliesNo Type File name Default Value empty stringSpecifies the path to the private key file. Used to configure an encrypted connection for a remote cloning operation. This setting configured on the recipient and used when connecting to the donor.
-
Command-Line Format --clone-valid-donor-list=valueIntroduced 8.0.17 System Variable clone_valid_donor_listScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value NULLDefines valid donor host addresses for remote cloning operations. This setting is applied on the recipient MySQL server instance. A comma-separated list of values is permitted in the following format: “
HOST1:PORT1,HOST2:PORT2,HOST3:PORT3”. Spaces are not permitted.The
clone_valid_donor_listvariable adds a layer of security by providing control over the sources of cloned data. The privilege required to configureclone_valid_donor_listis different from the privilege required to execute remote cloning operations, which permits assigning those responsibilities to different roles. Configuringclone_valid_donor_listrequires theSYSTEM_VARIABLES_ADMINprivilege, whereas executing a remote cloning operation requires theCLONE_ADMINprivilege.Internet Protocol version 6 (IPv6) address format is not supported. Internet Protocol version 6 (IPv6) address format is not supported. An alias to the IPv6 address can be used instead. An IPv4 address can be used as is.
The clone plugin is subject to these limitations:
DDL, including
TRUNCATE TABLE, is not permitted during a cloning operation. This limitation should be considered when selecting data sources. A workaround is to use dedicated donor instances, which can accommodate DDL operations being blocked while data is cloned. Concurrent DML is permitted.An instance cannot be cloned from a different MySQL server version or release. The donor and recipient must have exactly the same MySQL server version and release. For example, you cannot clone between MySQL 5.7 and MySQL 8.0, or between MySQL 8.0.19 and MySQL 8.0.20. The clone plugin is only supported in MySQL 8.0.17 and higher.
Only a single MySQL instance can be cloned at a time. Cloning multiple MySQL instances in a single cloning operation is not supported.
The X Protocol port specified by
mysqlx_portis not supported for remote cloning operations (when specifying the port number of the donor MySQL server instance in aCLONE INSTANCEstatement).The clone plugin does not support cloning of MySQL server configurations. The recipient MySQL server instance retains its configuration, including persisted system variable settings (see Section 5.1.9.3, “Persisted System Variables”.)
The clone plugin does not support cloning of binary logs.
The clone plugin only clones data stored in
InnoDB. Other storage engine data is not cloned.MyISAMandCSVtables stored in any schema including thesysschema are cloned as empty tables.Connecting to the donor MySQL server instance through MySQL Router is not supported.
Local cloning operations do not support cloning of general tablespaces that were created with an absolute path. A cloned tablespace file with the same path as the source tablespace file would cause a conflict.
MySQL server plugins have access to server “plugin services.” The plugin services interface complements the plugin API by exposing server functionality that plugins can call. For developer information about writing plugin services, see MySQL Services for Plugins. The following sections describe plugin services available at the SQL and C-language levels.
MySQL distributions provide a locking interface that is accessible at two levels:
At the SQL level, as a set of user-defined functions (UDFs) that map onto calls to the service routines.
As a C language interface, callable as a plugin service from server plugins or user-defined functions.
For general information about plugin services, see Section 5.6.8, “MySQL Plugin Services”. For general information about user-defined functions, see Adding a User-Defined Function.
The locking interface has these characteristics:
Locks have three attributes: Lock namespace, lock name, and lock mode:
Locks are identified by the combination of namespace and lock name. The namespace enables different applications to use the same lock names without colliding by creating locks in separate namespaces. For example, if applications A and B use namespaces of
ns1andns2, respectively, each application can use lock nameslock1andlock2without interfering with the other application.A lock mode is either read or write. Read locks are shared: If a session has a read lock on a given lock identifier, other sessions can acquire a read lock on the same identifier. Write locks are exclusive: If a session has a write lock on a given lock identifier, other sessions cannot acquire a read or write lock on the same identifier.
Namespace and lock names must be non-
NULL, nonempty, and have a maximum length of 64 characters. A namespace or lock name specified asNULL, the empty string, or a string longer than 64 characters results in anER_LOCKING_SERVICE_WRONG_NAMEerror.The locking interface treats namespace and lock names as binary strings, so comparisons are case-sensitive.
The locking interface provides functions to acquire locks and release locks. No special privilege is required to call these functions. Privilege checking is the responsibility of the calling application.
Locks can be waited for if not immediately available. Lock acquisition calls take an integer timeout value that indicates how many seconds to wait to acquire locks before giving up. If the timeout is reached without successful lock acquisition, an
ER_LOCKING_SERVICE_TIMEOUTerror occurs. If the timeout is 0, there is no waiting and the call produces an error if locks cannot be acquired immediately.The locking interface detects deadlock between lock-acquisition calls in different sessions. In this case, the locking service chooses a caller and terminates its lock-acquisition request with an
ER_LOCKING_SERVICE_DEADLOCKerror. This error does not cause transactions to roll back. To choose a session in case of deadlock, the locking service prefers sessions that hold read locks over sessions that hold write locks.A session can acquire multiple locks with a single lock-acquisition call. For a given call, lock acquisition is atomic: The call succeeeds if all locks are acquired. If acquisition of any lock fails, the call acquires no locks and fails, typically with an
ER_LOCKING_SERVICE_TIMEOUTorER_LOCKING_SERVICE_DEADLOCKerror.A session can acquire multiple locks for the same lock identifier (namespace and lock name combination). These lock instances can be read locks, write locks, or a mix of both.
Locks acquired within a session are released explicitly by calling a release-locks function, or implicitly when the session terminates (either normally or abnormally). Locks are not released when transactions commit or roll back.
Within a session, all locks for a given namespace when released are released together.
The interface provided by the locking service is distinct from
that provided by GET_LOCK() and
related SQL functions (see Section 12.15, “Locking Functions”).
For example, GET_LOCK() does not
implement namespaces and provides only exclusive locks, not
distinct read and write locks.
This section describes how to use the locking service C language interface. To use the UDF interface instead, see Section 5.6.8.1.2, “The Locking Service UDF Interface” For general characteristics of the locking service interface, see Section 5.6.8.1, “The Locking Service”. For general information about plugin services, see Section 5.6.8, “MySQL Plugin Services”.
Source files that use the locking service should include this header file:
#include <mysql/service_locking.h>
To acquire one or more locks, call this function:
int mysql_acquire_locking_service_locks(MYSQL_THD opaque_thd,
const char* lock_namespace,
const char**lock_names,
size_t lock_num,
enum enum_locking_service_lock_type lock_type,
unsigned long lock_timeout);
The arguments have these meanings:
opaque_thd: A thread handle. If specified asNULL, the handle for the current thread is used.lock_namespace: A null-terminated string that indicates the lock namespace.lock_names: An array of null-terminated strings that provides the names of the locks to acquire.lock_num: The number of names in thelock_namesarray.lock_type: The lock mode, eitherLOCKING_SERVICE_READorLOCKING_SERVICE_WRITEto acquire read locks or write locks, respectively.lock_timeout: An integer number of seconds to wait to acquire the locks before giving up.
To release locks acquired for a given namespace, call this function:
int mysql_release_locking_service_locks(MYSQL_THD opaque_thd,
const char* lock_namespace);
The arguments have these meanings:
opaque_thd: A thread handle. If specified asNULL, the handle for the current thread is used.lock_namespace: A null-terminated string that indicates the lock namespace.
Locks acquired or waited for by the locking service can be monitored at the SQL level using the Performance Schema. For details, see Locking Service Monitoring.
This section describes how to use the locking service user-defined function (UDF) interface. To use the C language interface instead, see Section 5.6.8.1.1, “The Locking Service C Interface” For general characteristics of the locking service interface, see Section 5.6.8.1, “The Locking Service”. For general information about user-defined functions, see Adding a User-Defined Function.
The locking service routines described in Section 5.6.8.1.1, “The Locking Service C Interface” need not be installed because they are built into the server. The same is not true of the user-defined functions (UDFs) that map onto calls to the service routines: The UDFs must be installed before use. This section describes how to do that. For general information about UDF installation, see Section 5.7.1, “Installing and Uninstalling User-Defined Functions”.
The locking service UDFs are implemented in a plugin library
file located in the directory named by the
plugin_dir system variable.
The file base name is locking_service.
The file name suffix differs per platform (for example,
.so for Unix and Unix-like systems,
.dll for Windows).
To install the locking service UDFs, use the
CREATE FUNCTION statement,
adjusting the .so suffix for your
platform as necessary:
CREATE FUNCTION service_get_read_locks RETURNS INT SONAME 'locking_service.so'; CREATE FUNCTION service_get_write_locks RETURNS INT SONAME 'locking_service.so'; CREATE FUNCTION service_release_locks RETURNS INT SONAME 'locking_service.so';
If the UDFs are used on a source replication server, install them on all replica servers as well to avoid replication problems.
Once installed, the UDFs remain installed until uninstalled.
To remove them, use the DROP
FUNCTION statement:
DROP FUNCTION service_get_read_locks; DROP FUNCTION service_get_write_locks; DROP FUNCTION service_release_locks;
Before using the locking service UDFs, install them according to the instructions provided at Installing or Uninstalling the UDF Locking Interface.
To acquire one or more read locks, call this function:
mysql> SELECT service_get_read_locks('mynamespace', 'rlock1', 'rlock2', 10);
+---------------------------------------------------------------+
| service_get_read_locks('mynamespace', 'rlock1', 'rlock2', 10) |
+---------------------------------------------------------------+
| 1 |
+---------------------------------------------------------------+
The first argument is the lock namespace. The final argument is an integer timeout indicating how many seconds to wait to acquire the locks before giving up. The arguments in between are the lock names.
For the example just shown, the function acquires locks with
lock identifiers (mynamespace, rlock1)
and (mynamespace, rlock2).
To acquire write locks rather than read locks, call this function:
mysql> SELECT service_get_write_locks('mynamespace', 'wlock1', 'wlock2', 10);
+----------------------------------------------------------------+
| service_get_write_locks('mynamespace', 'wlock1', 'wlock2', 10) |
+----------------------------------------------------------------+
| 1 |
+----------------------------------------------------------------+
In this case, the lock identifiers are
(mynamespace, wlock1) and
(mynamespace, wlock2).
To release all locks for a namespace, use this function:
mysql> SELECT service_release_locks('mynamespace');
+--------------------------------------+
| service_release_locks('mynamespace') |
+--------------------------------------+
| 1 |
+--------------------------------------+
Each locking function returns nonzero for success. If the function fails, an error occurs. For example, the following error occurs because lock names cannot be empty:
mysql> SELECT service_get_read_locks('mynamespace', '', 10);
ERROR 3131 (42000): Incorrect locking service lock name ''.
A session can acquire multiple locks for the same lock identifier. As long as a different session does not have a write lock for an identifier, the session can acquire any number of read or write locks. Each lock request for the identifier acquires a new lock. The following statements acquire three write locks with the same identifier, then three read locks for the same identifier:
SELECT service_get_write_locks('ns', 'lock1', 'lock1', 'lock1', 0);
SELECT service_get_read_locks('ns', 'lock1', 'lock1', 'lock1', 0);
If you examine the Performance Schema
metadata_locks table at this point, you
should find that the session holds six distinct locks with
the same (ns, lock1) identifier. (For
details, see Locking Service Monitoring.)
Because the session holds at least one write lock on
(ns, lock1), no other session can acquire
a lock for it, either read or write. If the session held
only read locks for the identifier, other sessions could
acquire read locks for it, but not write locks.
Locks for a single lock-acquisition call are acquired
atomically, but atomicity does not hold across calls. Thus,
for a statement such as the following, where
service_get_write_locks() is
called once per row of the result set, atomicity holds for
each individual call, but not for the statement as a whole:
SELECT service_get_write_locks('ns', 'lock1', 'lock2', 0) FROM t1 WHERE ... ;
Because the locking service returns a separate lock for each successful request for a given lock identifier, it is possible for a single statement to acquire a large number of locks. For example:
INSERT INTO ... SELECT service_get_write_locks('ns', t1.col_name, 0) FROM t1;
These types of statements may have certain adverse effects. For example, if the statement fails part way through and rolls back, locks acquired up to the point of failure still exist. If the intent is for there to be a correspondence between rows inserted and locks acquired, that intent is not satisfied. Also, if it is important that locks are granted in a certain order, be aware that result set order may differ depending on which execution plan the optimizer chooses. For these reasons, it may be best to limit applications to a single lock-acquisition call per statement.
The locking service is implemented using the MySQL Server
metadata locks framework, so you monitor locking service
locks acquired or waited for by examining the Performance
Schema metadata_locks table.
First, enable the metadata lock instrument:
mysql>UPDATE performance_schema.setup_instruments SET ENABLED = 'YES'->WHERE NAME = 'wait/lock/metadata/sql/mdl';
Then acquire some locks and check the contents of the
metadata_locks table:
mysql>SELECT service_get_write_locks('mynamespace', 'lock1', 0);+----------------------------------------------------+ | service_get_write_locks('mynamespace', 'lock1', 0) | +----------------------------------------------------+ | 1 | +----------------------------------------------------+ mysql>SELECT service_get_read_locks('mynamespace', 'lock2', 0);+---------------------------------------------------+ | service_get_read_locks('mynamespace', 'lock2', 0) | +---------------------------------------------------+ | 1 | +---------------------------------------------------+ mysql>SELECT OBJECT_TYPE, OBJECT_SCHEMA, OBJECT_NAME, LOCK_TYPE, LOCK_STATUS->FROM performance_schema.metadata_locks->WHERE OBJECT_TYPE = 'LOCKING SERVICE'\G*************************** 1. row *************************** OBJECT_TYPE: LOCKING SERVICE OBJECT_SCHEMA: mynamespace OBJECT_NAME: lock1 LOCK_TYPE: EXCLUSIVE LOCK_STATUS: GRANTED *************************** 2. row *************************** OBJECT_TYPE: LOCKING SERVICE OBJECT_SCHEMA: mynamespace OBJECT_NAME: lock2 LOCK_TYPE: SHARED LOCK_STATUS: GRANTED
Locking service locks have an OBJECT_TYPE
value of LOCKING SERVICE. This is
distinct from, for example, locks acquired with the
GET_LOCK() function, which
have an OBJECT_TYPE of USER
LEVEL LOCK.
The lock namespace, name, and mode appear in the
OBJECT_SCHEMA,
OBJECT_NAME, and
LOCK_TYPE columns. Read and write locks
have LOCK_TYPE values of
SHARED and EXCLUSIVE,
respectively.
The LOCK_STATUS value is
GRANTED for an acquired lock,
PENDING for a lock that is being waited
for. You can expect to see PENDING if one
session holds a write lock and another session is attempting
to acquire a lock having the same identifier.
The SQL interface to the locking service implements the user-defined functions described in this section. For usage examples, see Using the UDF Locking Interface.
The functions share these characteristics:
The return value is nonzero for success. Otherwise, an error occurs.
Namespace and lock names must be non-
NULL, nonempty, and have a maximum length of 64 characters.Timeout values must be integers indicating how many seconds to wait to acquire locks before giving up with an error. If the timeout is 0, there is no waiting and the function produces an error if locks cannot be acquired immediately.
These locking service UDFs are available:
service_get_read_locks(namespace,lock_name[,lock_name] ...,timeout)Acquires one or more read (shared) locks in the given namespace using the given lock names, timing out with an error if the locks are not acquired within the given timeout value.
service_get_write_locks(namespace,lock_name[,lock_name] ...,timeout)Acquires one or more write (exclusive) locks in the given namespace using the given lock names, timing out with an error if the locks are not acquired within the given timeout value.
service_release_locks(namespace)For the given namespace, releases all locks that were acquired within the current session using
service_get_read_locks()andservice_get_write_locks().It is not an error for there to be no locks in the namespace.
MySQL Server supports a keyring service that enables internal components and plugins to securely store sensitive information for later retrieval. MySQL distributions provide a keyring interface that is accessible at two levels:
At the SQL level, as a set of user-defined functions (UDFs) that map onto calls to the service routines.
As a C language interface, callable as a plugin service from server plugins or user-defined functions.
This section describes how to use the keyring service functions to store, retrieve, and remove keys in the MySQL keyring keystore. For information about the SQL interface that uses UDFs, Section 6.4.4.10, “General-Purpose Keyring Key-Management Functions”. For general keyring information, see Section 6.4.4, “The MySQL Keyring”.
The keyring service uses whatever underlying keyring plugin is enabled, if any. If no keyring plugin is enabled, keyring service calls fail.
A “record” in the keystore consists of data (the key itself) and a unique identifier through which the key is accessed. The identifier has two parts:
key_id: The key ID or name.key_idvalues that begin withmysql_are reserved by MySQL Server.user_id: The session effective user ID. If there is no user context, this value can beNULL. The value need not actually be a “user”; the meaning depends on the application.Functions that implement the keyring UDF interface pass the value of
CURRENT_USER()as theuser_idvalue to keyring service functions.
The keyring service functions have these characteristics in common:
Each function returns 0 for success, 1 for failure.
The
key_idanduser_idarguments form a unique combination indicating which key in the keyring to use.The
key_typeargument provides additional information about the key, such as its encryption method or intended use.Keyring service functions treat key IDs, user names, types, and values as binary strings, so comparisons are case-sensitive. For example, IDs of
MyKeyandmykeyrefer to different keys.
These keyring service functions are available:
my_key_fetch()Deobfuscates and retrieves a key from the keyring, along with its type. The function allocates the memory for the buffers used to store the returned key and key type. The caller should zero or obfuscate the memory when it is no longer needed, then free it.
Syntax:
bool my_key_fetch(const char *key_id, const char **key_type, const char* user_id, void **key, size_t *key_len)Arguments:
key_id,user_id: Null-terminated strings that as a pair form a unique identifier indicating which key to fetch.key_type: The address of a buffer pointer. The function stores into it a pointer to a null-terminated string that provides additional information about the key (stored when the key was added).key: The address of a buffer pointer. The function stores into it a pointer to the buffer containing the fetched key data.key_len: The address of a variable into which the function stores the size in bytes of the*keybuffer.
Return value:
Returns 0 for success, 1 for failure.
my_key_generate()Generates a new random key of a given type and length and stores it in the keyring. The key has a length of
key_lenand is associated with the identifier formed fromkey_idanduser_id. The type and length values must be consistent with the values supported by the underlying keyring plugin. See Section 6.4.4.8, “Supported Keyring Key Types and Lengths”.Syntax:
bool my_key_generate(const char *key_id, const char *key_type, const char *user_id, size_t key_len)Arguments:
key_id,user_id: Null-terminated strings that as a pair form a unique identifier for the key to be generated.key_type: A null-terminated string that provides additional information about the key.key_len: The size in bytes of the key to be generated.
Return value:
Returns 0 for success, 1 for failure.
my_key_remove()Removes a key from the keyring.
Syntax:
bool my_key_remove(const char *key_id, const char* user_id)
Arguments:
key_id,user_id: Null-terminated strings that as a pair form a unique identifier for the key to be removed.
Return value:
Returns 0 for success, 1 for failure.
my_key_store()Obfuscates and stores a key in the keyring.
Syntax:
bool my_key_store(const char *key_id, const char *key_type, const char* user_id, void *key, size_t key_len)Arguments:
key_id,user_id: Null-terminated strings that as a pair form a unique identifier for the key to be stored.key_type: A null-terminated string that provides additional information about the key.key: The buffer containing the key data to be stored.key_len: The size in bytes of thekeybuffer.
Return value:
Returns 0 for success, 1 for failure.
MySQL Server enables user-defined functions (UDFs) to be created and loaded to extend server capabilities. Server capabilities can be implemented in whole or in part using UDFs. In addition, you can write your own UDFs.
MySQL distributions include UDFs that implement, or help to implement, several server capabilities:
Group Replication enables you to create a highly available distributed MySQL service across a group of MySQL server instances, with data consistency, conflict detection and resolution, and group membership services all built-in. See Chapter 18, Group Replication.
MySQL Enterprise Edition includes UDFs that perform encryption operations based on the OpenSSL library. See Section 6.6, “MySQL Enterprise Encryption”.
MySQL Enterprise Edition includes UDFs that provide an SQL-level API for performing masking and de-identification operations. See Section 6.5.1, “MySQL Enterprise Data Masking and De-Identification Elements”.
MySQL Enterprise Edition includes audit logging for monitoring and logging of connection and query activity. See Section 6.4.5, “MySQL Enterprise Audit”, and Section 6.4.6, “The Audit Message Component”.
MySQL Enterprise Edition includes a firewall capability that implements an application-level firewall to enable database administrators to permit or deny SQL statement execution based on matching against allowlists of accepted statement patterns. See Section 6.4.7, “MySQL Enterprise Firewall”.
A query rewriter examines statements received by MySQL Server and possibly rewrites them before the server executes them. See Section 5.6.4, “The Rewriter Query Rewrite Plugin”
Version Tokens enables creation of and synchronization around server tokens that applications can use to prevent accessing incorrect or out-of-date data. See Section 5.6.6, “Version Tokens”.
The MySQL Keyring provides secure storage for sensitive information. See Section 6.4.4, “The MySQL Keyring”.
A locking service provides a locking interface for application use. See Section 5.6.8.1, “The Locking Service”.
A UDF for accessing query attributes. See Section 9.6, “Query Attributes”.
The following sections describe how to install and uninstall UDFs, and how to determine at runtime which UDFs are installed and obtain information about them. For a table listing user-defined functions, see Section 12.2, “User-Defined Function Reference”. For information about writing UDFs, see Adding Functions to MySQL.
In some cases, a UDF is installed by installing the component that implements it, rather than by installing the UDF directly. For details about a particular UDF, see the installation instructions for the server feature that includes it.
User-defined functions (UDFs) must be loaded into the server before they can be used. MySQL supports manual UDF loading at runtime and automatic loading during server startup.
While a UDF is loaded, information about it is available as described in Section 5.7.2, “Obtaining User-Defined Function Information”.
To load a UDF manually, use the
CREATE
FUNCTION statement. For example:
CREATE FUNCTION metaphon RETURNS STRING SONAME 'udf_example.so';
The UDF file base name depends on your platform. Common suffixes
are .so for Unix and Unix-like systems,
.dll for Windows.
CREATE
FUNCTION has these effects:
It loads the UDF into the server to make it available immediately.
It registers the UDF in the
mysql.funcsystem table to make it persistent across server restarts. For this reason,CREATE FUNCTIONrequires theINSERTprivilege for themysqlsystem database.It adds the UDF to the Performance Schema
user_defined_functionstable that provides runtime information about installed UDFs. See Section 5.7.2, “Obtaining User-Defined Function Information”.
Automatic UDF loading occurs during the normal server startup sequence:
UDFs registered in the
mysql.functable are installed.Components or plugins that are installed at startup may automatically install related UDFs.
Automatic UDF installation adds the UDFs to the Performance Schema
user_defined_functionstable that provides runtime information about installed UDFs.
If the server is started with the
--skip-grant-tables option, UDFs
registered in the mysql.func table are not
loaded and are unavailable. This does not apply to UDFs
installed automatically by a component or plugin.
To remove a UDF, use the
DROP
FUNCTION statement. For example:
DROP FUNCTION metaphon;
DROP
FUNCTION has these effects:
It unloads the UDF to make it unavailable.
It removes the UDF from the
mysql.funcsystem table. For this reason,DROP FUNCTIONrequires theDELETEprivilege for themysqlsystem database. With the UDF no longer registered in themysql.functable, the server does not load the UDF during subsequent restarts.It removes the UDF from the Performance Schema
user_defined_functionstable that provides runtime information about installed UDFs.
DROP
FUNCTION cannot be used to drop a UDF that is
installed automatically by components or plugins rather than by
using
CREATE
FUNCTION. Such a UDF is also dropped automatically,
when the component or plugin that installed it is uninstalled.
To reinstall or upgrade the shared library associated with a
UDF, issue a
DROP
FUNCTION statement, upgrade the shared library, and
then issue a
CREATE
FUNCTION statement. If you upgrade the shared library
first and then use
DROP
FUNCTION, the server may unexpectedly shut down.
The Performance Schema
user_defined_functions table contains
information about the currently installed user-defined functions
(UDFs):
SELECT * FROM performance_schema.user_defined_functions;
The mysql.func system table also lists
installed UDFs, but only those installed using
CREATE
FUNCTION. The
user_defined_functions table lists
UDFs installed using
CREATE
FUNCTION as well as UDFs installed automatically by
components or plugins. This difference makes
user_defined_functions preferable to
mysql.func for checking which UDFs are
installed. See
Section 27.12.19.9, “The user_defined_functions Table”.
mysql_query_attribute_string(name)Applications can define attributes that apply to the next query sent to the server. The
mysql_query_attribute_string()function, available as of MySQL 8.0.23, returns an attribute value as a string, given the attribute name. This function enables a query to access and incorporate values of the attributes that apply to it.mysql_query_attribute_string()is installed by installing thequery_attributescomponent. See Section 9.6, “Query Attributes”, which also discusses the purpose and use of query attributes.Arguments:
name: The attribute name.
Return value:
Returns the attribute value as a string for success, or
NULLif the attribute does not exist.Example:
The following example uses the mysql client
query_attributescommand to define query attributes that can be retrieved bymysql_query_attribute_string(). TheSELECTshows that retrieving a nonexistent attribute (n3) returnsNULL.mysql> query_attributes n1 v1 n2 v2; mysql> SELECT -> mysql_query_attribute_string('n1') AS 'attr 1', -> mysql_query_attribute_string('n2') AS 'attr 2', -> mysql_query_attribute_string('n3') AS 'attr 3'; +--------+--------+--------+ | attr 1 | attr 2 | attr 3 | +--------+--------+--------+ | v1 | v2 | NULL | +--------+--------+--------+For additional examples, see Section 9.6, “Query Attributes”.
In some cases, you might want to run multiple instances of MySQL on a single machine. You might want to test a new MySQL release while leaving an existing production setup undisturbed. Or you might want to give different users access to different mysqld servers that they manage themselves. (For example, you might be an Internet Service Provider that wants to provide independent MySQL installations for different customers.)
It is possible to use a different MySQL server binary per instance, or use the same binary for multiple instances, or any combination of the two approaches. For example, you might run a server from MySQL 5.7 and one from MySQL 8.0, to see how different versions handle a given workload. Or you might run multiple instances of the current production version, each managing a different set of databases.
Whether or not you use distinct server binaries, each instance that
you run must be configured with unique values for several operating
parameters. This eliminates the potential for conflict between
instances. Parameters can be set on the command line, in option
files, or by setting environment variables. See
Section 4.2.2, “Specifying Program Options”. To see the values used by a given
instance, connect to it and execute a SHOW
VARIABLES statement.
The primary resource managed by a MySQL instance is the data
directory. Each instance should use a different data directory, the
location of which is specified using the
--datadir=
option. For methods of configuring each instance with its own data
directory, and warnings about the dangers of failing to do so, see
Section 5.8.1, “Setting Up Multiple Data Directories”.
dir_name
In addition to using different data directories, several other options must have different values for each server instance:
--portcontrols the port number for TCP/IP connections. Alternatively, if the host has multiple network addresses, you can set thebind_addresssystem variable to cause each server to listen to a different address.--socket={file_name|pipe_name}--socketcontrols the Unix socket file path on Unix or the named-pipe name on Windows. On Windows, it is necessary to specify distinct pipe names only for those servers configured to permit named-pipe connections.--shared-memory-base-name=nameThis option is used only on Windows. It designates the shared-memory name used by a Windows server to permit clients to connect using shared memory. It is necessary to specify distinct shared-memory names only for those servers configured to permit shared-memory connections.
This option indicates the path name of the file in which the server writes its process ID.
If you use the following log file options, their values must differ for each server:
For further discussion of log file options, see Section 5.4, “MySQL Server Logs”.
To achieve better performance, you can specify the following option differently for each server, to spread the load between several physical disks:
Having different temporary directories also makes it easier to determine which MySQL server created any given temporary file.
If you have multiple MySQL installations in different locations, you
can specify the base directory for each installation with the
--basedir=
option. This causes each instance to automatically use a different
data directory, log files, and PID file because the default for each
of those parameters is relative to the base directory. In that case,
the only other options you need to specify are the
dir_name--socket and
--port options. Suppose that you
install different versions of MySQL using tar
file binary distributions. These install in different locations, so
you can start the server for each installation using the command
bin/mysqld_safe under its corresponding base
directory. mysqld_safe determines the proper
--basedir option to pass to
mysqld, and you need specify only the
--socket and
--port options to
mysqld_safe.
As discussed in the following sections, it is possible to start
additional servers by specifying appropriate command options or by
setting environment variables. However, if you need to run multiple
servers on a more permanent basis, it is more convenient to use
option files to specify for each server those option values that
must be unique to it. The
--defaults-file option is useful for
this purpose.
Each MySQL Instance on a machine should have its own data
directory. The location is specified using the
--datadir=
option.
dir_name
There are different methods of setting up a data directory for a new instance:
Create a new data directory.
Copy an existing data directory.
The following discussion provides more detail about each method.
Normally, you should never have two servers that update data in the same databases. This may lead to unpleasant surprises if your operating system does not support fault-free system locking. If (despite this warning) you run multiple servers using the same data directory and they have logging enabled, you must use the appropriate options to specify log file names that are unique to each server. Otherwise, the servers try to log to the same files.
Even when the preceding precautions are observed, this kind of
setup works only with MyISAM and
MERGE tables, and not with any of the other
storage engines. Also, this warning against sharing a data
directory among servers always applies in an NFS environment.
Permitting multiple MySQL servers to access a common data
directory over NFS is a very bad idea. The
primary problem is that NFS is the speed bottleneck. It is not
meant for such use. Another risk with NFS is that you must
devise a way to ensure that two or more servers do not interfere
with each other. Usually NFS file locking is handled by the
lockd daemon, but at the moment there is no
platform that performs locking 100% reliably in every situation.
Create a New Data Directory
With this method, the data directory is in the same state as when you first install MySQL, and has the default set of MySQL accounts and no user data.
On Unix, initialize the data directory. See Section 2.10, “Postinstallation Setup and Testing”.
On Windows, the data directory is included in the MySQL distribution:
MySQL Zip archive distributions for Windows contain an unmodified data directory. You can unpack such a distribution into a temporary location, then copy it
datadirectory to where you are setting up the new instance.Windows MSI package installers create and set up the data directory that the installed server uses, but also create a pristine “template” data directory named
dataunder the installation directory. After an installation has been performed using an MSI package, the template data directory can be copied to set up additional MySQL instances.
Copy an Existing Data Directory
With this method, any MySQL accounts or user data present in the data directory are carried over to the new data directory.
Stop the existing MySQL instance using the data directory. This must be a clean shutdown so that the instance flushes any pending changes to disk.
Copy the data directory to the location where the new data directory should be.
Copy the
my.cnformy.inioption file used by the existing instance. This serves as a basis for the new instance.Modify the new option file so that any pathnames referring to the original data directory refer to the new data directory. Also, modify any other options that must be unique per instance, such as the TCP/IP port number and the log files. For a list of parameters that must be unique per instance, see Section 5.8, “Running Multiple MySQL Instances on One Machine”.
Start the new instance, telling it to use the new option file.
You can run multiple servers on Windows by starting them manually from the command line, each with appropriate operating parameters, or by installing several servers as Windows services and running them that way. General instructions for running MySQL from the command line or as a service are given in Section 2.3, “Installing MySQL on Microsoft Windows”. The following sections describe how to start each server with different values for those options that must be unique per server, such as the data directory. These options are listed in Section 5.8, “Running Multiple MySQL Instances on One Machine”.
The procedure for starting a single MySQL server manually from
the command line is described in
Section 2.3.4.6, “Starting MySQL from the Windows Command Line”. To start multiple
servers this way, you can specify the appropriate options on the
command line or in an option file. It is more convenient to
place the options in an option file, but it is necessary to make
sure that each server gets its own set of options. To do this,
create an option file for each server and tell the server the
file name with a --defaults-file
option when you run it.
Suppose that you want to run one instance of
mysqld on port 3307 with a data directory of
C:\mydata1, and another instance on port
3308 with a data directory of C:\mydata2.
Use this procedure:
Make sure that each data directory exists, including its own copy of the
mysqldatabase that contains the grant tables.Create two option files. For example, create one file named
C:\my-opts1.cnfthat looks like this:[mysqld] datadir = C:/mydata1 port = 3307
Create a second file named
C:\my-opts2.cnfthat looks like this:[mysqld] datadir = C:/mydata2 port = 3308
Use the
--defaults-fileoption to start each server with its own option file:C:\>
C:\mysql\bin\mysqld --defaults-file=C:\my-opts1.cnfC:\>C:\mysql\bin\mysqld --defaults-file=C:\my-opts2.cnfEach server starts in the foreground (no new prompt appears until the server exits later), so you need to issue those two commands in separate console windows.
To shut down the servers, connect to each using the appropriate port number:
C:\>C:\mysql\bin\mysqladmin --port=3307 --host=127.0.0.1 --user=root --password shutdownC:\>C:\mysql\bin\mysqladmin --port=3308 --host=127.0.0.1 --user=root --password shutdown
Servers configured as just described permit clients to connect
over TCP/IP. If your version of Windows supports named pipes and
you also want to permit named-pipe connections, specify options
that enable the named pipe and specify its name. Each server
that supports named-pipe connections must use a unique pipe
name. For example, the C:\my-opts1.cnf file
might be written like this:
[mysqld] datadir = C:/mydata1 port = 3307 enable-named-pipe socket = mypipe1
Modify C:\my-opts2.cnf similarly for use by
the second server. Then start the servers as described
previously.
A similar procedure applies for servers that you want to permit
shared-memory connections. Enable such connections by starting
the server with the
shared_memory system variable
enabled and specify a unique shared-memory name for each server
by setting the
shared_memory_base_name system
variable.
On Windows, a MySQL server can run as a Windows service. The procedures for installing, controlling, and removing a single MySQL service are described in Section 2.3.4.8, “Starting MySQL as a Windows Service”.
To set up multiple MySQL services, you must make sure that each instance uses a different service name in addition to the other parameters that must be unique per instance.
For the following instructions, suppose that you want to run the
mysqld server from two different versions of
MySQL that are installed at C:\mysql-5.5.9
and C:\mysql-8.0.24,
respectively. (This might be the case if you are running 5.5.9
as your production server, but also want to conduct tests using
8.0.24.)
To install MySQL as a Windows service, use the
--install or --install-manual
option. For information about these options, see
Section 2.3.4.8, “Starting MySQL as a Windows Service”.
Based on the preceding information, you have several ways to set up multiple services. The following instructions describe some examples. Before trying any of them, shut down and remove any existing MySQL services.
Approach 1: Specify the options for all services in one of the standard option files. To do this, use a different service name for each server. Suppose that you want to run the 5.5.9 mysqld using the service name of
mysqld1and the 8.0.24 mysqld using the service namemysqld2. In this case, you can use the[mysqld1]group for 5.5.9 and the[mysqld2]group for 8.0.24. For example, you can set upC:\my.cnflike this:# options for mysqld1 service [mysqld1] basedir = C:/mysql-5.5.9 port = 3307 enable-named-pipe socket = mypipe1 # options for mysqld2 service [mysqld2] basedir = C:/mysql-8.0.24 port = 3308 enable-named-pipe socket = mypipe2
Install the services as follows, using the full server path names to ensure that Windows registers the correct executable program for each service:
C:\>
C:\mysql-5.5.9\bin\mysqld --install mysqld1C:\>C:\mysql-8.0.24\bin\mysqld --install mysqld2To start the services, use the services manager, or NET START or SC START with the appropriate service names:
C:\>
SC START mysqld1C:\>SC START mysqld2To stop the services, use the services manager, or use NET STOP or SC STOP with the appropriate service names:
C:\>
SC STOP mysqld1C:\>SC STOP mysqld2Approach 2: Specify options for each server in separate files and use
--defaults-filewhen you install the services to tell each server what file to use. In this case, each file should list options using a[mysqld]group.With this approach, to specify options for the 5.5.9 mysqld, create a file
C:\my-opts1.cnfthat looks like this:[mysqld] basedir = C:/mysql-5.5.9 port = 3307 enable-named-pipe socket = mypipe1
For the 8.0.24 mysqld, create a file
C:\my-opts2.cnfthat looks like this:[mysqld] basedir = C:/mysql-8.0.24 port = 3308 enable-named-pipe socket = mypipe2
Install the services as follows (enter each command on a single line):
C:\>
C:\mysql-5.5.9\bin\mysqld --install mysqld1--defaults-file=C:\my-opts1.cnfC:\>C:\mysql-8.0.24\bin\mysqld --install mysqld2--defaults-file=C:\my-opts2.cnfWhen you install a MySQL server as a service and use a
--defaults-fileoption, the service name must precede the option.After installing the services, start and stop them the same way as in the preceding example.
To remove multiple services, use SC DELETE
mysqld_service_name for
each one. Alternatively, use mysqld --remove
for each one, specifying a service name following the
--remove option. If the service
name is the default (MySQL), you can omit it
when using mysqld --remove.
The discussion here uses mysqld_safe to launch multiple instances of MySQL. For MySQL installation using an RPM distribution, server startup and shutdown is managed by systemd on several Linux platforms. On these platforms, mysqld_safe is not installed because it is unnecessary. For information about using systemd to handle multiple MySQL instances, see Section 2.5.9, “Managing MySQL Server with systemd”.
One way is to run multiple MySQL instances on Unix is to compile different servers with different default TCP/IP ports and Unix socket files so that each one listens on different network interfaces. Compiling in different base directories for each installation also results automatically in a separate, compiled-in data directory, log file, and PID file location for each server.
Assume that an existing 5.7 server is configured for
the default TCP/IP port number (3306) and Unix socket file
(/tmp/mysql.sock). To configure a new
8.0.24 server to have different operating parameters,
use a CMake command something like this:
shell>cmake . -DMYSQL_TCP_PORT=port_number\-DMYSQL_UNIX_ADDR=file_name\-DCMAKE_INSTALL_PREFIX=/usr/local/mysql-8.0.24
Here, port_number and
file_name must be different from the
default TCP/IP port number and Unix socket file path name, and the
CMAKE_INSTALL_PREFIX value should
specify an installation directory different from the one under
which the existing MySQL installation is located.
If you have a MySQL server listening on a given port number, you can use the following command to find out what operating parameters it is using for several important configurable variables, including the base directory and Unix socket file name:
shell> mysqladmin --host=host_name --port=port_number variables
With the information displayed by that command, you can tell what option values not to use when configuring an additional server.
If you specify localhost as the host name,
mysqladmin defaults to using a Unix socket file
rather than TCP/IP. To explicitly specify the transport protocol,
use the
--protocol={TCP|SOCKET|PIPE|MEMORY}
option.
You need not compile a new MySQL server just to start with a different Unix socket file and TCP/IP port number. It is also possible to use the same server binary and start each invocation of it with different parameter values at runtime. One way to do so is by using command-line options:
shell> mysqld_safe --socket=file_name --port=port_number
To start a second server, provide different
--socket and
--port option values, and pass a
--datadir=
option to mysqld_safe so that the server uses a
different data directory.
dir_name
Alternatively, put the options for each server in a different
option file, then start each server using a
--defaults-file option that
specifies the path to the appropriate option file. For example, if
the option files for two server instances are named
/usr/local/mysql/my.cnf and
/usr/local/mysql/my.cnf2, start the servers
like this: command:
shell>mysqld_safe --defaults-file=/usr/local/mysql/my.cnfshell>mysqld_safe --defaults-file=/usr/local/mysql/my.cnf2
Another way to achieve a similar effect is to use environment variables to set the Unix socket file name and TCP/IP port number:
shell>MYSQL_UNIX_PORT=/tmp/mysqld-new.sockshell>MYSQL_TCP_PORT=3307shell>export MYSQL_UNIX_PORT MYSQL_TCP_PORTshell>bin/mysqld --initialize --user=mysqlshell>mysqld_safe --datadir=/path/to/datadir &
This is a quick way of starting a second server to use for testing. The nice thing about this method is that the environment variable settings apply to any client programs that you invoke from the same shell. Thus, connections for those clients are automatically directed to the second server.
Section 4.9, “Environment Variables”, includes a list of other environment variables you can use to affect MySQL programs.
On Unix, the mysqld_multi script provides another way to start multiple servers. See Section 4.3.4, “mysqld_multi — Manage Multiple MySQL Servers”.
To connect with a client program to a MySQL server that is listening to different network interfaces from those compiled into your client, you can use one of the following methods:
Start the client with
--host=host_name--port=to connect using TCP/IP to a remote server, withport_number--host=127.0.0.1--port=to connect using TCP/IP to a local server, or withport_number--host=localhost--socket=to connect to a local server using a Unix socket file or a Windows named pipe.file_nameStart the client with
--protocol=TCPto connect using TCP/IP,--protocol=SOCKETto connect using a Unix socket file,--protocol=PIPEto connect using a named pipe, or--protocol=MEMORYto connect using shared memory. For TCP/IP connections, you may also need to specify--hostand--portoptions. For the other types of connections, you may need to specify a--socketoption to specify a Unix socket file or Windows named-pipe name, or a--shared-memory-base-nameoption to specify the shared-memory name. Shared-memory connections are supported only on Windows.On Unix, set the
MYSQL_UNIX_PORTandMYSQL_TCP_PORTenvironment variables to point to the Unix socket file and TCP/IP port number before you start your clients. If you normally use a specific socket file or port number, you can place commands to set these environment variables in your.loginfile so that they apply each time you log in. See Section 4.9, “Environment Variables”.Specify the default Unix socket file and TCP/IP port number in the
[client]group of an option file. For example, you can useC:\my.cnfon Windows, or the.my.cnffile in your home directory on Unix. See Section 4.2.2.2, “Using Option Files”.In a C program, you can specify the socket file or port number arguments in the
mysql_real_connect()call. You can also have the program read option files by callingmysql_options(). See C API Function Descriptions.If you are using the Perl
DBD::mysqlmodule, you can read options from MySQL option files. For example:$dsn = "DBI:mysql:test;mysql_read_default_group=client;" . "mysql_read_default_file=/usr/local/mysql/data/my.cnf"; $dbh = DBI->connect($dsn, $user, $password);See Section 29.9, “MySQL Perl API”.
Other programming interfaces may provide similar capabilities for reading option files.
This section describes debugging techniques that assist efforts to track down problems in MySQL.
- 5.9.1.1 Compiling MySQL for Debugging
- 5.9.1.2 Creating Trace Files
- 5.9.1.3 Using WER with PDB to create a Windows crashdump
- 5.9.1.4 Debugging mysqld under gdb
- 5.9.1.5 Using a Stack Trace
- 5.9.1.6 Using Server Logs to Find Causes of Errors in mysqld
- 5.9.1.7 Making a Test Case If You Experience Table Corruption
If you are using some functionality that is very new in MySQL, you
can try to run mysqld with the
--skip-new option (which disables
all new, potentially unsafe functionality). See
Section B.3.3.3, “What to Do If MySQL Keeps Crashing”.
If mysqld does not want to start, verify that
you have no my.cnf files that interfere with
your setup! You can check your my.cnf
arguments with mysqld --print-defaults and
avoid using them by starting with mysqld --no-defaults
....
If mysqld starts to eat up CPU or memory or if it “hangs,” you can use mysqladmin processlist status to find out if someone is executing a query that takes a long time. It may be a good idea to run mysqladmin -i10 processlist status in some window if you are experiencing performance problems or problems when new clients cannot connect.
The command mysqladmin debug dumps some information about locks in use, used memory and query usage to the MySQL log file. This may help solve some problems. This command also provides some useful information even if you have not compiled MySQL for debugging!
If the problem is that some tables are getting slower and slower
you should try to optimize the table with
OPTIMIZE TABLE or
myisamchk. See
Chapter 5, MySQL Server Administration. You should also check the
slow queries with EXPLAIN.
You should also read the OS-specific section in this manual for problems that may be unique to your environment. See Section 2.1, “General Installation Guidance”.
If you have some very specific problem, you can always try to
debug MySQL. To do this you must configure MySQL with the
-DWITH_DEBUG=1 option. You can
check whether MySQL was compiled with debugging by doing:
mysqld --help. If the
--debug flag is listed with the
options then you have debugging enabled. mysqladmin
ver also lists the mysqld version
as mysql ... --debug in this case.
If mysqld stops crashing when you configure
it with the -DWITH_DEBUG=1 CMake
option, you probably have found a compiler bug or a timing bug
within MySQL. In this case, you can try to add
-g using the
CMAKE_C_FLAGS and
CMAKE_CXX_FLAGS CMake options and
not use -DWITH_DEBUG=1. If
mysqld dies, you can at least attach to it
with gdb or use gdb on the
core file to find out what happened.
When you configure MySQL for debugging you automatically enable
a lot of extra safety check functions that monitor the health of
mysqld. If they find something
“unexpected,” an entry is written to
stderr, which mysqld_safe
directs to the error log! This also means that if you are having
some unexpected problems with MySQL and are using a source
distribution, the first thing you should do is to configure
MySQL for debugging. If you believe that you have found a bug,
please use the instructions at Section 1.6, “How to Report Bugs or Problems”.
In the Windows MySQL distribution, mysqld.exe
is by default compiled with support for trace files.
If the mysqld server does not start or it crashes easily, you can try to create a trace file to find the problem.
To do this, you must have a mysqld that has
been compiled with debugging support. You can check this by
executing mysqld -V. If the version number
ends with -debug, it is compiled with support
for trace files. (On Windows, the debugging server is named
mysqld-debug rather than
mysqld.)
Start the mysqld server with a trace log in
/tmp/mysqld.trace on Unix or
\mysqld.trace on Windows:
shell> mysqld --debug
On Windows, you should also use the
--standalone flag to not start
mysqld as a service. In a console window, use
this command:
C:\> mysqld-debug --debug --standalone
After this, you can use the mysql.exe
command-line tool in a second console window to reproduce the
problem. You can stop the mysqld server with
mysqladmin shutdown.
The trace file can become very large! To generate a smaller trace file, you can use debugging options something like this:
mysqld --debug=d,info,error,query,general,where:O,/tmp/mysqld.trace
This only prints information with the most interesting tags to the trace file.
If you file a bug, please add only those lines from the trace file to the bug report that indicate where something seems to go wrong. If you cannot locate the wrong place, open a bug report and upload the whole trace file to the report, so that a MySQL developer can take a look at it. For instructions, see Section 1.6, “How to Report Bugs or Problems”.
The trace file is made with the DBUG package by Fred Fish. See Section 5.9.4, “The DBUG Package”.
Program Database files (with suffix pdb)
are included in the ZIP Archive Debug
Binaries & Test Suite distribution of MySQL.
These files provide information for debugging your MySQL
installation in the event of a problem. This is a separate
download from the standard MSI or Zip file.
The PDB files are available in a separate file labeled "ZIP Archive Debug Binaries & Test Suite".
The PDB file contains more detailed information about
mysqld and other tools that enables more
detailed trace and dump files to be created. You can use these
with WinDbg or Visual Studio to debug
mysqld.
For more information on PDB files, see Microsoft Knowledge Base Article 121366. For more information on the debugging options available, see Debugging Tools for Windows.
To use WinDbg, either install the full Windows Driver Kit (WDK) or install the standalone version.
The .exe and .pdb
files must be an exact match (both version number and MySQL
server edition); otherwise, or WinDBG complains while
attempting to load the symbols.
To generate a minidump
mysqld.dmp, enable thecore-fileoption under the [mysqld] section inmy.ini. Restart the MySQL server after making these changes.Create a directory to store the generated files, such as
c:\symbolsDetermine the path to your windbg.exe executable using the Find GUI or from the command line, for example:
dir /s /b windbg.exe-- a common default is C:\Program Files\Debugging Tools for Windows (x64)\windbg.exeLaunch
windbg.exegiving it the paths tomysqld.exe,mysqld.pdb,mysqld.dmp, and the source code. Alternatively, pass in each path from the WinDbg GUI. For example:windbg.exe -i "C:\mysql-8.0.24-winx64\bin\"^ -z "C:\mysql-8.0.24-winx64\data\mysqld.dmp"^ -srcpath "E:\ade\mysql_archives\8.0\8.0.24\mysql-8.0.24"^ -y "C:\mysql-8.0.24-winx64\bin;SRV*c:\symbols*http://msdl.microsoft.com/download/symbols"^ -v -n -c "!analyze -vvvvv"
NoteThe
^character and newline are removed by the Windows command line processor, so be sure the spaces remain intact.
On most systems you can also start mysqld from gdb to get more information if mysqld crashes.
With some older gdb versions on Linux you
must use run --one-thread if you want to be
able to debug mysqld threads. In this case,
you can only have one thread active at a time.
NPTL threads (the new thread library on Linux) may cause problems while running mysqld under gdb. Some symptoms are:
In this case, you should set the following environment variable in the shell before starting gdb:
LD_ASSUME_KERNEL=2.4.1 export LD_ASSUME_KERNEL
When running mysqld under
gdb, you should disable the stack trace with
--skip-stack-trace to be able to
catch segfaults within gdb.
Use the --gdb option to
mysqld to install an interrupt handler for
SIGINT (needed to stop
mysqld with ^C to set
breakpoints) and disable stack tracing and core file handling.
It is very hard to debug MySQL under gdb if
you do a lot of new connections the whole time as
gdb does not free the memory for old threads.
You can avoid this problem by starting mysqld
with thread_cache_size set to a
value equal to max_connections
+ 1. In most cases just using
--thread_cache_size=5' helps a
lot!
If you want to get a core dump on Linux if
mysqld dies with a SIGSEGV signal, you can
start mysqld with the
--core-file option. This core
file can be used to make a backtrace that may help you find out
why mysqld died:
shell> gdb mysqld core
gdb> backtrace full
gdb> quit
See Section B.3.3.3, “What to Do If MySQL Keeps Crashing”.
If you are using gdb on Linux, you should
install a .gdb file, with the following
information, in your current directory:
set print sevenbit off handle SIGUSR1 nostop noprint handle SIGUSR2 nostop noprint handle SIGWAITING nostop noprint handle SIGLWP nostop noprint handle SIGPIPE nostop handle SIGALRM nostop handle SIGHUP nostop handle SIGTERM nostop noprint
Here is an example how to debug mysqld:
shell> gdb /usr/local/libexec/mysqld
gdb> run
...
backtrace full # Do this when mysqld crashes
Include the preceding output in a bug report, which you can file using the instructions in Section 1.6, “How to Report Bugs or Problems”.
If mysqld hangs, you can try to use some
system tools like strace or
/usr/proc/bin/pstack to examine where
mysqld has hung.
strace /tmp/log libexec/mysqld
If you are using the Perl DBI interface, you
can turn on debugging information by using the
trace method or by setting the
DBI_TRACE environment variable.
On some operating systems, the error log contains a stack trace
if mysqld dies unexpectedly. You can use this
to find out where (and maybe why) mysqld
died. See Section 5.4.2, “The Error Log”. To get a stack trace, you
must not compile mysqld with the
-fomit-frame-pointer option to gcc. See
Section 5.9.1.1, “Compiling MySQL for Debugging”.
A stack trace in the error log looks something like this:
mysqld got signal 11; Attempting backtrace. You can use the following information to find out where mysqld died. If you see no messages after this, something went terribly wrong... stack_bottom = 0x41fd0110 thread_stack 0x40000 mysqld(my_print_stacktrace+0x32)[0x9da402] mysqld(handle_segfault+0x28a)[0x6648e9] /lib/libpthread.so.0[0x7f1a5af000f0] /lib/libc.so.6(strcmp+0x2)[0x7f1a5a10f0f2] mysqld(_Z21check_change_passwordP3THDPKcS2_Pcj+0x7c)[0x7412cb] mysqld(_ZN16set_var_password5checkEP3THD+0xd0)[0x688354] mysqld(_Z17sql_set_variablesP3THDP4ListI12set_var_baseE+0x68)[0x688494] mysqld(_Z21mysql_execute_commandP3THD+0x41a0)[0x67a170] mysqld(_Z11mysql_parseP3THDPKcjPS2_+0x282)[0x67f0ad] mysqld(_Z16dispatch_command19enum_server_commandP3THDPcj+0xbb7[0x67fdf8] mysqld(_Z10do_commandP3THD+0x24d)[0x6811b6] mysqld(handle_one_connection+0x11c)[0x66e05e]
If resolution of function names for the trace fails, the trace contains less information:
mysqld got signal 11; Attempting backtrace. You can use the following information to find out where mysqld died. If you see no messages after this, something went terribly wrong... stack_bottom = 0x41fd0110 thread_stack 0x40000 [0x9da402] [0x6648e9] [0x7f1a5af000f0] [0x7f1a5a10f0f2] [0x7412cb] [0x688354] [0x688494] [0x67a170] [0x67f0ad] [0x67fdf8] [0x6811b6] [0x66e05e]
Newer versions of glibc stack trace functions
also print the address as relative to the object. On
glibc-based systems (Linux), the trace for an
unexpected exit within a plugin looks something like:
plugin/auth/auth_test_plugin.so(+0x9a6)[0x7ff4d11c29a6]
To translate the relative address (+0x9a6)
into a file name and line number, use this command:
shell> addr2line -fie auth_test_plugin.so 0x9a6
auth_test_plugin
mysql-trunk/plugin/auth/test_plugin.c:65
The addr2line utility is part of the
binutils package on Linux.
On Solaris, the procedure is similar. The Solaris
printstack() already prints relative
addresses:
plugin/auth/auth_test_plugin.so:0x1510
To translate, use this command:
shell> gaddr2line -fie auth_test_plugin.so 0x1510
mysql-trunk/plugin/auth/test_plugin.c:88
Windows already prints the address, function name and line:
000007FEF07E10A4 auth_test_plugin.dll!auth_test_plugin()[test_plugin.c:72]
Note that before starting mysqld with the general query log enabled, you should check all your tables with myisamchk. See Chapter 5, MySQL Server Administration.
If mysqld dies or hangs, you should start mysqld with the general query log enabled. See Section 5.4.3, “The General Query Log”. When mysqld dies again, you can examine the end of the log file for the query that killed mysqld.
If you use the default general query log file, the log is stored
in the database directory as
host_name.log
You can also try the command
EXPLAIN on all
SELECT statements that takes a
long time to ensure that mysqld is using
indexes properly. See Section 13.8.2, “EXPLAIN Statement”.
You can find the queries that take a long time to execute by starting mysqld with the slow query log enabled. See Section 5.4.5, “The Slow Query Log”.
If you find the text mysqld restarted in the
error log (normally a file named
host_name.err
If you have started mysqld with the
myisam_recover_options system
variable set, MySQL automatically checks and tries to repair
MyISAM tables if they are marked as 'not
closed properly' or 'crashed'. If this happens, MySQL writes an
entry in the hostname.err file
'Warning: Checking table ...' which is
followed by Warning: Repairing table if the
table needs to be repaired. If you get a lot of these errors,
without mysqld having died unexpectedly just
before, then something is wrong and needs to be investigated
further. See Section 5.1.7, “Server Command Options”.
When the server detects MyISAM table
corruption, it writes additional information to the error log,
such as the name and line number of the source file, and the
list of threads accessing the table. Example: Got an
error from thread_id=1, mi_dynrec.c:368. This is
useful information to include in bug reports.
It is not a good sign if mysqld did die
unexpectedly, but in this case, you should not investigate the
Checking table... messages, but instead try
to find out why mysqld died.
The following procedure applies to
MyISAM tables. For information
about steps to take when encountering InnoDB
table corruption, see Section 1.6, “How to Report Bugs or Problems”.
If you encounter corrupted MyISAM
tables or if mysqld always fails after some
update statements, you can test whether the issue is
reproducible by doing the following:
Stop the MySQL daemon with mysqladmin shutdown.
Make a backup of the tables to guard against the very unlikely case that the repair does something bad.
Check all tables with myisamchk -s database/*.MYI. Repair any corrupted tables with myisamchk -r database/
table.MYI.Make a second backup of the tables.
Remove (or move away) any old log files from the MySQL data directory if you need more space.
Start mysqld with the binary log enabled. If you want to find a statement that crashes mysqld, you should start the server with the general query log enabled as well. See Section 5.4.3, “The General Query Log”, and Section 5.4.4, “The Binary Log”.
When you have gotten a crashed table, stop the mysqld server.
Restore the backup.
Restart the mysqld server without the binary log enabled.
Re-execute the statements with mysqlbinlog binary-log-file | mysql. The binary log is saved in the MySQL database directory with the name
hostname-bin..NNNNNNIf the tables are corrupted again or you can get mysqld to die with the above command, you have found a reproducible bug. FTP the tables and the binary log to our bugs database using the instructions given in Section 1.6, “How to Report Bugs or Problems”. If you are a support customer, you can use the MySQL Customer Support Center (https://www.mysql.com/support/) to alert the MySQL team about the problem and have it fixed as soon as possible.
To be able to debug a MySQL client with the integrated debug
package, you should configure MySQL with
-DWITH_DEBUG=1. See
Section 2.9.7, “MySQL Source-Configuration Options”.
Before running a client, you should set the
MYSQL_DEBUG environment variable:
shell>MYSQL_DEBUG=d:t:O,/tmp/client.traceshell>export MYSQL_DEBUG
This causes clients to generate a trace file in
/tmp/client.trace.
If you have problems with your own client code, you should attempt to connect to the server and run your query using a client that is known to work. Do this by running mysql in debugging mode (assuming that you have compiled MySQL with debugging on):
shell> mysql --debug=d:t:O,/tmp/client.trace
This provides useful information in case you mail a bug report. See Section 1.6, “How to Report Bugs or Problems”.
If your client crashes at some 'legal' looking code, you should
check that your mysql.h include file matches
your MySQL library file. A very common mistake is to use an old
mysql.h file from an old MySQL installation
with new MySQL library.
The MySQL server is a multithreaded application that uses numerous internal locking and lock-related primitives, such as mutexes, rwlocks (including prlocks and sxlocks), conditions, and files. Within the server, the set of lock-related objects changes with implementation of new features and code refactoring for performance improvements. As with any multithreaded application that uses locking primitives, there is always a risk of encountering a deadlock during execution when multiple locks are held at once. For MySQL, the effect of a deadlock is catastrophic, causing a complete loss of service.
As of MySQL 8.0.17, to enable detection of lock-acquisition deadlocks and enforcement that runtime execution is free of them, MySQL supports LOCK_ORDER tooling. This enables a lock-order dependency graph to be defined as part of server design, and server runtime checking to ensure that lock acquisition is acyclic and that execution paths comply with the graph.
This section provides information about using the LOCK_ORDER tool, but only at a basic level. For complete details, see the Lock Order section of the MySQL Server Doxygen documentation, available at https://dev.mysql.com/doc/index-other.html.
The LOCK_ORDER tool is intended for debugging the server, not for production use.
To use the LOCK_ORDER tool, follow this procedure:
Build MySQL from source, configuring it with the
-DWITH_LOCK_ORDER=ONCMake option so that the build includes LOCK_ORDER tooling.NoteWith the
WITH_LOCK_ORDERoption enabled, MySQL builds require the flex program.To run the server with the LOCK_ORDER tool enabled, enable the
lock_ordersystem variable at server startup. Several other system variables for LOCK_ORDER configuration are available as well.For MySQL test suite operation, mysql-test-run.pl has a
--lock-orderoption that controls whether to enable the LOCK_ORDER tool during test case execution.
The system variables described following configure operation of
the LOCK_ORDER tool, assuming that MySQL has been built to include
LOCK_ORDER tooling. The primary variable is
lock_order, which indicates
whether to enable the LOCK_ORDER tool at runtime:
If
lock_orderis disabled (the default), no other LOCK_ORDER system variables have any effect.If
lock_orderis enabled, the other system variables configure which LOCK_ORDER features to enable.
In general, it is intended that the LOCK_ORDER tool be
configured by executing mysql-test-run.pl
with the --lock-order option, and for
mysql-test-run.pl to set LOCK_ORDER system
variables to appropriate values.
All LOCK_ORDER system variables must be set at server startup. At runtime, their values are visible but cannot be changed.
Some system variables exist in pairs, such as
lock_order_debug_loop and
lock_order_trace_loop. For such
pairs, the variables are distinguished as follows when the
condition occurs with which they are associated:
If the
_debug_variable is enabled, a debug assertion is raised.If the
_trace_variable is enabled, an error is printed to the logs.
Table 5.7 LOCK_ORDER System Variable Summary
| Variable Name | Variable Type | Variable Scope |
|---|---|---|
| lock_order | Boolean | Global |
| lock_order_debug_loop | Boolean | Global |
| lock_order_debug_missing_arc | Boolean | Global |
| lock_order_debug_missing_key | Boolean | Global |
| lock_order_debug_missing_unlock | Boolean | Global |
| lock_order_dependencies | File name | Global |
| lock_order_extra_dependencies | File name | Global |
| lock_order_output_directory | Directory name | Global |
| lock_order_print_txt | Boolean | Global |
| lock_order_trace_loop | Boolean | Global |
| lock_order_trace_missing_arc | Boolean | Global |
| lock_order_trace_missing_key | Boolean | Global |
| lock_order_trace_missing_unlock | Boolean | Global |
-
Command-Line Format --lock-order[={OFF|ON}]Introduced 8.0.17 System Variable lock_orderScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value OFFWhether to enable the LOCK_ORDER tool at runtime. If
lock_orderis disabled (the default), no other LOCK_ORDER system variables have any effect. Iflock_orderis enabled, the other system variables configure which LOCK_ORDER features to enable.If
lock_orderis enabled, an error is raised if the server encounters a lock-acquisition sequence that is not declared in the lock-order graph. -
Command-Line Format --lock-order-debug-loop[={OFF|ON}]Introduced 8.0.17 System Variable lock_order_debug_loopScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value OFFWhether the LOCK_ORDER tool causes a debug assertion failure when it encounters a dependency that is flagged as a loop in the lock-order graph.
-
Command-Line Format --lock-order-debug-missing-arc[={OFF|ON}]Introduced 8.0.17 System Variable lock_order_debug_missing_arcScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value OFFWhether the LOCK_ORDER tool causes a debug assertion failure when it encounters a dependency that is not declared in the lock-order graph.
-
Command-Line Format --lock-order-debug-missing-key[={OFF|ON}]Introduced 8.0.17 System Variable lock_order_debug_missing_keyScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value OFFWhether the LOCK_ORDER tool causes a debug assertion failure when it encounters an object that is not properly instrumented with the Performance Schema.
lock_order_debug_missing_unlockCommand-Line Format --lock-order-debug-missing-unlock[={OFF|ON}]Introduced 8.0.17 System Variable lock_order_debug_missing_unlockScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value OFFWhether the LOCK_ORDER tool causes a debug assertion failure when it encounters a lock that is destroyed while still held.
-
Command-Line Format --lock-order-dependencies=file_nameIntroduced 8.0.17 System Variable lock_order_dependenciesScope Global Dynamic No SET_VARHint AppliesNo Type File name Default Value empty stringThe path to the
lock_order_dependencies.txtfile that defines the server lock-order dependency graph.It is permitted to specify no dependencies. An empty dependency graph is used in this case.
-
Command-Line Format --lock-order-extra-dependencies=file_nameIntroduced 8.0.17 System Variable lock_order_extra_dependenciesScope Global Dynamic No SET_VARHint AppliesNo Type File name Default Value empty stringThe path to a file containing additional dependencies for the lock-order dependency graph. This is useful to amend the primary server dependency graph, defined in the
lock_order_dependencies.txtfile, with additional dependencies describing the behavior of third party code. (The alternative is to modifylock_order_dependencies.txtitself, which is not encouraged.)If this variable is not set, no secondary file is used.
-
Command-Line Format --lock-order-output-directory=dir_nameIntroduced 8.0.17 System Variable lock_order_output_directoryScope Global Dynamic No SET_VARHint AppliesNo Type Directory name Default Value empty stringThe directory where the LOCK_ORDER tool writes its logs. If this variable is not set, the default is the current directory.
-
Command-Line Format --lock-order-print-txt[={OFF|ON}]Introduced 8.0.17 System Variable lock_order_print_txtScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value OFFWhether the LOCK_ORDER tool performs a lock-order graph analysis and prints a textual report. The report includes any lock-acquisition cycles detected.
-
Command-Line Format --lock-order-trace-loop[={OFF|ON}]Introduced 8.0.17 System Variable lock_order_trace_loopScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value OFFWhether the LOCK_ORDER tool prints a trace in the log file when it encounters a dependency that is flagged as a loop in the lock-order graph.
-
Command-Line Format --lock-order-trace-missing-arc[={OFF|ON}]Introduced 8.0.17 System Variable lock_order_trace_missing_arcScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value ONWhether the LOCK_ORDER tool prints a trace in the log file when it encounters a dependency that is not declared in the lock-order graph.
-
Command-Line Format --lock-order-trace-missing-key[={OFF|ON}]Introduced 8.0.17 System Variable lock_order_trace_missing_keyScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value OFFWhether the LOCK_ORDER tool prints a trace in the log file when it encounters an object that is not properly instrumented with the Performance Schema.
lock_order_trace_missing_unlockCommand-Line Format --lock-order-trace-missing-unlock[={OFF|ON}]Introduced 8.0.17 System Variable lock_order_trace_missing_unlockScope Global Dynamic No SET_VARHint AppliesNo Type Boolean Default Value ONWhether the LOCK_ORDER tool prints a trace in the log file when it encounters a lock that is destroyed while still held.
The MySQL server and most MySQL clients are compiled with the DBUG package originally created by Fred Fish. When you have configured MySQL for debugging, this package makes it possible to get a trace file of what the program is doing. See Section 5.9.1.2, “Creating Trace Files”.
This section summarizes the argument values that you can specify in debug options on the command line for MySQL programs that have been built with debugging support.
The DBUG package can be used by invoking a program with the
--debug[=
or debug_options]-# [
option. If you specify the debug_options]--debug or
-# option without a
debug_options value, most MySQL
programs use a default value. The server default is
d:t:i:o,/tmp/mysqld.trace on Unix and
d:t:i:O,\mysqld.trace on Windows. The effect of
this default is:
d: Enable output for all debug macrost: Trace function calls and exitsi: Add PID to output lineso,/tmp/mysqld.trace,O,\mysqld.trace: Set the debug output file.
Most client programs use a default
debug_options value of
d:t:o,/tmp/,
regardless of platform.
program_name.trace
Here are some example debug control strings as they might be specified on a shell command line:
--debug=d:t --debug=d:f,main,subr1:F:L:t,20 --debug=d,input,output,files:n --debug=d:t:i:O,\\mysqld.trace
For mysqld, it is also possible to change DBUG
settings at runtime by setting the
debug system variable. This
variable has global and session values:
mysql>SET GLOBAL debug = 'mysql>debug_options';SET SESSION debug = 'debug_options';
Changing the global debug value
requires privileges sufficient to set global system variables.
Changing the session debug value
requires privileges sufficient to set restricted session system
variables. See Section 5.1.9.1, “System Variable Privileges”.
The debug_options value is a sequence
of colon-separated fields:
field_1:field_2:...:field_N
Each field within the value consists of a mandatory flag
character, optionally preceded by a + or
- character, and optionally followed by a
comma-separated list of modifiers:
[+|-]flag[,modifier,modifier,...,modifier]
The following table describes the permitted flag characters. Unrecognized flag characters are silently ignored.
Flag |
Description |
|---|---|
|
Enable output from DBUG_
In MySQL, common debug macro keywords to enable are
|
|
Delay after each debugger output line. The argument is the
delay, in tenths of seconds, subject to machine
capabilities. For example, |
|
Limit debugging, tracing, and profiling to the list of
named functions. An empty list enables all functions. The
appropriate |
|
Identify the source file name for each line of debug or trace output. |
|
Identify the process with the PID or thread ID for each line of debug or trace output. |
|
Identify the source file line number for each line of debug or trace output. |
|
Print the current function nesting depth for each line of debug or trace output. |
|
Number each line of debug output. |
|
Redirect the debugger output stream to the specified file.
The default output is |
|
Like |
|
Limit debugger actions to specified processes. A process
must be identified with the
|
|
Print the current process name for each line of debug or trace output. |
|
When pushing a new state, do not inherit the previous state's function nesting level. Useful when the output is to start at the left margin. |
|
Do function |
|
Enable function call/exit trace lines. May be followed by a list (containing only one modifier) giving a numeric maximum trace level, beyond which no output occurs for either debugging or tracing macros. The default is a compile time option. |
The leading + or - character
and trailing list of modifiers are used for flag characters such
as d or f that can enable a
debug operation for all applicable modifiers or just some of them:
With no leading
+or-, the flag value is set to exactly the modifier list as given.With a leading
+or-, the modifiers in the list are added to or subtracted from the current modifier list.
The following examples show how this works for the
d flag. An empty d list
enabled output for all debug macros. A nonempty list enables
output only for the macro keywords in the list.
These statements set the d value to the
modifier list as given:
mysql>SET debug = 'd';mysql>SELECT @@debug;+---------+ | @@debug | +---------+ | d | +---------+ mysql>SET debug = 'd,error,warning';mysql>SELECT @@debug;+-----------------+ | @@debug | +-----------------+ | d,error,warning | +-----------------+
A leading + or - adds to or
subtracts from the current d value:
mysql>SET debug = '+d,loop';mysql>SELECT @@debug;+----------------------+ | @@debug | +----------------------+ | d,error,warning,loop | +----------------------+ mysql>SET debug = '-d,error,loop';mysql>SELECT @@debug;+-----------+ | @@debug | +-----------+ | d,warning | +-----------+
Adding to “all macros enabled” results in no change:
mysql>SET debug = 'd';mysql>SELECT @@debug;+---------+ | @@debug | +---------+ | d | +---------+ mysql>SET debug = '+d,loop';mysql>SELECT @@debug;+---------+ | @@debug | +---------+ | d | +---------+
Disabling all enabled macros disables the d
flag entirely:
mysql>SET debug = 'd,error,loop';mysql>SELECT @@debug;+--------------+ | @@debug | +--------------+ | d,error,loop | +--------------+ mysql>SET debug = '-d,error,loop';mysql>SELECT @@debug;+---------+ | @@debug | +---------+ | | +---------+